这里写目录标题
单体架构
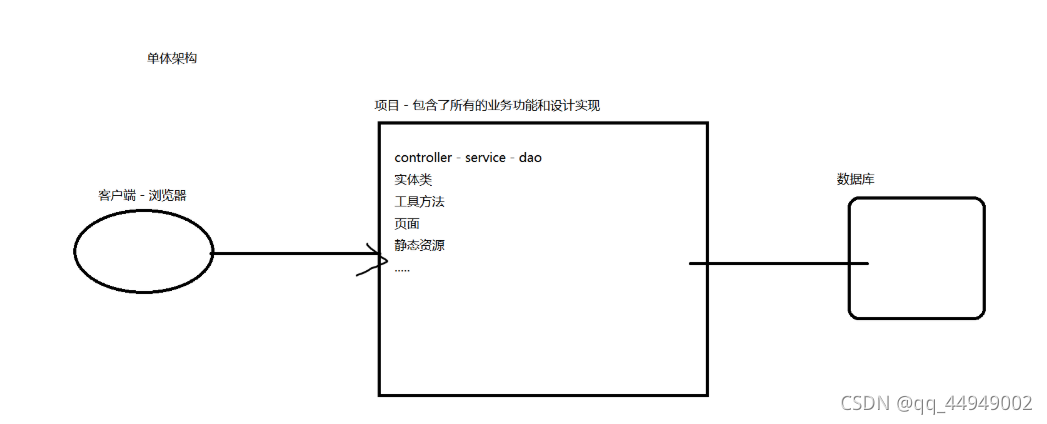
单体架构存在的问题:
1、并发量的问题
2、隔离性差:所有的业务共享资源,一旦某个业务出现问题,可能会连带其他的业务不可用
3.协同效率低:所有业务一起上,如果出问题了就回滚,解决完,在上一次
优点:
1、开发成本低 性能高(没有通信,不走网络)
2、运维成本低(这个不像微服务架构一样模块会调模块,当运维发现这个模块出了问题,就有可能是调了其他模块)
单体集群架构
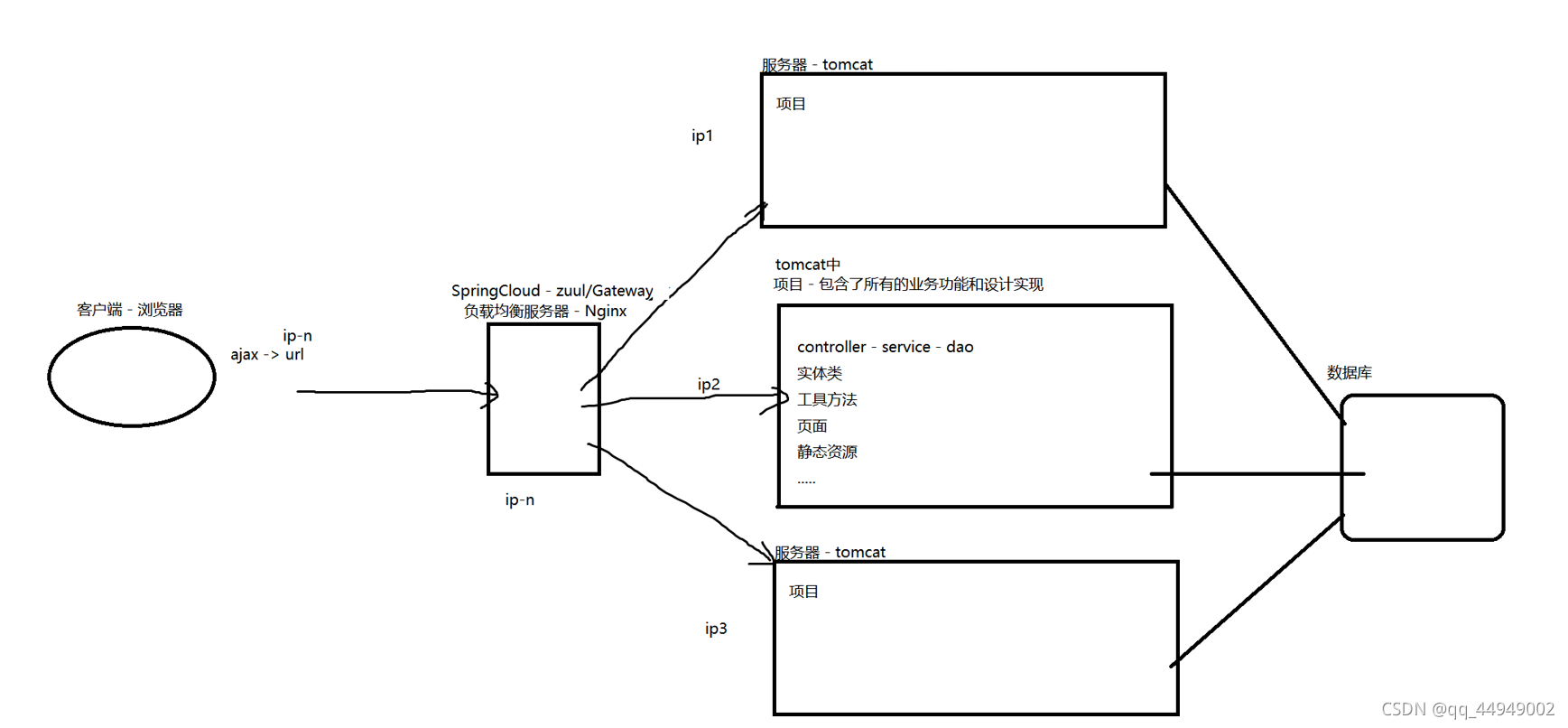
集群的问题:
1、可以局部的解决并发量的问题,但是并不完美
2、资源隔离的问题仍然存在
网关层
集群之后涉及到网关接收客户端请求,向下游业务逻辑层发起调用,并将请求处理结果返回给客户端
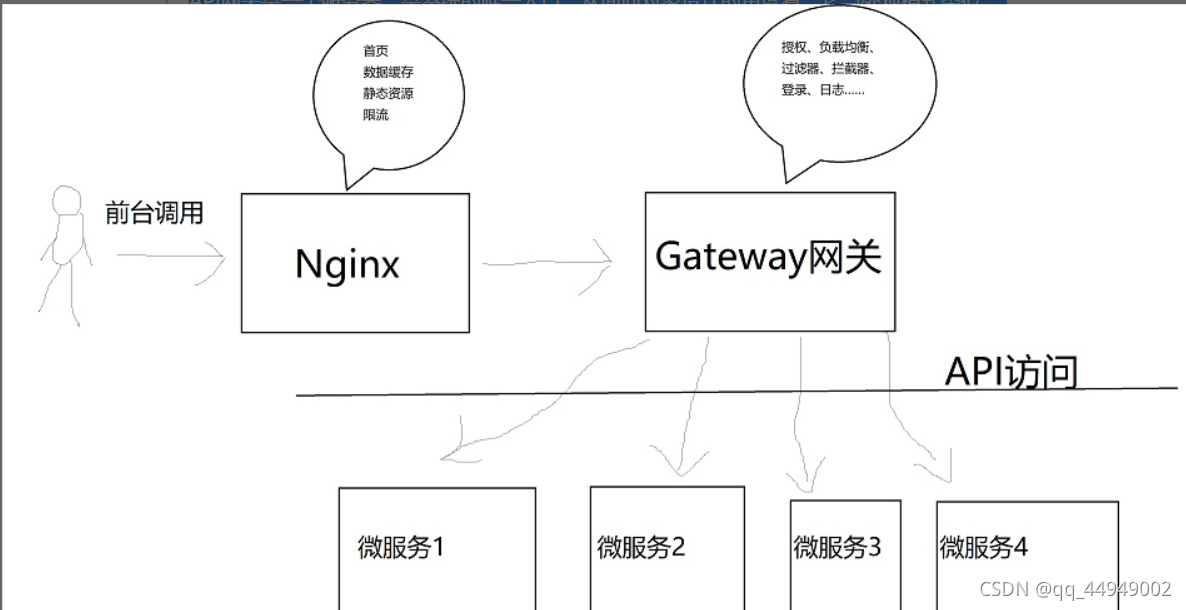
问题: 为什么有了Nginx还需要Gateway?
