one-hot编码(每列只有一个1,其他都为0的一维矩阵)
一.图示
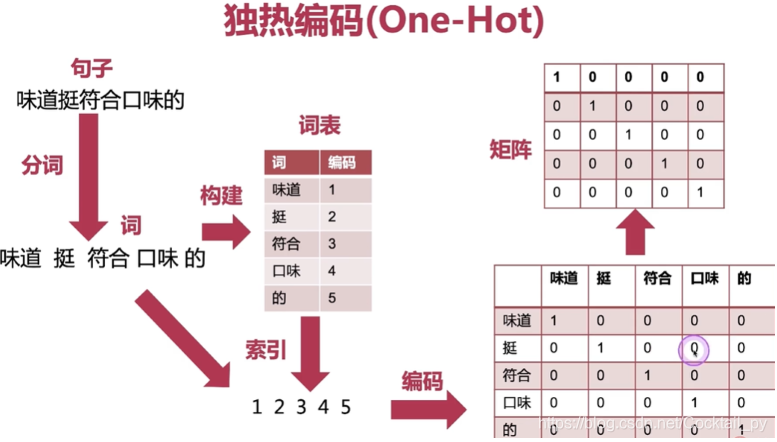
二.代码实现
import numpy as np
# 分词过的语料
corpus = [
'这 是 第一个 文档',
'这是 第二个 文档',
'这是 最后 一个 文档',
'现在 没有 文档 了'
]
## 1.手动实现
words = []
for corpu in corpus:
words.extend(corpu.split())
words = list(set(words))
# 构建词表 编码
word_dict = {
word: index for index, word in enumerate(words)}
print(word_dict)
vocab_size = len(word_dict)
def get_one_hot(index):
"""
获得一个one_hot编码
:param index:
:return:
"""
# 全零矩阵
one_hot = [0 for _ in range(vocab_size)]
# 指定位置1
one_hot[index] = 1
return np.array(one_hot)
# 原始句子
print(corpus[0])
# 转换成index
indexs = [word_dict[word] for word in corpus[0].split()]
# 转换成one_hot
one_hot_np = np.array([get_one_hot(index) for index in indexs])
print(one_hot_np)
## 2.Sklearn实现
from sklearn.preprocessing import LabelBinarizer
# 初始化编码器
lb = LabelBinarizer()
lb.fit_transform(words)
print(lb.classes_)
# 所有句子
sentence = corpus[0].split()
print(sentence)
one_hot_np2 = lb.transform(sentence)
print(one_hot_np2)
# 解码
print(lb.inverse_transform(one_hot_np2))
三.One-Hot缺点
1.词通常很多,比如50W,那就意味着需要句子长度x50000大小的矩阵才能表示这个句子
2.这种方法效率低下,矩阵包含很多零
3.无法表达相似性
4.新加一个词我们需要重新计算所有的词
参考: https://github.com/luojie1024