目录
Cross-iteration BatchNorm(CBN)
Batch Group Normalization(BGN)
Filter Response Normalization(FRN)
Sandwich Batch Normalization(SaBN)
概要
训练深度网络时,神经网络隐层参数更新会导致网络输出层输出数据的分布发生变化,而且随着层数的增加,根据链式规则,这种偏移现象会逐渐被放大。这对于网络参数学习来说是个问题:因为神经网络本质学习的就是数据分布(representation learning),如果数据分布变化了,神经网络又不得不学习新的分布。为保证网络参数训练的稳定性和收敛性,往往需要选择比较小的学习速率(learning rate),同时参数初始化的好坏也明显影响训练出的模型精度,特别是在训练具有饱和非线性(死区特性)的网络。当然,如果我们只是对输入的数据进行归一化处理(比如将输入的图像除以255,将其归到0到1之间),只能保证输入层数据分布是一样的,并不能保证每层网络输入数据分布是一样的,所以也需要在神经网络的中间层加入归一化处理。
本文主要总结分析常见的几种归一化方式以及目前最新提出的几种归一化方法。主要包括 Batch Normalization(BN)、 Instance Normalization(IN)、Layer Normalizaiton(LN)、Group Normalization(GN)、Switchable Normalization(SN)、Positional Normalization(PN)、Cross-iterationBatchNorm(CBN)、Batch Group Normalization(BGN)、Filter Response Normalization(FRN)和Sandwich Batch Normalization(SaBN)。
| 归一化方法(年份) |
优点 |
缺点 |
| BN(2015) |
计算机视觉任务 |
小Batch效果差 |
| IN(2016 |
适用图像风格迁移 |
不适应通道之间的相关性较强数据 |
| LN(2016) |
适用序列模型 |
不适应输入变化很大的数据,大Batch较差 |
| GN(2018) |
不同Batch Size下具有较大的稳定性 |
在大Batch 下性能略差于BN |
| SN(2018) |
集BN、IN、LN优点于一身 |
训练复杂 |
| PN(2019) |
在生成网络中表现较好 |
不适应视觉任务 |
| CBN(2020) |
目标检测任务 |
训练慢 |
| BGN(2020) |
解决Batch Size退化和饱和的问题 |
暂不清楚 |
| FRN(2020) |
不受batch size的影响。 |
暂不清楚 |
| SaBN(2021) |
解决多类别不平衡问题 |
小批量它的性能会下降 |

Batch Normalization(BN)
2015年Google提出了Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
(1)提出BN的原因
A.解决Internal Covariate Shift问题:训练深层网络时,层内神经元间、层间神经元间激活值的量级差别较大,不满足iit独立同分布时,模型不稳定不容易收敛(直观来看解决方案要么自适应地调节每一层甚至每一个神经元的学习率,要么把神经元激活值规范化一下)。
B.缓解过拟合:深层网络容易过拟合,有时候dropout可能也解决不了。
(2)BN的原理
批规范化(Batch Normalization,BN)是在minibatch维度上在每次训练iteration时对隐藏层进行归一化,通过参数在量级和尺度上做约束,缓和过拟合情况。BN的思想就是将激活前隐层的值x变为BN(x),x减去均值除以标准差,这样隐层状态不再发散,之后的激活值也更规范,但有时候处理完之后的分布不一定是我们想要的(这样的规范反而会使网络表达能力下降),所以乘上缩放系数γ,加上偏移β。