—— nginx和Spring Cloud Gateway其实有许多功能重叠的地方,例如:限流、服务转发、数据缓存等,那为什么还要使用gateway来做网关呢?答案其实很简单:专人专职。其实,网关在大型微服务系统中是一个很重要的角色:
API网关是一个服务器,是系统的唯一入口。从面向对象设计的角度看,它与外观模式类似。API网关封装了系统内部架构,为每个客户端提供一个定制的API。
它可能还具有其它职责,如身份验证、监控、负载均衡、缓存、请求分片与管理、静态响应处理。
API网关方式的核心要点是,所有的客户端和消费端都通过统一的网关接入微服务,在网关层处理所有的非业务功能。通常,网关也是提供REST/HTTP的访问API。扫描二维码关注公众号,回复: 13493251 查看本文章
而nginx只能实现一些上面所说的一部分功能,所以一般都是选择nginx做静态资源缓存和首页web服务器,在基于Nginx的首页高可用方案这篇文章中有详细描述,典型的架构图如下
动态路由
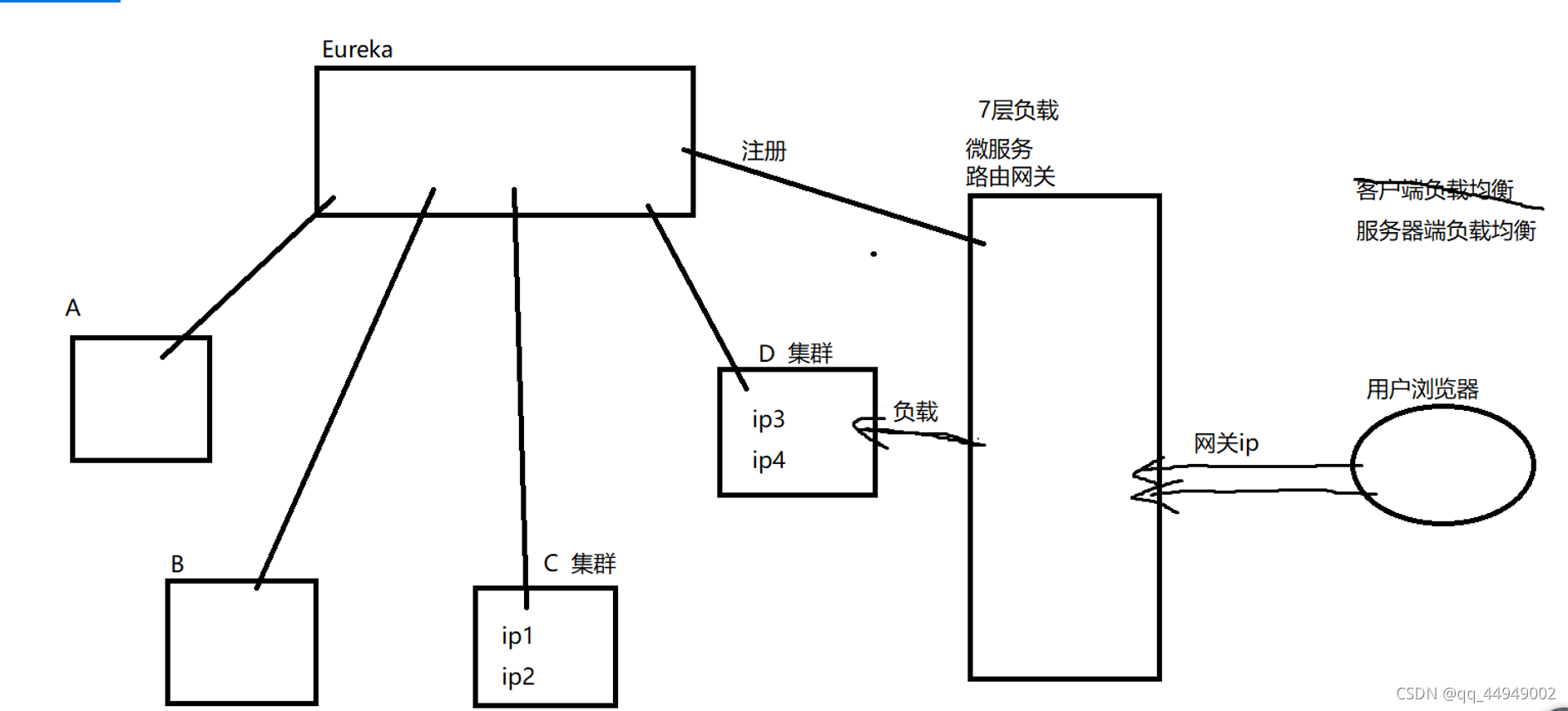
路由网关提供了外部请求的访问入口,所有的外部请求都只需要知道路由网关的地址就行了,无需知道每个微服务的访问地址,路由网关可以将外部的请求负载分发给不同的微服务,这样可以对外屏蔽微服务架构内部的结构。因为路由网关往往是外部请求访问微服务架构的入口,所以可以在路由网关做请求过滤的工作。
SpringCloud默认提供了2个路由网关,Zuul和Gateway,Zuul是网飞(netflix)提供的路由组件,而Gateway是SpringCloud团队自己开发的一款路由组件,用来替换Zuul的
spring:
application:
name: cloud-gateway
cloud:
gateway:
discovery:
locator:
enabled: true #开启从注册中心动态创建路由的功能,利用微服务名进行路由
routes:
- id: payment_routh #payment_routh #路由的ID,没有固定规则但要求唯一,简易配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-provider-service #匹配后提供服务的路由地址,lb后跟提供服务的微服务的名,不要写错
predicates:
- Path=/payment/get/** #断言,路径相匹配的进行路由
- id: payment_routh2 #payment_routh #路由的ID,没有固定规则但要求唯一,简易配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-provider-service #匹配后提供服务的路由地址,lb后跟提供服务的微服务的名,不要写错
