搭建基于HDFS碎片文件存储服务
实验目的
- 理解HDFS在Hadoop体系结构中的角色;
- 熟练使用HDFS操作常用的shell命令;
- 熟悉HDFS操作常用的javaAPI。
目录
一、准备java环境
1、安装JDK
HDFS 依赖 Java 环境,这里我们使用 yum 安装 JDK 8,在终端中键入如下命令
yum -y install java-1.8.0-openjdk*


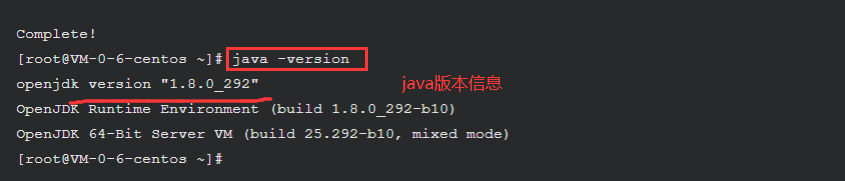
使用如下命令查看下 Java 版本,我们可以验证 JDK 是否已成功安装
java -version
2、配置java环境变量
在编辑器中打开文件 /etc/profile,在文件末尾追加如下内容,配置 Java 环境变量
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

保存文件

然后执行如下命令,让环境变量生效
source /etc/profile

通过如下命令,验证 Java 环境变量是否已成功配置并且生效
echo $JAVA_HOME

二、准备HDFS环境
1、配置SSH
先后执行如下两行命令,配置 SSH 以无密码模式登陆
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa

cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys

接着可以验证下,在不输入密码的情况下,应该能使用 ssh 命令成功连接本机
ssh 119.91.122.88

在终端中键入如下命令关闭 ssh 连接
exit
2、安装Hadoop
创建 /data/hadoop 目录,然后进入该目录
mkdir -p /data/hadoop && cd $_

接着下载 Hadoop 安装包到该目录下
wget http://archive.apache.org/dist/hadoop/core/hadoop-2.7.1/hadoop-2.7.1.tar.gz

下载完成

解压下载好的 Hadoop 安装包到当前目录
tar -zxvf hadoop-2.7.1.tar.gz


然后将解压后的目录重命名为 hadoop,并且将其移至 /usr/local/ 目录下
mv hadoop-2.7.1 hadoop && mv $_ /usr/local/

在编辑器中打开 Hadoop 环境配置文件,使用 Ctrl + F 搜索如下行
export JAVA_HOME=${JAVA_HOME}

将其替换为
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk

查看下 Hadoop 的版本
/usr/local/hadoop/bin/hadoop version
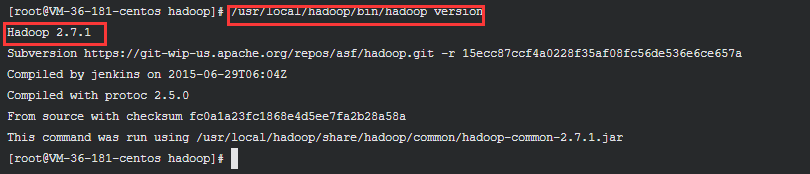
可以看到 Hadoop 的版本信息
Hadoop 2.7.1

3、修改Hadoop配置
由于我们的实践环境是在单机下进行的,所以此处把 Hadoop 配置为伪分布式模式。
首先新建若干临时文件夹,我们在后续的配置中以及 HDFS 和 Hadoop 的启动过程中会使用到这些文件夹
cd /usr/local/hadoop && mkdir -p tmp dfs/name dfs/data

修改 HDFS 配置文件 core-site.xml,将 configuration 配置修改为如下内容
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>

修改 HDFS 配置文件 hdfs-site.xml,将 configuration 配置修改为如下内容
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>

修改 HDFS 配置文件 yarn-site.xml,将 configuration 配置修改为如下内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

4、启动Hadoop
首先进入如下目录
cd /usr/local/hadoop/bin/

对 HDFS 文件系统进行格式化
./hdfs namenode -format

接着进入如下目录
cd /usr/local/hadoop/sbin/

先后执行如下两个脚本启动 Hadoop(出现的请求同意即可)
./start-dfs.sh

./start-yarn.sh

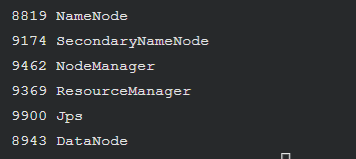
接着执行如下命令,验证 Hadoop 是否启动成功
jps

如果输出了类似如下的指令,则说明 Hadoop 启动成功
8819 NameNode
9174 SecondaryNameNode
9462 NodeManager
9369 ResourceManager
9900 Jps
8943 DataNode
至此,我们的 HDFS 环境就已经搭建好了。在浏览器中访问如下链接,应该能正常访问(注:若出现安全拦截请选择通过)
http://139.199.61.47:50070/explorer.html#/

三、存储碎片文件
1、准备碎片文件
首先创建目录用于存放碎片文件,进入该目录
mkdir -p /data/file && cd /data/file
然后执行如下 shell 命令,新建一批碎片文件到该目录下
i=1; while [ $i -le 99 ]; do name=`printf "test%02d.txt" $i`; touch "$name"; i=$(($i+1)); done

在终端中执行 ls 命令,可以看到我们已成功创建了一批碎片文件

2、将碎片文件存储在 HDFS 中
首先在 HDFS 上新建目录
/usr/local/hadoop/bin/hadoop fs -mkdir /dest

此时,在浏览器是访问如下链接,可以看到 /dest 目录已创建,但是暂时还没有内容
http://139.199.61.47:50070/explorer.html#/dest

接着我们可以上传碎片文件啦!首先在终端中依次执行以下命令
groupadd supergroup
usermod -a -G supergroup root

然后将之前创建的碎片文件上传到 HDFS 中
cd /data/file && /usr/local/hadoop/bin/hadoop fs -put *.txt /dest

这时,再使用如下命令,我们应该能看到碎片文件已成功上传到 HDFS 中
/usr/local/hadoop/bin/hadoop fs -ls /dest

四、结果显示
在浏览器是访问如下链接,可以看到 /dest 目录的文件内容
http://139.199.61.47:50070/explorer.html#/dest