(3)BN优点
A.不仅仅极大提升了训练速度,收敛过程大大加快;
B.还能增加分类效果,一种解释是这是类似于Dropout的一种防止过拟合的正则化表达方式,所以不用Dropout也能达到相当的效果;
C.另外调参过程也简单多了,对于初始化要求没那么高,而且可以使用大的学习率等。总而言之,经过这么简单的变换,带来的好处多得很,这也是为何现在BN这么快流行起来的原因。
(4)BN缺点
BN的一个问题是训练时batch size一般较大,但是测试时batch size一般为1,而均值和方差的计算依赖batch,这将导致训练和测试不一致。BN的解决方案是在训练时估计一个均值和方差量来作为测试时的归一化参数,一般对每次mini-batch的均值和方差进行指数加权平均来得到这个量。虽然解决了训练和测试的不一致性,但是BN对于batch size比较敏感,当batch size较小时,模型性能会明显恶化。对于一个比较大的模型,由于显存限制,batch size难以很大,比如目标检测模型,这时候BN层可能会成为一种限制。
Instance Normalization(IN)
2017年牛津提出了 Instance Normalization: The Missing Ingredient for Fast Stylization
(1)提出IN的原因
BN注重对batchsize数据归一化,但是在图像风格化任务中,生成的风格结果主要依赖于某个图像实例,所以对整个batchsize数据进行归一化是不合适的,因而提出了IN只对HW维度进行归一化。
(2)IN原理
IN保留了N、C的维度,只在Channel内部对于H和W进行求均值和标准差的操作。
(3)IN优点
IN适用于生成模型中,比如图片风格迁移。因为图片生成的结果主要依赖于某个图像实例,所以对整个Batch进行Normalization操作并不适合图像风格化的任务,在风格迁移中适用IN不仅可以加速模型收敛,并且可以保持每个图像实例之间的独立性。IN的计算就是把每个HW单独拿出来归一化处理,不受通道和batchsize 的影响
(4)IN缺点
如果特征图可以用到通道之间的相关性,那么就不建议使用它做归一化处理
Layer Normalizaiton(LN)
2016年多伦多大学提出Layer Normalization
(1)提出LN的原因
前面介绍了Batch Normalization的原理,我们知道,BN层在CNN中可以加速模型的训练,并防止模型过拟合和梯度消失。但是,如果将BN层直接应用在RNN中可不可行呢,原则上也是可以的,但是会出现一些问题,因为我们知道Batch Normalization是基于mini batch进行标准化,在文本中,不同的样本其长度往往是不一样的,因此,如果在每一个时间步也采用Batch Normalization时,则在不同的时间步其规范化会强行对每个文本都执行,因此,这是不大合理的,另外,在测试时,如果一个测试文本比训练时的文本长度长时,此时Batch Normalization也会出现问题。因此,在RNN中,我们一般比较少使用Batch Normalization,但是我们会使用一种非常类似的做法,即Layer Normalization。
(2)LN原理
Layer Normalization的思想与Batch Normalization非常类似,只是Batch Normalization是在每个神经元对一个mini batch大小的样本进行规范化,而Layer Normalization则是在每一层对单个样本的所有神经元节点进行规范化,即C,W,H维度求均值方差进行规范化(当前层一共会求batchsize个均值和方差,每个batchsize分别规范化。
(3)LN优点
在RNN中,使用Layer Normalization的效果要比Batch Normalization更优,可以更快、更好地达到最优效果。LN 不需要保存 mini-batch 的均值和方差,节省了额外的存储空间。
(4)LN缺点
LN与batchsize无关,在小batchsize上效果可能会比BN好,但是大batchsize的话还是BN效果好。LN 对于一整层的神经元训练得到同一个转换——所有的输入都在同一个区间范围内。如果不同输入特征不属于相似的类别(比如颜色和大小),那么 LN 的处理可能会降低模型的表达能力。
Group Normalizaiton(GN)
2018年何恺明提出 Group Normalization
(1)提出GN的原因
众所周知,BN是深度学习中常使用的归一化方法,在提升训练以及收敛速度上发挥了重大的作用,是深度学习上里程碑式的工作,但是其仍然存在一些问题,而新提出的GN解决了BN式归一化对batch size依赖的影响。LN虽然不依赖batchsize,但是在CNN中直接对当前层所有通道数据进行规范化也不太好。
(2)GN原理
GN介于LN和IN之间,其首先将channel分为许多组(group),对每一组做归一化,及先将feature的维度由[N, C, H, W]reshape为[N, G,C//G , H, W],归一化的维度为[C//G , H, W]。事实上,GN的极端情况就是LN和I N,分别对应G等于C和G等于1。