predicates:
- Path=/payment/lb/** #断言,路径相匹配的进行路由
请求鉴权
1.身份鉴权
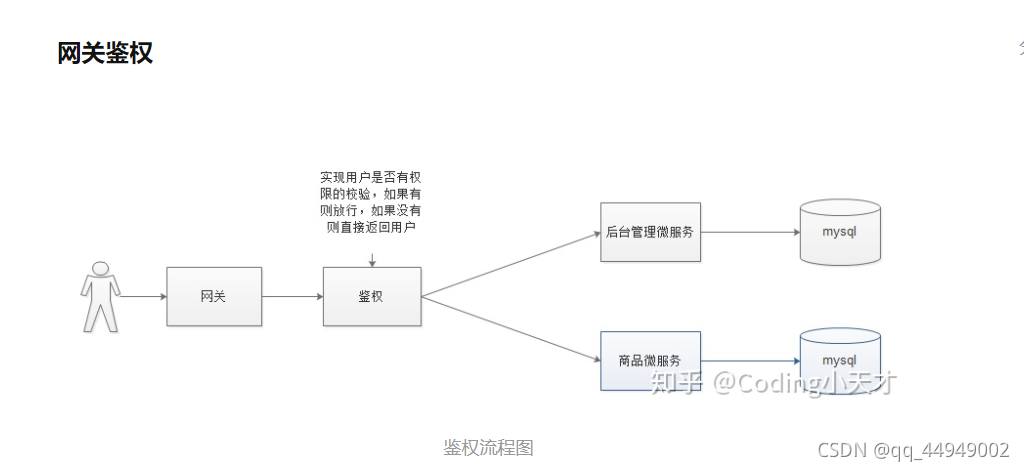
由于在网关鉴权中会使用到JWT令牌
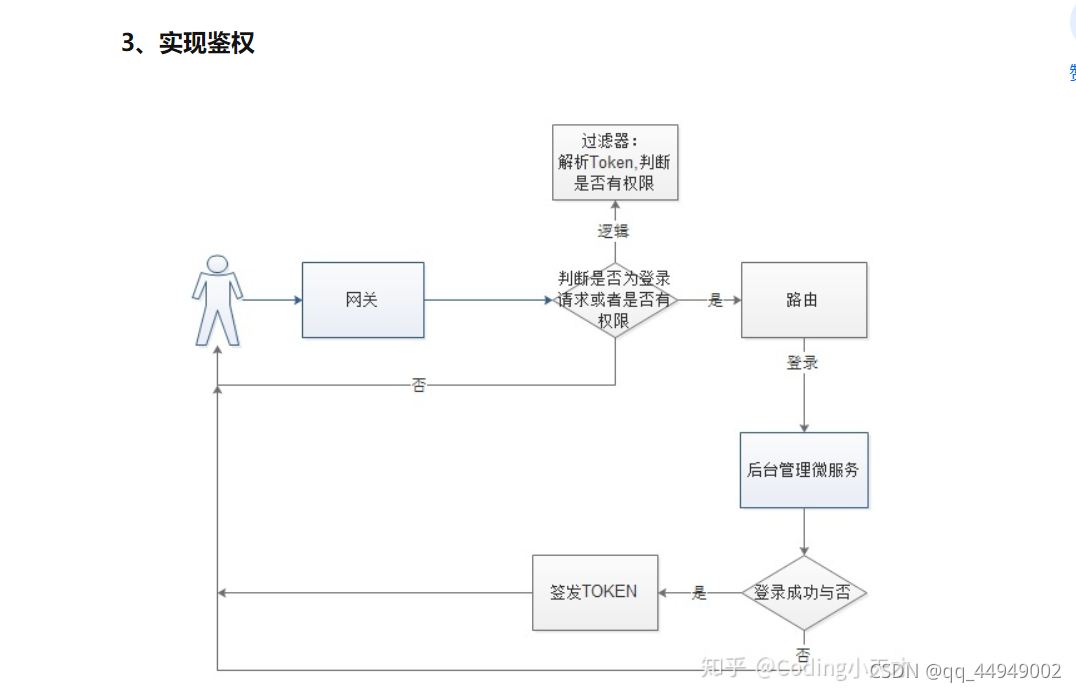
2、数据检查
请求转发
是为了统一程序入口,通过一个端口,可以访问所有的服务,方便后续的鉴权、授权等功能。
package cn.seaboot.gateway;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.gateway.route.RouteLocator;
import org.springframework.cloud.gateway.route.builder.RouteLocatorBuilder;
import org.springframework.context.annotation.Bean;
/**
* @author Mr.css
*/
@SpringBootApplication
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
@Bean
public RouteLocator myRoutes(RouteLocatorBuilder builder) {
//常见的demo,拦截get请求,往请求头添加一个参数,然后转到http://httpbin.org:80
return builder.routes()
.route(p -> p
.path("/get")
.filters(f -> f.addRequestHeader("Hello", "World"))
.uri("http://httpbin.org:80"))
.build();
// return builder.routes()
// .route(p -> p
// .path("/get")
// .filters(f -> f.addRequestHeader("Hello", "World"))
// .uri("http://httpbin.org:80"))
// .build();
}
}
协议转换
协议转换是为了后端有很多服务提供了不同的方式,包括dubbo 协议,和dubbo 上提供的各种访问协议等(dubbo服务上协议的支持)
package com.neo.config;
import com.alibaba.fastjson.JSONObject;
import io.netty.buffer.UnpooledByteBufAllocator;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.cloud.gateway.filter.headers.HttpHeadersFilter;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.Ordered;
