点击“终码一生”,关注,置顶公众号
每日技术干货,第一时间送达!
整体流程大概如下:
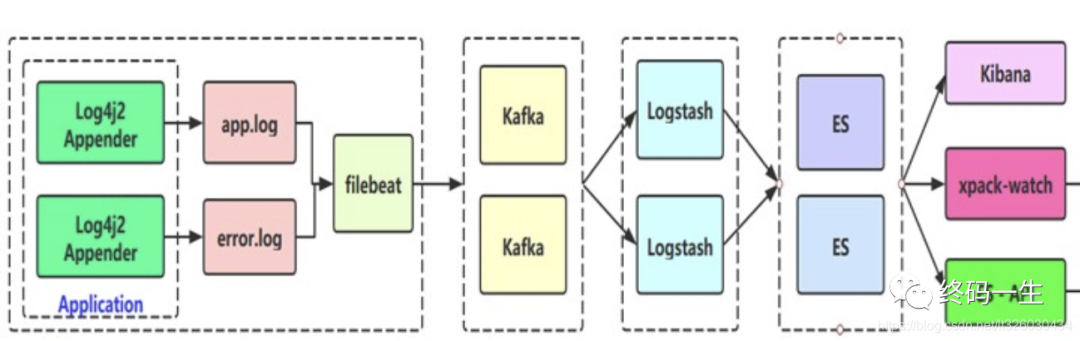
1
服务器准备
在这先列出各服务器节点,方便同学们在下文中对照节点查看相应内容
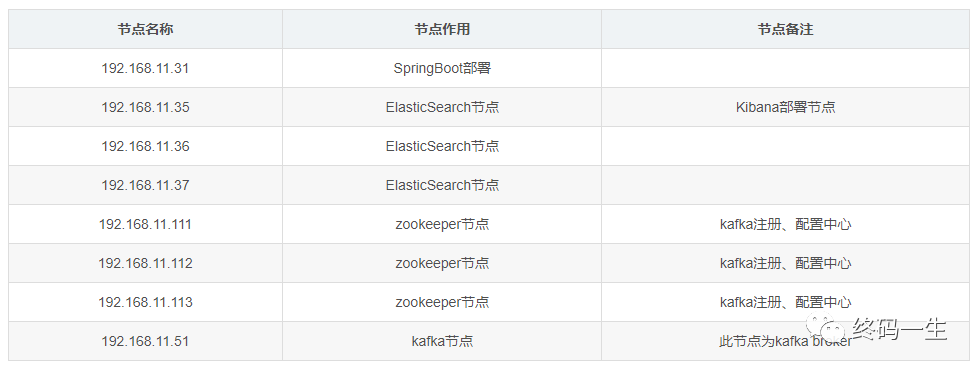
2
SpringBoot项目准备
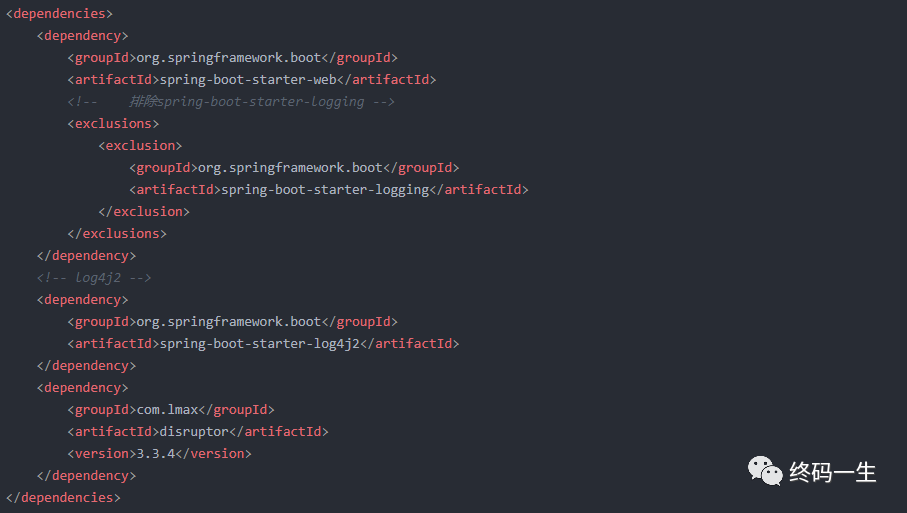
引入log4j2替换SpringBoot默认log,demo项目结构如下:

pom
IndexController
测试Controller,用以打印日志进行调试

InputMDC
用以获取log中的[%X{hostName}]、[%X{ip}]、[%X{applicationName}]三个字段值

NetUtil

启动项目,访问/index和/ero接口,可以看到项目中生成了app-collector.log和error-collector.log两个日志文件

我们将Springboot服务部署在192.168.11.31这台机器上。
3
Kafka安装和启用
kafka下载地址:http://kafka.apache.org/downloads.html
kafka安装步骤:首先kafka安装需要依赖与zookeeper,所以小伙伴们先准备好zookeeper环境(三个节点即可),然后我们来一起构建kafka broker。