(3)GN优点
GN能有不依赖Batch Size,同时还带来依然令人惊奇的效果。GN是在channel维度上进行的norm,可以很好适用于RNN,这是GN的巨大优势。虽然文中没做关于RNN的实验,但这无疑提供了一条新思路。
(4)GN缺点
GN对比的BN并不是BN最强的状态。旷视科技提出的MegDet用了一种超大的batch size=256,激发的BN效果比batch_size=32的时候好很多,并且顺便拿下COCO2017检测的冠军。
Switchable Normalization
2018年香港中文大学提出 Differentiable Learning-to-Normalize via Switchable Normalization
(1)提出SN的原因
A.归一化虽然提高模型泛化能力,然而归一化层的操作是人工设计的。在实际应用中,解决不同的问题原则上需要设计不同的归一化操作,并没有一个通用的归一化方法能够解决所有应用问题;
B.一个深度神经网络往往包含几十个归一化层,通常这些归一化层都使用同样的归一化操作,因为手工为每一个归一化层设计操作需要进行大量的实验。
(2)SN的原理
本质是将 BN、LN、IN 结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。
(3)SN的优点
SN是一种覆盖特征图张量各个维度来计算统计信息的归一化方法,不依赖minibatch size的同时对各个维度统计有很好的鲁棒性。 SN是一种能够有效适应不同任务地归一化方式。因此它同样适用于图像风格迁移、RNN、对抗生成网路。
(4)SN的缺点
集万千宠爱于一身,但训练复杂。
Positional Normalization(PN)
2019年麻省理工提出Positional Normalization
(1)提出PN的原因
作者提出,当前的BatchNorm, GroupNorm, InstanceNorm在空间层面归一化信息,同时丢弃了统计值。作者认为这些统计信息中包含重要的信息,如果有效利用,可以提高GAN和分类网络的性能。
(2)PN原理
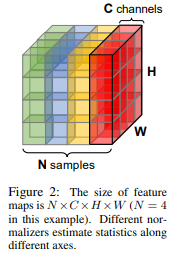
提出一种与众不同的跨通道的规范化方法 Positional Normalization (PONO), 正如上面图中所示, 提取到的均值和标准差能够捕获粗糙的结构信息。在生成模型的情况下, 这些信息必须在解码器中重新学习. 相反, 建议直接将这两个矩信息 (均值和标准差) 注入到网络的后续层中, 作者称之为矩捷径 (Moment Shortcut, MS) 连接。根据不同的规范化方案, 计算出其对应的 μ 和 σ, 对X进行标准化, 然后再应用仿射变换(其参数为 γ , β ) 得到后规范化 (post-normalized) 特征。 仿射变换的目的是保证每一次数据经过标准化后还保留原有学习来的特征, 同时又能完成规范化操作, 加速训练, 并且这两个参数也是需要学习的。
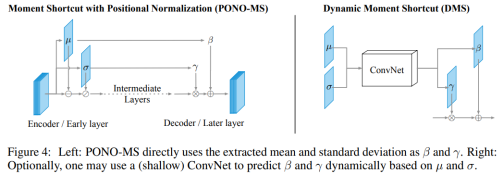
(3)PN优点
用于数据增强,生成网络(GAN,图像去雾等),语义分割,图像分类等应用当中。
(4)PN缺点
在视觉任务中表现较差
Cross-iteration BatchNorm(CBN)
2020年清华&微软亚洲研究院提出了Cross-Iteration Batch Normalization
(1)提出CBN的原因
随着BN的提出,现有的网络基本都在使用。但是在显存有限或者某些任务不允许大batch(比如检测或者分割任务相比分类任务训练时的batchsize一般会小很多)的情况下,BN效果就会差很多。为了改善小batch情况下网络性能下降的问题,有各种新的normalize方法被提出来了(LN、IN、GN),详情请看文章GN-Group Normalization。上述不同的normalize方式适用于不同的任务,其中GN就是为检测任务设计的,但是它会降低推断时的速度。
(2)CBN原理
其思想其实很简单,既然从空间维度不好做,那么就从时间维度进行,通过以前算好的BN参数用来计算更新新的BN参数,从而改善网络性能,由于梯度迭代的属性,网络权重在一轮轮的迭代过程中缓慢改变,所以根据泰勒展开式可以估计出BN参数。
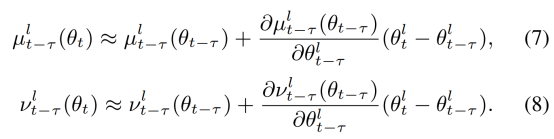