import org.springframework.core.io.buffer.DataBuffer;
import org.springframework.core.io.buffer.DataBufferUtils;
import org.springframework.core.io.buffer.NettyDataBufferFactory;
import org.springframework.http.HttpStatus;
import org.springframework.http.server.reactive.ServerHttpResponse;
import org.springframework.util.StringUtils;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import java.io.UnsupportedEncodingException;
import java.lang.reflect.Method;
import java.net.URI;
import java.util.List;
import java.util.concurrent.atomic.AtomicReference;
import static org.springframework.cloud.gateway.support.ServerWebExchangeUtils.*;
/**
* @ClassName DubboResponseGlobalFilter
* @Desription 协议转换的过滤器类
* @Author zhangzexu
* @Date 2019/11/28 17:14
* @Version V1.0
*/
@Configuration
public class DubboResponseGlobalFilter implements GlobalFilter, Ordered {
@Value("${plugin.calssName}")
private String className;
private static Logger LOGGER = LoggerFactory.getLogger(DubboResponseGlobalFilter.class);
private volatile List<HttpHeadersFilter> headersFilters;
@Override
public int getOrder() {
return Ordered.LOWEST_PRECEDENCE;
}
public DubboResponseGlobalFilter() {
}
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
URI requestUrl = exchange.getRequiredAttribute(GATEWAY_REQUEST_URL_ATTR);
final String scheme = requestUrl.getScheme();
if (isAlreadyRouted(exchange) || "http".equals(scheme) || "https".equals(scheme) || "lb".equals(scheme) || "ws".equals(scheme)) {
return chain.filter(exchange);
}
LOGGER.info("请求的url为{},协议为{}",requestUrl,scheme);
setAlreadyRouted(exchange);
/**
* 获取请求的url 对路径进行重新编码
*/
final String url = requestUrl.toASCIIString();
Flux<DataBuffer> flux = exchange.getRequest().getBody();
AtomicReference<byte[]> atomicReference = new AtomicReference<>();
/**
* 获取客户端请求的数据,body体
*/
flux.subscribe(buffer -> {
byte[] bytes = new byte[buffer.readableByteCount()];
buffer.read(bytes);
DataBufferUtils.release(buffer);
atomicReference.set(bytes);
});
return chain.filter(exchange)
.then(Mono.defer(() -> {
ServerHttpResponse response = exchange.getResponse();
return response.writeWith(Flux.create(sink -> {
NettyDataBufferFactory nettyDataBufferFactory = new NettyDataBufferFactory(new UnpooledByteBufAllocator(false));
JSONObject json = new JSONObject();
Class c = null;
DataBuffer dataBuffer = null;
String charset = "UTF-8";
try {
/**