(3)CBN优点
CBN在计算当前时刻统计量时候会考虑前k个时刻统计量,从而实现扩大batch size操作。同时作者指出CBN操作不会引入比较大的内存开销。目前广泛用于目标检测中效果较好,如yolov4。
(4)CBN缺点
模型训练的时候会慢一些,比GN还慢。
Batch Group Normalization(BGN)
2020年上海交大&帝国理工提出了Batch Group Normalization
(1)提出BGN的原因
深度学习网络中,BN在大、中批处理中表现良好,对多个视觉任务具有很好的通用性,但在小批量处理中,其性能下降明显。作者通过实验发现超大的Batch下BN会出现饱和状态。
(2)BGN原理
作者认为BN的退化/饱和是由于噪声/混淆的统计计算引起的。因此,在不增加新训练参数和引入额外的计算情况下,通过引入通道、高度和宽度维度来补偿,解决了批量标准化(BGN)在小/超大Batch下BN的噪声/混淆统计计算问题。
BGN将通道通道、高度和宽度维度重新组合为一个维度,然后于batch维度重组特征组,计算各个特征组的均值和方差统计量,利用计算出的特征统计量对各特征组进行归一化,最后对归一化特征图进行重新缩放和位移,保持原来的特征形式。
(3)BGN优点
解决Batch Size退化和饱和的问题。
(4)BGN缺点
暂不清楚
Filter Response Normalization(FRN)
2020年谷歌提出 Filter Response Normalization Layer: Eliminating Batch
(1)提出FRN的原因
目前主流的深度学习模型都会采用BN层(Batch Normalization)来加速模型训练以及提升模型效果,对于CNN模型,BN层已经上成为了标配。但是BN层在训练过程中需要在batch上计算中间统计量,这使得BN层严重依赖batch,造成训练和测试的不一致性,当训练batch size较小,往往会恶化性能。GN(Group Normalization)通过将特征在channel维度分组来解决这一问题,GN在batch size不同时性能是一致的,但对于大batch size,GN仍然难以匹敌BN。
(2)FRN原理
FRN旨在于消除batch_size对于归一化的影响,但是不能牺牲BN在大的batch_size上所获得性能。谷歌的提出的FRN层包括归一化层FRN(Filter Response Normalization)和激活层TLU(Thresholded Linear Unit),如下图所示。FRN层不仅消除了模型训练过程中对batch的依赖,而且当batch size较大时性能优于BN。

其中FRN的操作是(H, W)维度上的,即对每个样例的每个channel单独进行归一化,这里 x 就是一个N维度(HxW)的向量,所以FRN没有BN层对batch依赖的问题。BN层采用归一化方法是减去均值然后除以标准差,而FRN却不同,这里没有减去均值操作,公式中的 是x 的二次范数的平均值。这种归一化方式类似BN可以用来消除中间操作(卷积和非线性激活)带来的尺度问题,有助于模型训练。 公式里的epsilon是一个很小的正常量,以防止除0。
归一化之后同样需要进行缩放和平移变换,这里的gama和beta也是可学习的参数(参数大小为C)。FRN缺少去均值的操作,这可能使得归一化的结果任意地偏移0,如果FRN之后是ReLU激活层,可能产生很多0值,这对于模型训练和性能是不利的。为了解决这个问题,FRN之后采用的阈值化的ReLU,即TLU:
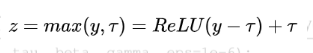
这里的tau是一个可学习的参数。论文中发现FRN之后采用TLU对于提升性能是至关重要的。

(4)FRN优点
可以将TLU模型任意插入到其他归一化方法当中,且效果有明显的提升。不受batch size的影响。
(4)FRN缺点
暂不清楚
Sandwich Batch Normalization(SaBN)
2021年德克萨斯大学提出 Sandwich Batch Normalization
(1)提出SaBN的原因
A.一个 batch 里面不同类别的训练数据,放在一起做 Batch Normalization 不太妥当。因为不同类别的数据理应对应不同的均值和方差,其归一化、放缩、偏置也应该不同。
B.由于训练数据的每个类别变化很大,若单独/拆分特征层,会导致训练不平衡。降低收敛速度,阻碍整个网络训练。
(2)SaBN的原理
在BN的基础上加入分类的条件信息。对BN后的每个特征层通过多层感知机进行放射变换。其变换因子是由输入特征决定的,不同BN学习到的。


其它方法:
总结
BN通常可以在中、大批量中取得良好的性能。然而在小批量他的性能会下降比较多;GN在不同Batch Size下具有较大的稳定性,而GN在中、大Batch Size下性能略差于BN。IN、LN、PN、CBN在特定任务中表现良好,例如:IN在图像风格迁移中表现较好,LN在RNN中表现较好,PN在生成网络中表现较好,CBN在目标检测任务中较好,但这几个在其他视觉任务中泛化性能较差。SN集万千宠爱为一身,但训练过于复杂。FRN和BGN比其他归一化方法占据明显优势,但是目前还没大范围采用。
声明:本内容来源网络,版权属于原作者,图片来源原论文。如有侵权,联系删除。