* 初始化反射数据,将要调用的类反射获取,反射的类的名称结构,
* 用 dubbo 协议举例
* 则插件的类名组合为 DubboGatewayImpl
*/
StringBuilder sb = new StringBuilder(className);
sb.append(".");
char[] name = scheme.toCharArray();
name[0] -= 32;
sb.append(String.valueOf(name));
sb.append("GatewayPluginImpl");
c = Class.forName(sb.toString());
c.getMethods();
Method method = c.getMethod("send", String.class, byte[].class);
Object obj = c.getConstructor().newInstance();
Object result = method.invoke(obj, url, atomicReference.get());
HttpStatus status = HttpStatus.resolve(500);
/**
* 判断结果是否返回,如果没有数据则直接返回
*/
if (result == null) {
} else {
json = (JSONObject) result;
status = HttpStatus.resolve(json.getInteger("code"));
json.remove("code");
/**
* 获取字符集编码格式 默认 utf-8
*/
if (!StringUtils.isEmpty(json.getString("charset"))) {
charset = json.getString("charset");
}
}
response.setStatusCode(status);
try {
dataBuffer = nettyDataBufferFactory.wrap(json.toJSONString().getBytes(charset));
} catch (UnsupportedEncodingException e) {
dataBuffer = nettyDataBufferFactory.wrap(e.toString().getBytes(charset));
LOGGER.error("返回调用请求数据错误{}",e);
e.printStackTrace();
}
} catch (Exception e) {
try {
dataBuffer = nettyDataBufferFactory.wrap(e.toString().getBytes(charset));
LOGGER.error("获取远程数据错误{}",e);
} catch (UnsupportedEncodingException ex) {
ex.printStackTrace();
LOGGER.error("返回调用请求数据错误{}",ex);
}
e.printStackTrace();
}
/**
* 将数据进行发射到下一个过滤器
*/
sink.next(dataBuffer);
sink.complete();
}));
}));
}
过滤器链
限流的实现方案
请求计数限流
漏桶算法限流
令牌桶算法限流
业务逻辑层
1、接收网关层请求
2、业务逻辑处理
3、向数据访问层发起调用
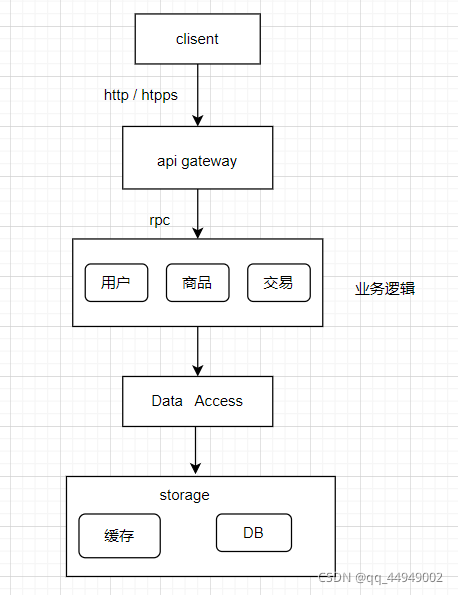
数据访问层
1、屏蔽数据访问逻辑
2、屏蔽存储系统差异
3、屏蔽分库分表逻辑
4、屏蔽缓存逻辑
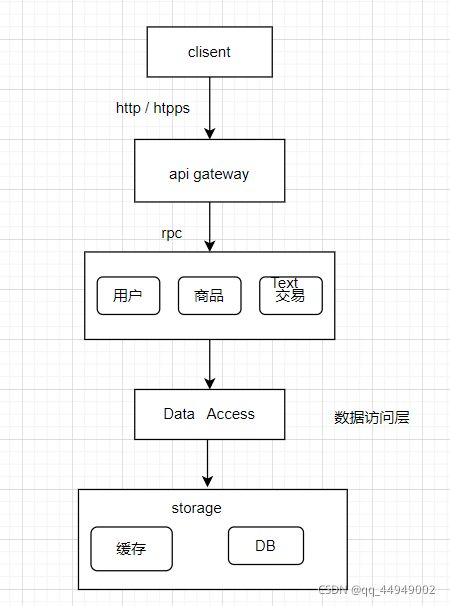
分布式集群架构
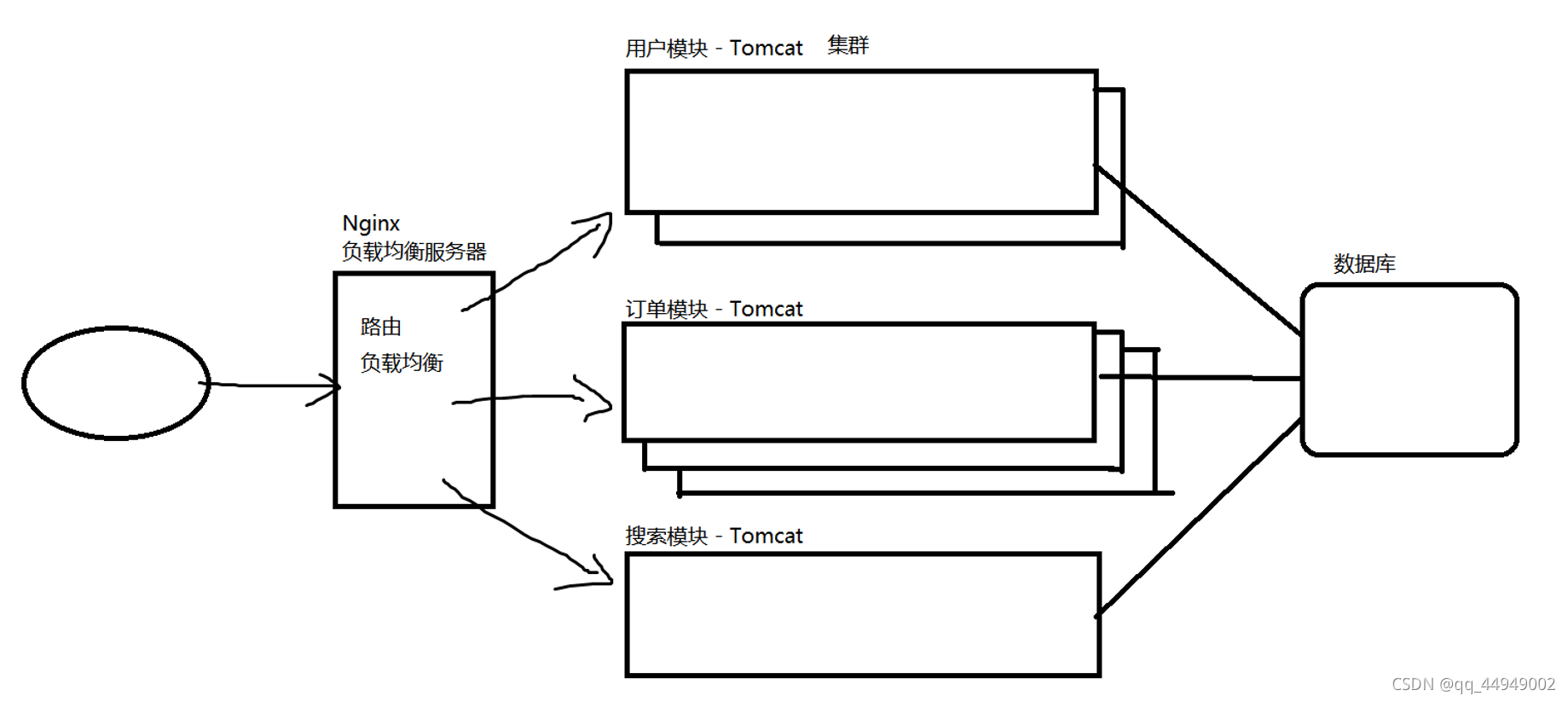
优势:
1、业务隔离:按照模块进行拆分,分布到不同的机器上,处理不同的业务,这样如果某个业务有问题,不会影响其他业务的正常工作。
2、可以很灵活的根据业务的并发大小,弹性的调整每个业务的集群规模
3.迭代快 稳定性高 故障范围小 易扩展(比如单体的要扩展服务,他是扩展整体的,分布式就是扩展自己想要的模块)
问题:
1、模块和模块之间完全没有联系吗?- 不是,实际开发过程中,往往很多模块之间是需要互相依赖和调用的,这里就牵扯了服务间的互调(Http协议)
2、开发成本高(调各种基础组件) 基础设施依赖高 维护复杂(服务节点变多,排查路线边长) 响应慢
微服务架构体系(Dubbo、SpringCloud)
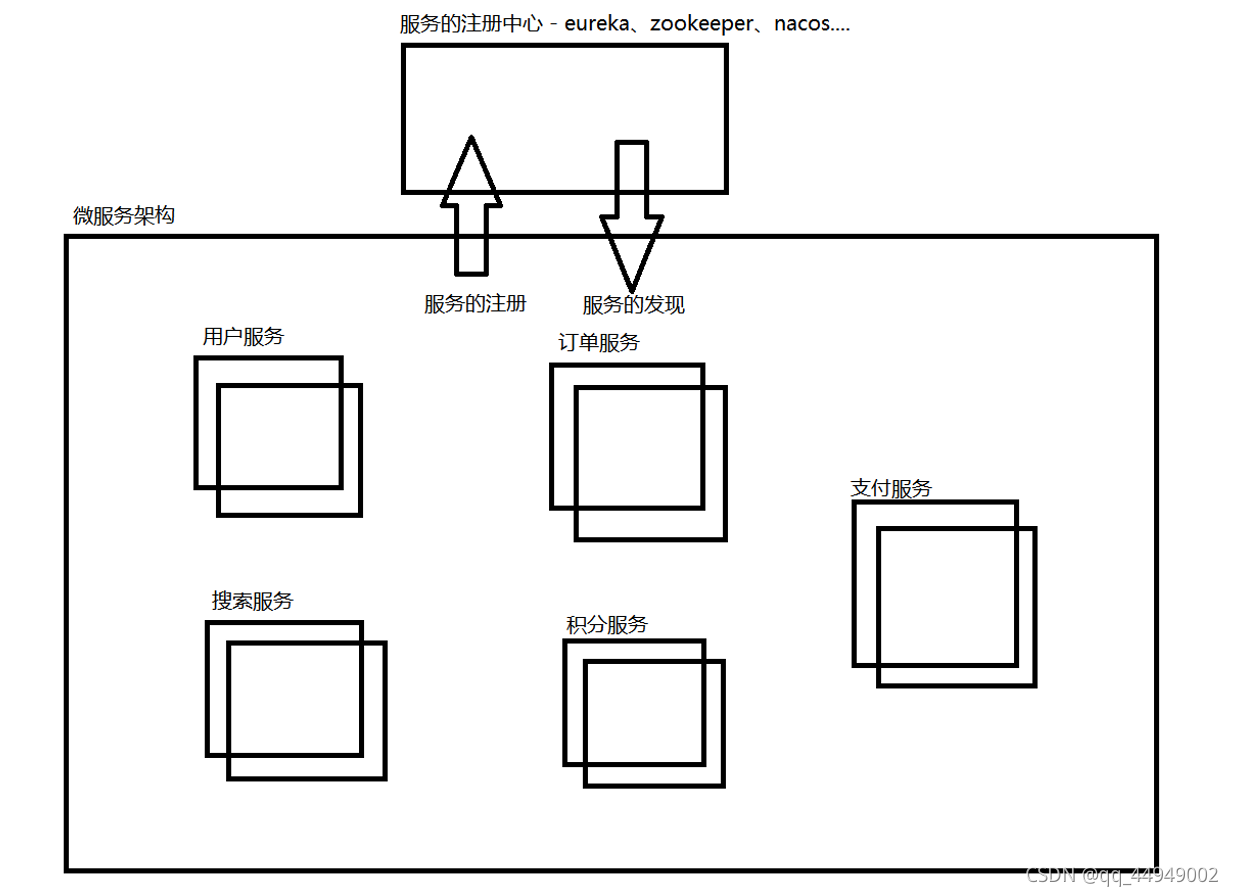
大致的微服务架构分布图
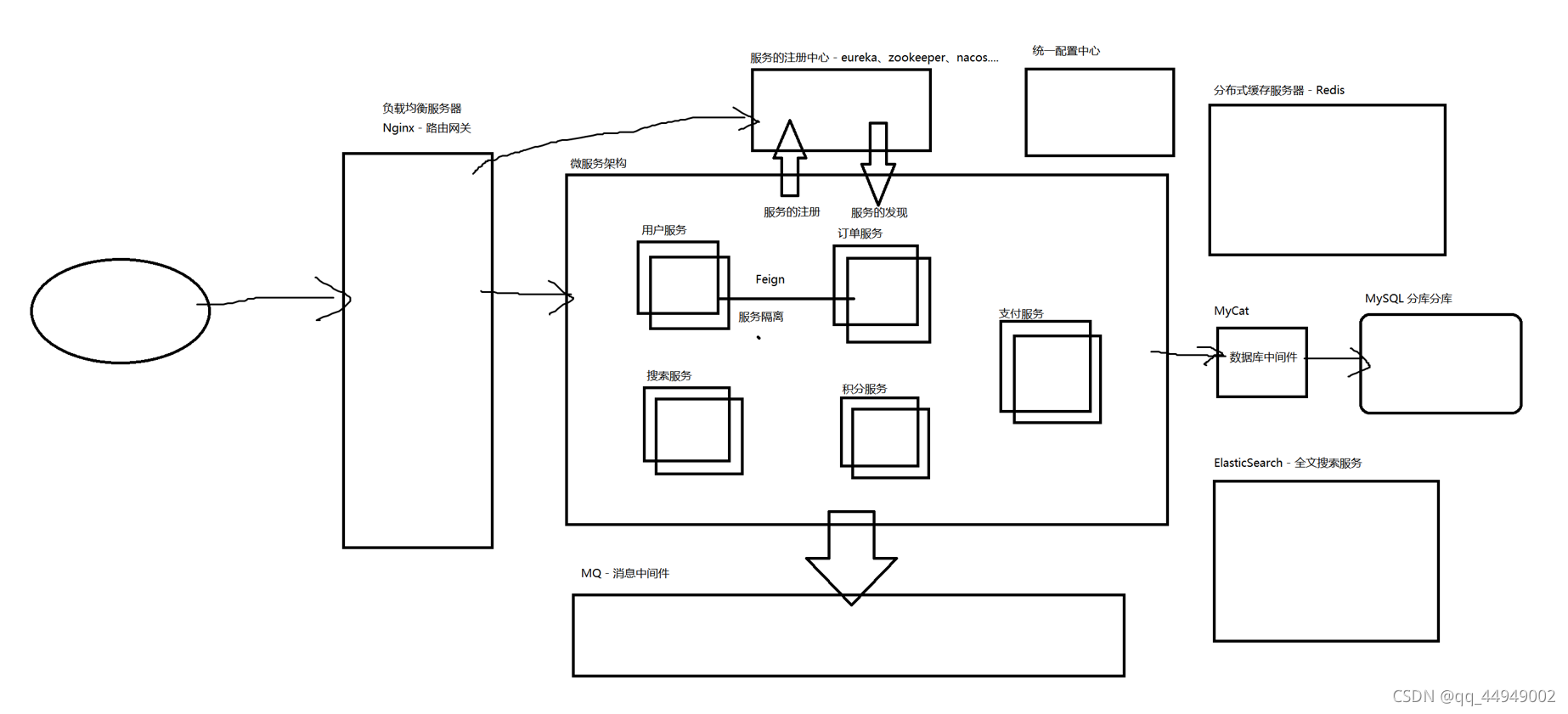
微服务架构思考:
好处
1、服务边界清晰
2、 开发相对独立
3、提升系统稳定性
4、扩展能力强
不足
1、链路变长、定位问题困难
2、系统运维成本高
3、对服务治理挑战大
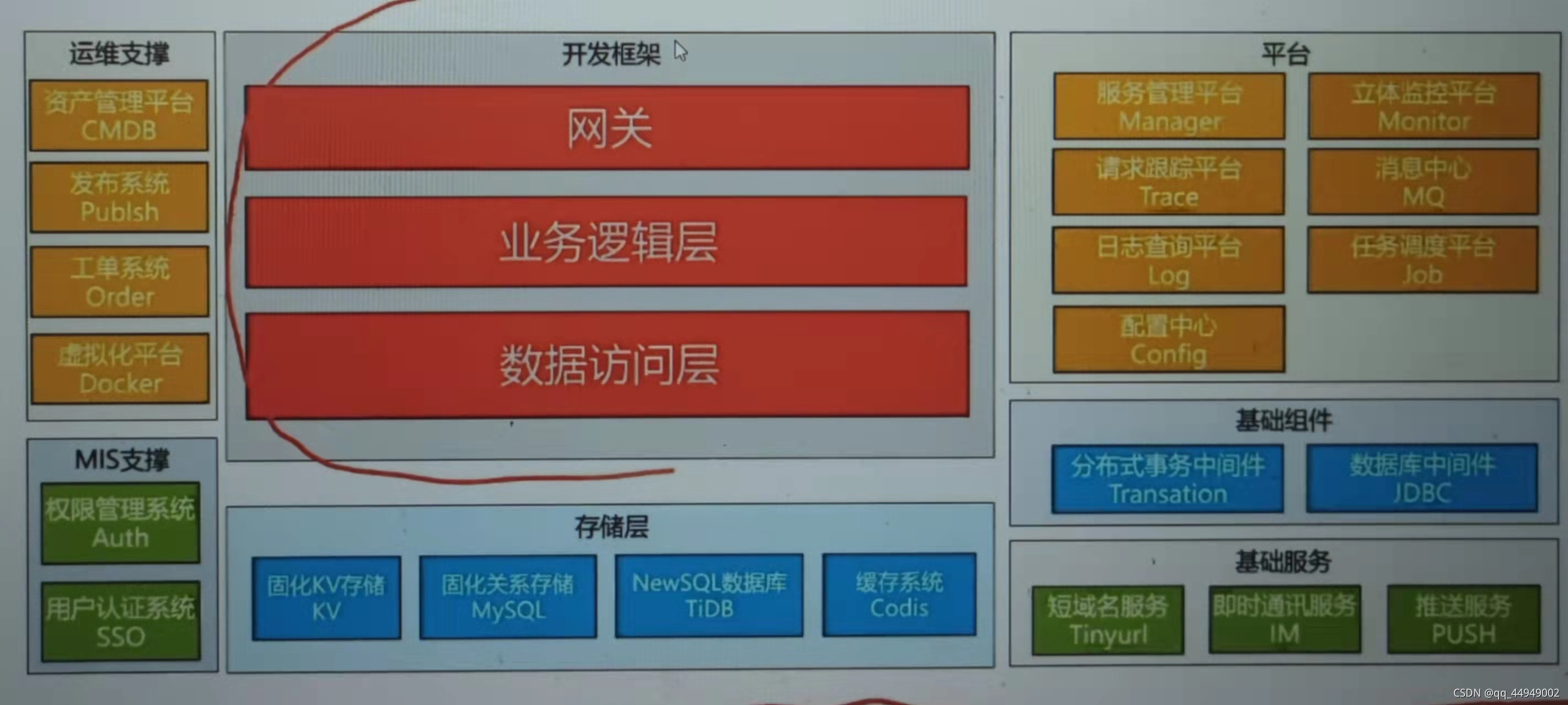
微服务系统及涉及技术点剖析
分布式架构技术挑战
1、节点故障:每台机器部署的多个节点,如果有一个节点挂了,需要知道哪台节点挂了,节点之间是怎么调用的,这就要流量控制或者性能监控平台了就可以针对性的恢复。如果线上几千台节点靠人工去发现问题就不太现实了所以需要监控体系。
2、机器性能差异:机器能坑的流量,处理请求不一样,部署的没那么好,怎么让流量适应,那么权重,路由去解决。
3、网路不可靠性:网络抖动,那么是就要有尝试机制,偶尔的抖动处理掉。
4、基础组件需求:那么上面三条就是基础组件完成的。
5、服务治理复杂度:
核心组成
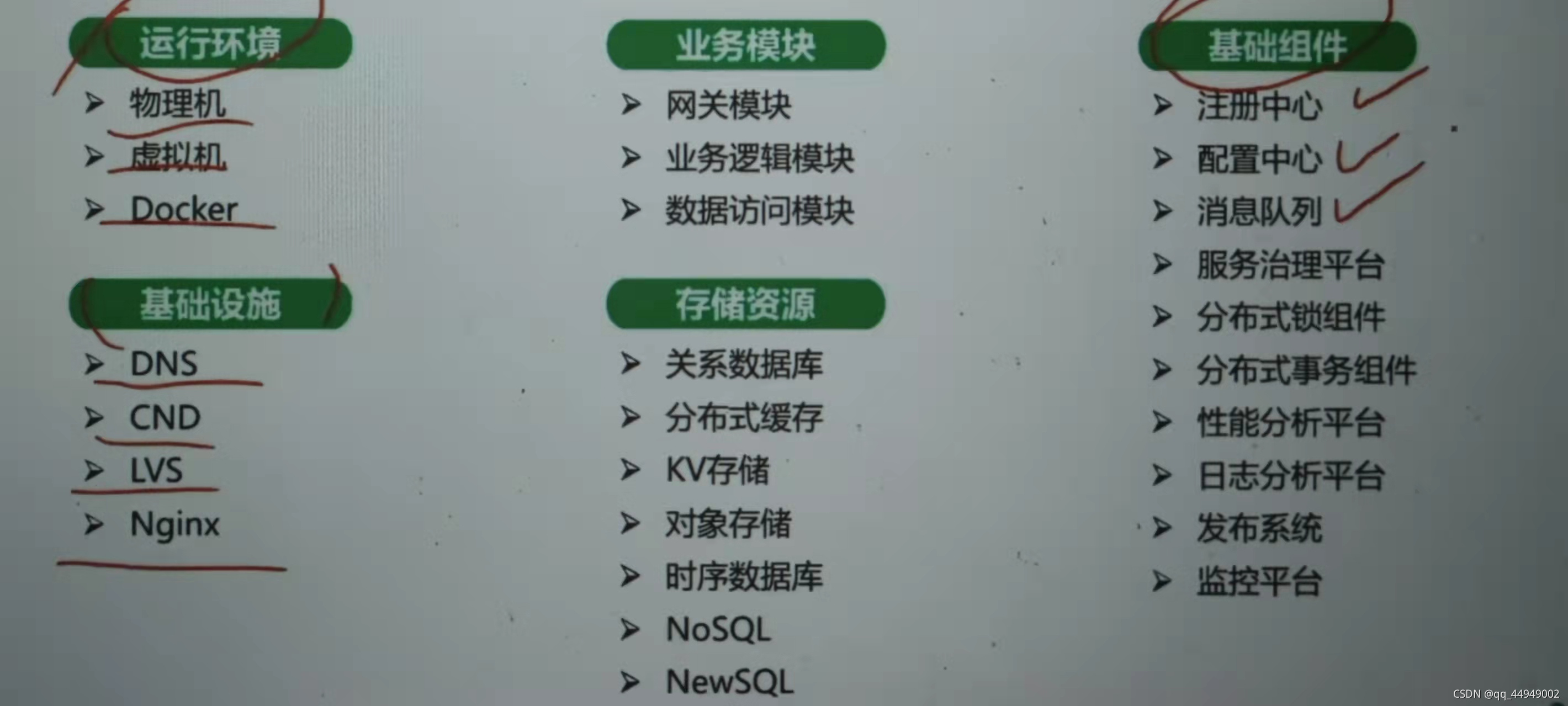
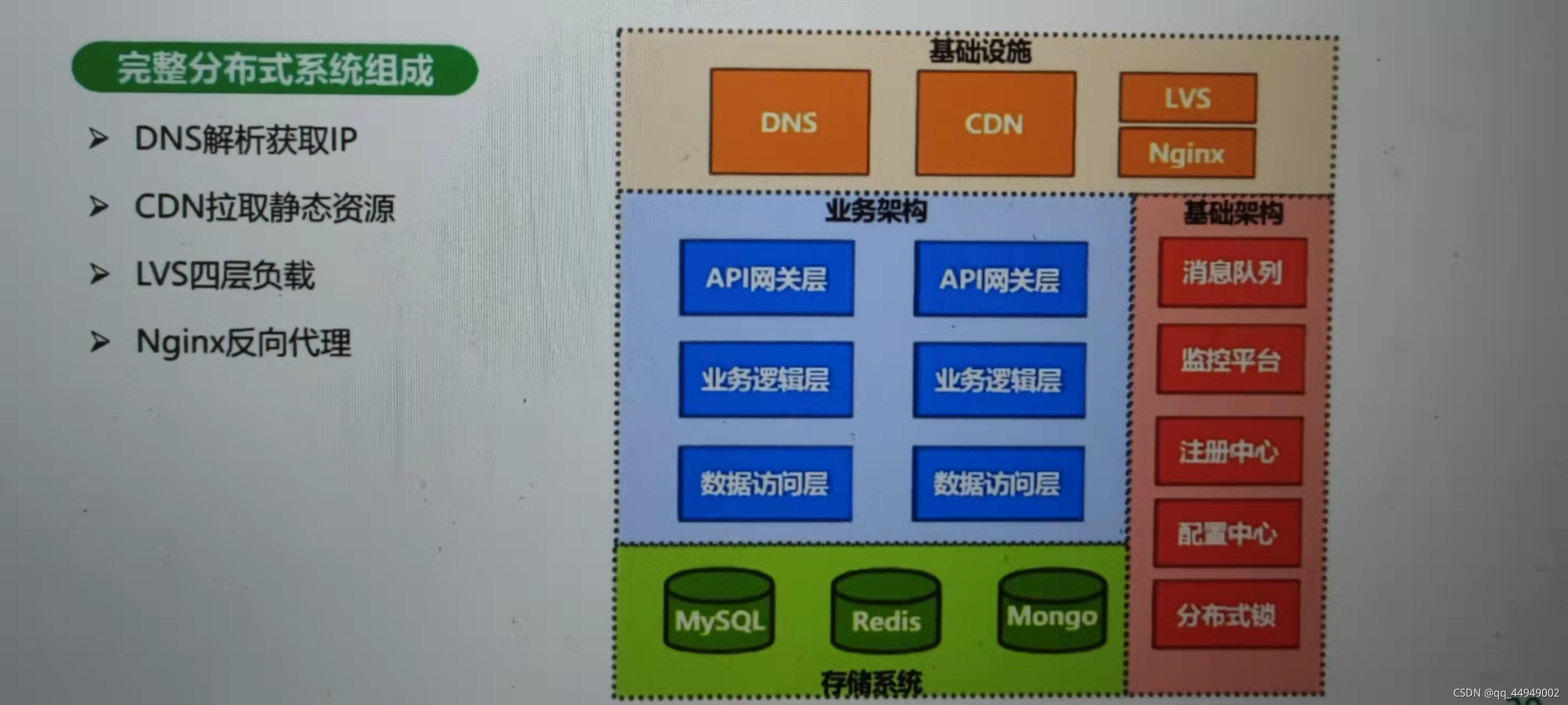
1、运行环境:是跑在物理机上:如果有个节点挂了,做容错我就不把流量分配给他了,活了在给你;但是在云上就是挂一个在起一个节点ip就不一样,就必须强依赖注册中心。还有虚拟机上还是dockers上,
2、基础设施:比如网关我的流量不是直接打到网关的,一个http请求起码先走dns把ip拿到,拿到ip去访问那么这个ip是ngis的ip嘛。ngis如何做高可用,ng把流量打到网关。ng怎么做多个节点,实现高可用,还有cdn==静态资源在全国有边缘站,这样拿去静态资源就比较快,没有cdn如果静态资源在存储的比较远,那你拿取就比较慢。
3、模块划分
4、存储资源:不同的数据库还有不同的缓存
5、基础组件:
6、测试运维
衡量标准
1、可用性:
2、性能:取决代码质量
3、吞吐量
4、扩展性:无状态,或者状态转移,数据库扩展那就是分库分表会带来分布式问题,分布式数据库就可以不用做数据的迁移,redis的扩展。百万并发指的是扩展性你坑并不是指定的是架构
5、一致性
主要技术点
1、负载均衡:lv到ng到gatway都要负载均衡
2、session管理
3、通讯、rpc
4、服务注册与发现
5、消息队列
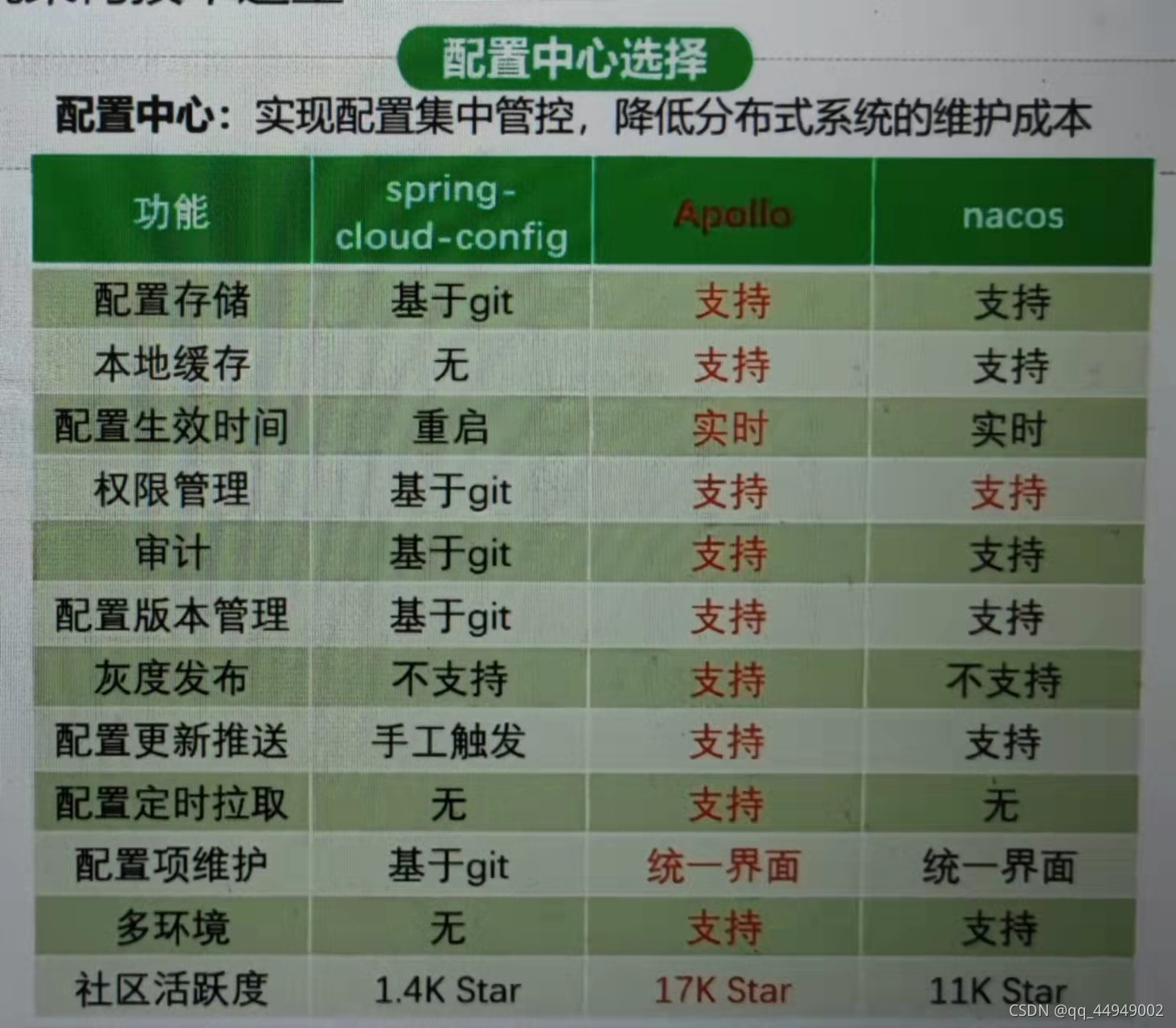
6、配置中心
7、分布式锁
8、缓存/分布式缓存
9、固化存储/分布式存储 tidb : newsql=kv+sql ;kv有很好的扩展,MySQL扩展性差他要数据迁移。kv查询不太友好,只能靠api。newsql就实现了很好的扩展性kv又有很好的查询,他是底层存储用kv,然后上层用mysql请求兼容。那吞吐量,计算过谁保证,可以都是由sql解决
转转 二手平台业务架构演进案列
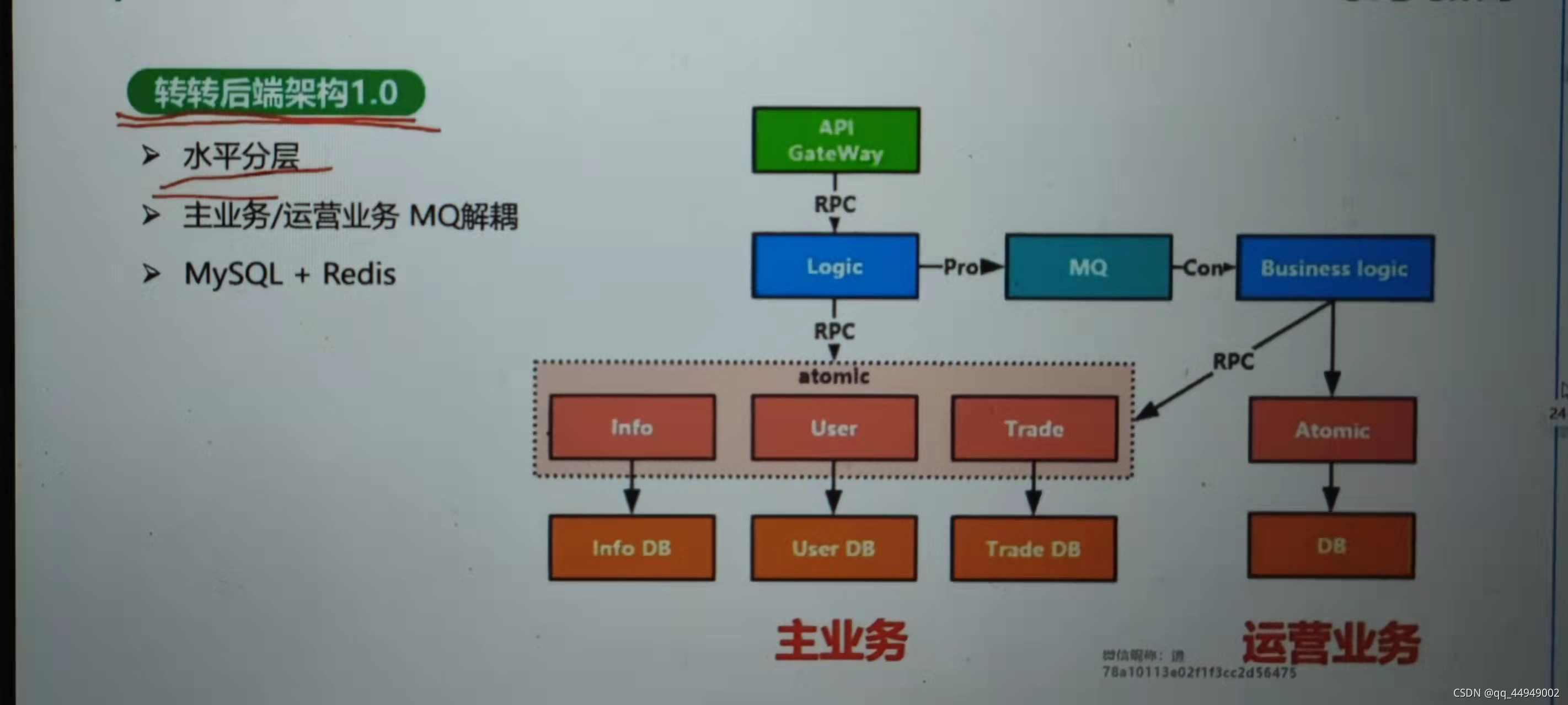
运营活动全在logic风险特别高,通过mq把他们分开,主业务分主业务,运营业务分运营活动

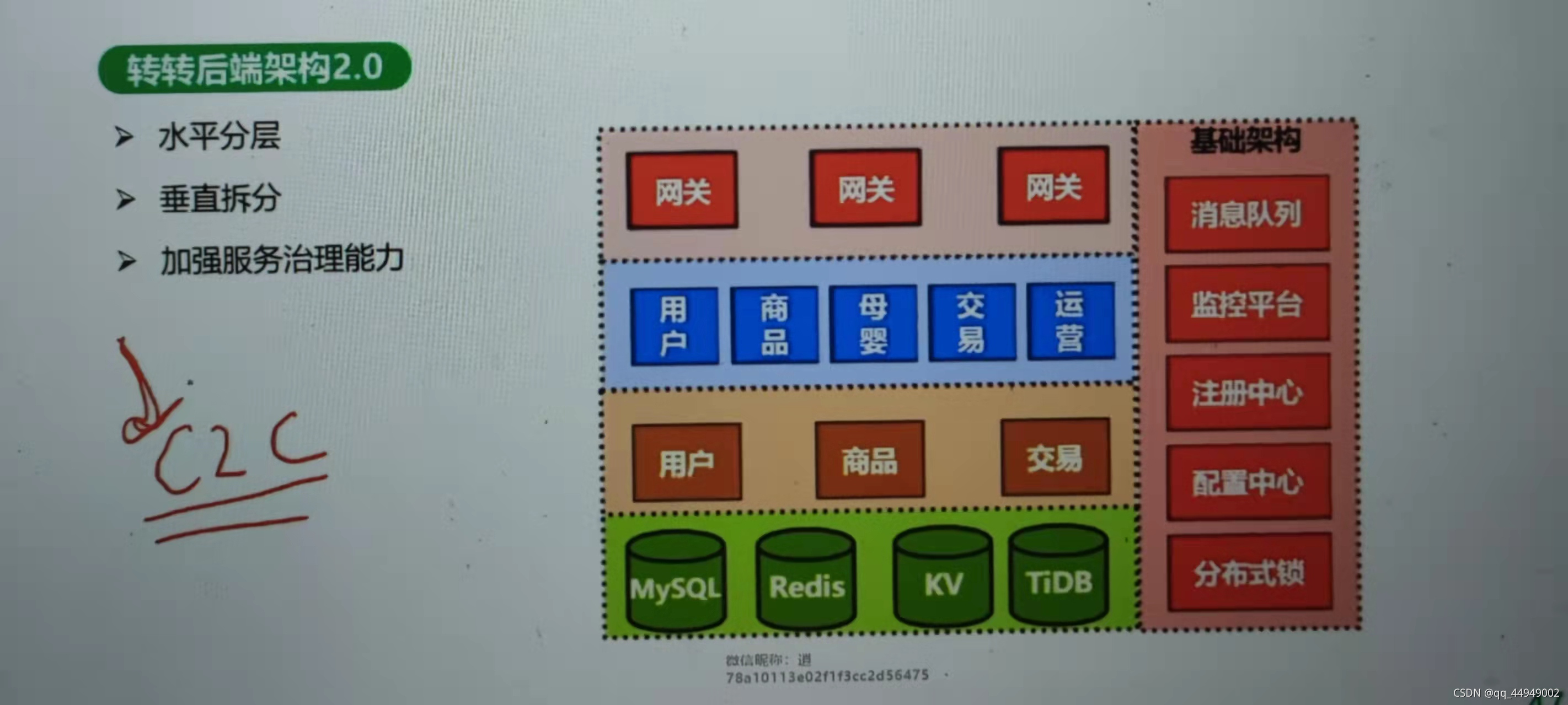
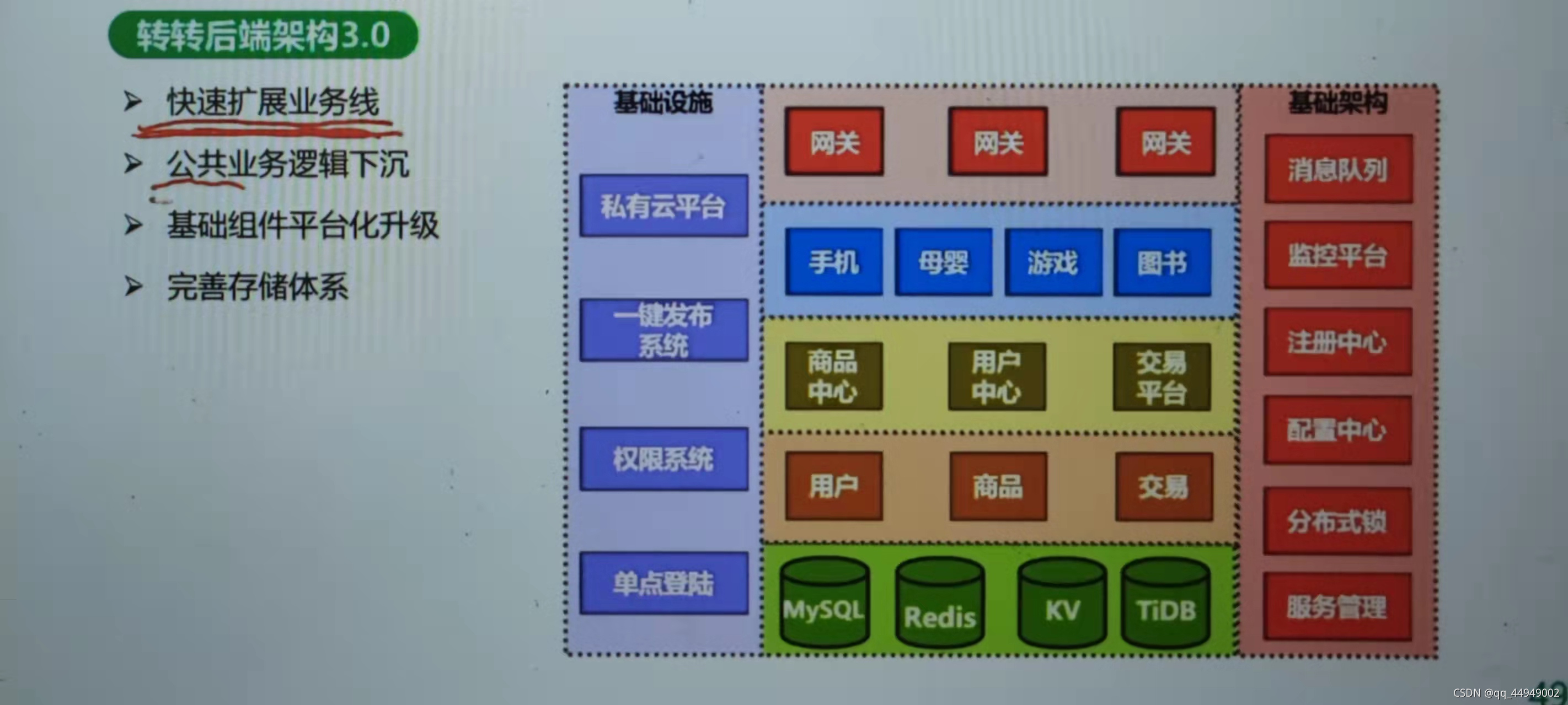
商品中心那一块就像中台一样手机和母婴有公共的业务下沉
分布式系统架构技术选型
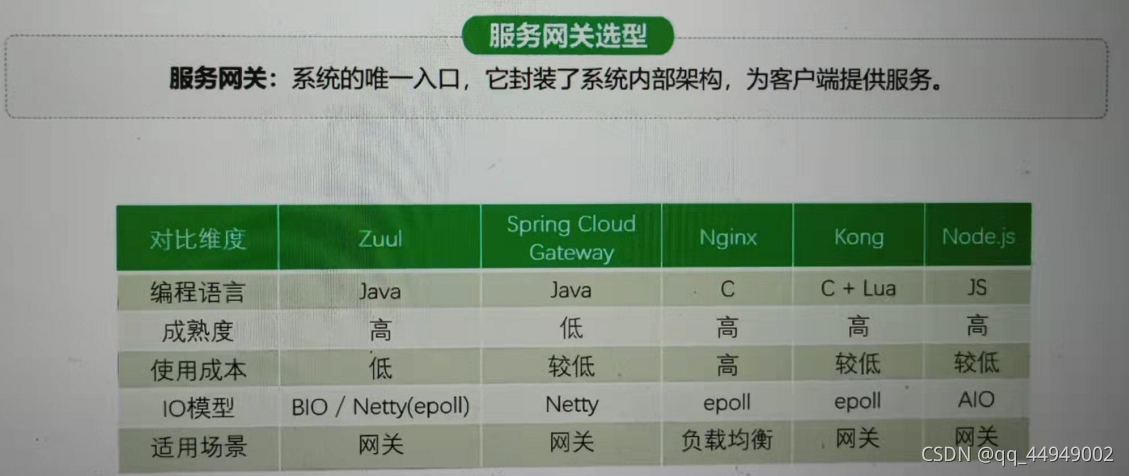
服务网关选型


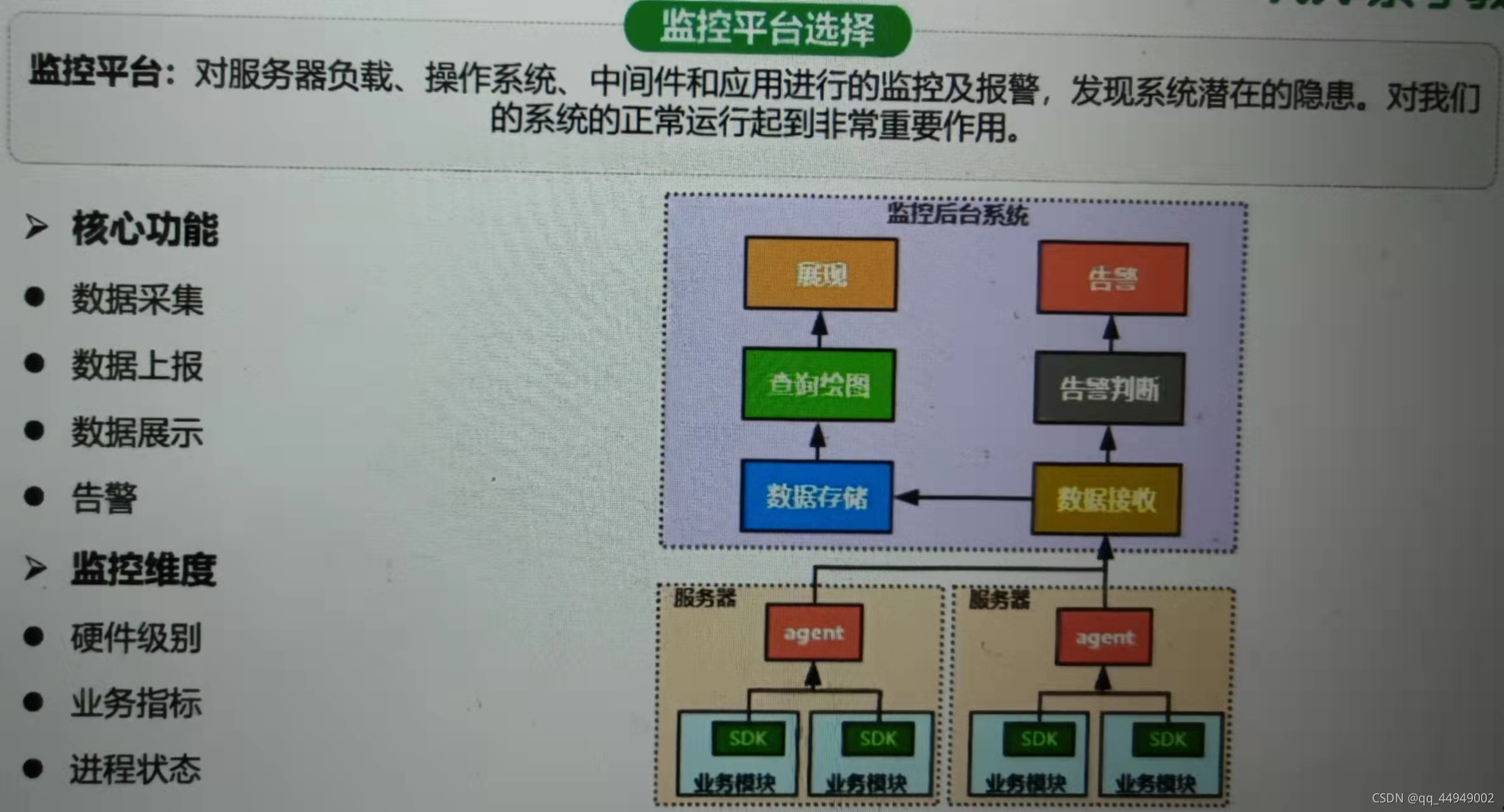
监控平台选型
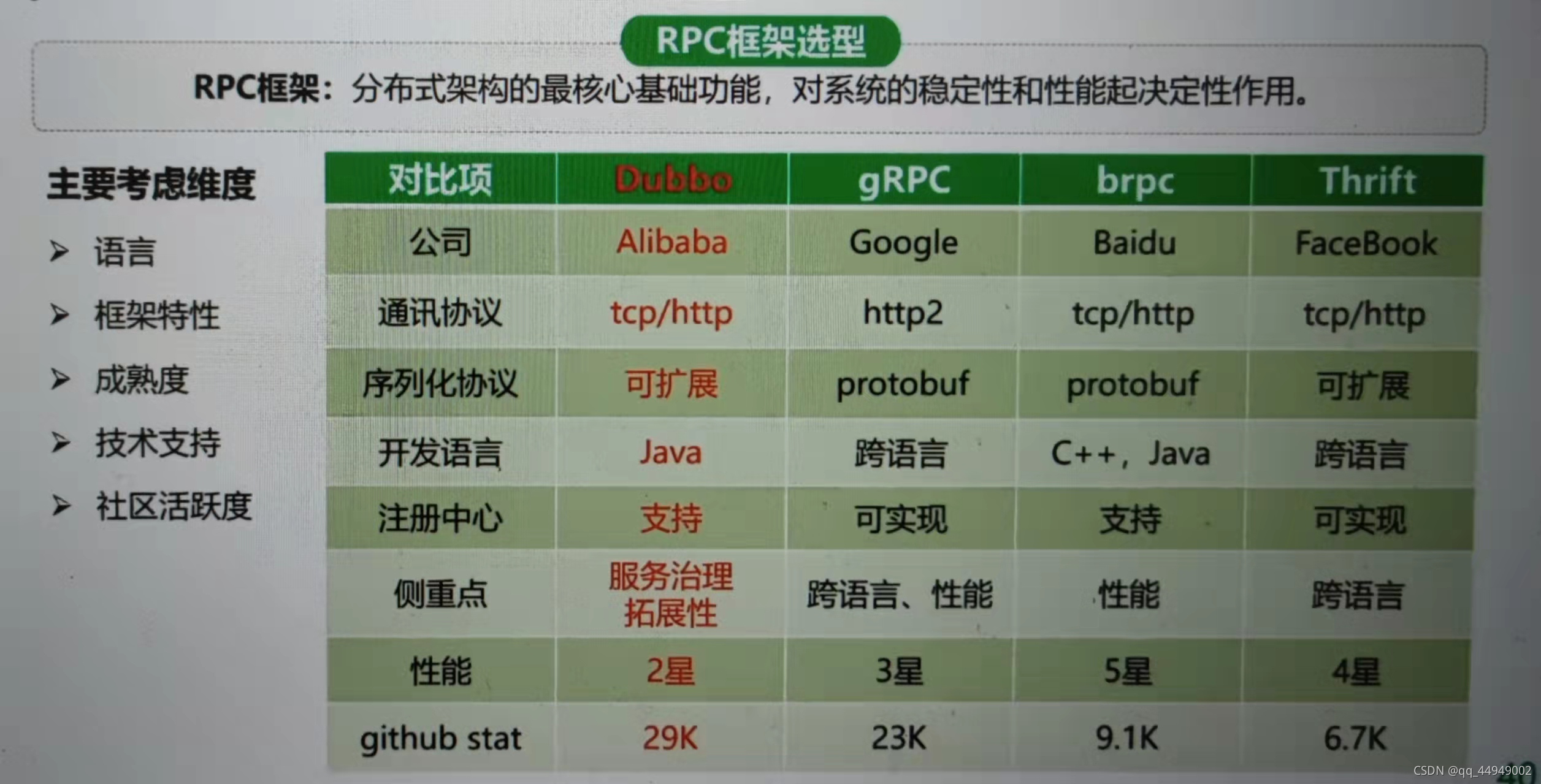
rpc框架选型

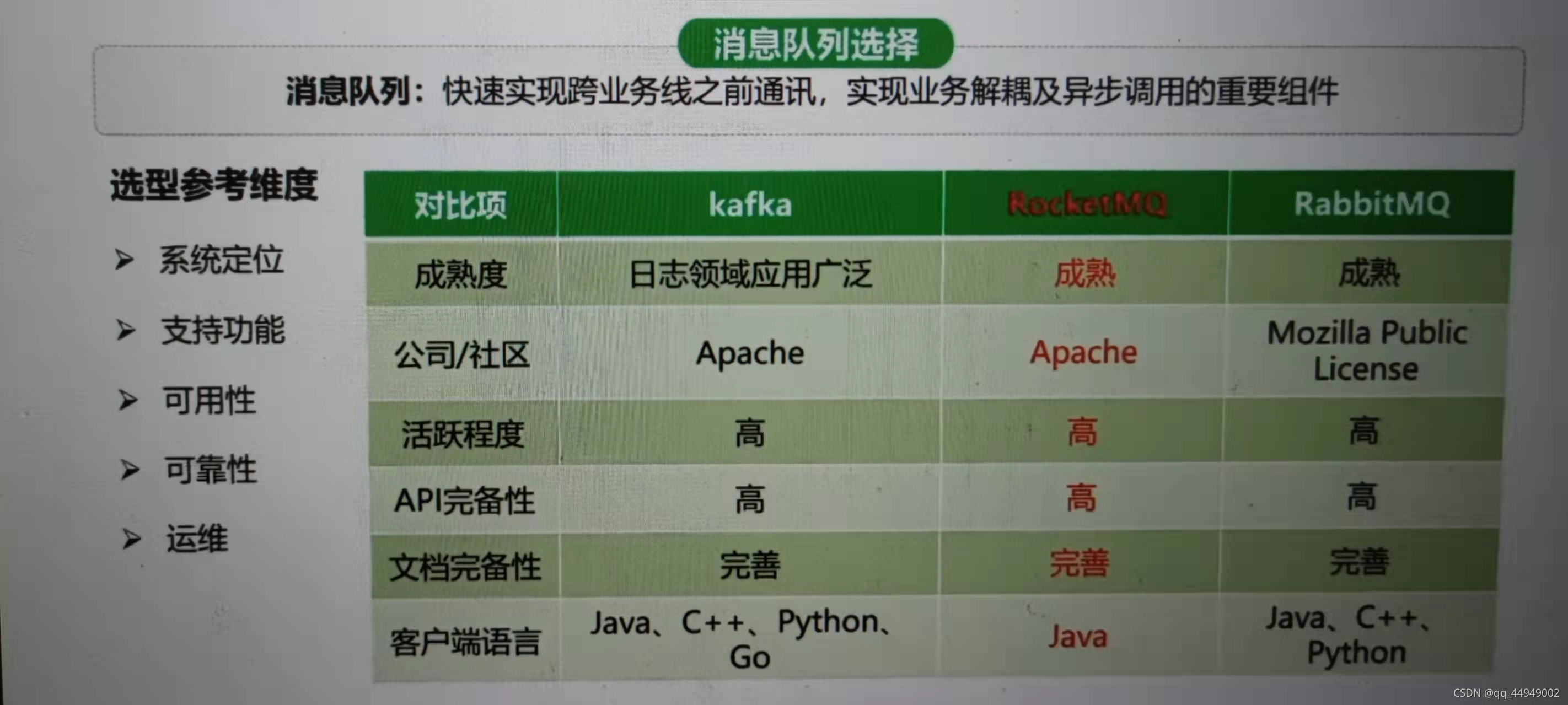
消息队列选型
配置中心选型