创建两个topic
## 创建topic
kafka-topics.sh --zookeeper 192.168.11.111:2181 --create --topic app-log-collector --partitions 1 --replication-factor 1
kafka-topics.sh --zookeeper 192.168.11.111:2181 --create --topic error-log-collector --partitions 1 --replication-factor 1我们可以查看一下topic情况
kafka-topics.sh --zookeeper 192.168.11.111:2181 --topic app-log-test --describe可以看到已经成功启用了app-log-collector和error-log-collector两个topic

4
filebeat安装和启用:
filebeat下载
cd /usr/local/software
tar -zxvf filebeat-6.6.0-linux-x86_64.tar.gz -C /usr/local/
cd /usr/local
mv filebeat-6.6.0-linux-x86_64/ filebeat-6.6.0配置filebeat,可以参考下方yml配置文件
vim /usr/local/filebeat-5.6.2/filebeat.yml###################### Filebeat Configuration Example #########################
filebeat.prospectors:
- input_type: log
paths:
## app-服务名称.log, 为什么写死,防止发生轮转抓取历史数据
- /usr/local/logs/app-collector.log
#定义写入 ES 时的 _type 值
document_type: "app-log"
multiline:
#pattern: '^\s*(\d{4}|\d{2})\-(\d{2}|[a-zA-Z]{3})\-(\d{2}|\d{4})' # 指定匹配的表达式(匹配以 2017-11-15 08:04:23:889 时间格式开头的字符串)
pattern: '^\[' # 指定匹配的表达式(匹配以 "{ 开头的字符串)
negate: true # 是否匹配到
match: after # 合并到上一行的末尾
max_lines: 2000 # 最大的行数
timeout: 2s # 如果在规定时间没有新的日志事件就不等待后面的日志
fields:
logbiz: collector
logtopic: app-log-collector ## 按服务划分用作kafka topic
evn: dev
- input_type: log
paths:
- /usr/local/logs/error-collector.log
document_type: "error-log"
multiline:
#pattern: '^\s*(\d{4}|\d{2})\-(\d{2}|[a-zA-Z]{3})\-(\d{2}|\d{4})' # 指定匹配的表达式(匹配以 2017-11-15 08:04:23:889 时间格式开头的字符串)
pattern: '^\[' # 指定匹配的表达式(匹配以 "{ 开头的字符串)
negate: true # 是否匹配到
match: after # 合并到上一行的末尾
max_lines: 2000 # 最大的行数
timeout: 2s # 如果在规定时间没有新的日志事件就不等待后面的日志
fields:
logbiz: collector
logtopic: error-log-collector ## 按服务划分用作kafka topic
evn: dev
output.kafka:
enabled: true
hosts: ["192.168.11.51:9092"]
topic: '%{[fields.logtopic]}'
partition.hash:
reachable_only: true
compression: gzip
max_message_bytes: 1000000
required_acks: 1
logging.to_files: truefilebeat启动:
检查配置是否正确
cd /usr/local/filebeat-6.6.0
./filebeat -c filebeat.yml -configtest
## Config OK启动filebeat
/usr/local/filebeat-6.6.0/filebeat &检查是否启动成功
ps -ef | grep filebeat可以看到filebeat已经启动成功

然后我们访问192.168.11.31:8001/index和192.168.11.31:8001/err,再查看kafka的logs文件,可以看到已经生成了app-log-collector-0和error-log-collector-0文件,说明filebeat已经帮我们把数据收集好放到了kafka上。
5
logstash安装
logstash的安装可以参考《Logstash的安装与使用》。
我们在logstash的安装目录下新建一个文件夹
mkdir scrpit然后cd进该文件,创建一个logstash-script.conf文件
cd scrpit
vim logstash-script.conf## multiline 插件也可以用于其他类似的堆栈式信息,比如 linux 的内核日志。
input {
kafka {
## app-log-服务名称
topics_pattern => "app-log-.*"
bootstrap_servers => "192.168.11.51:9092"
codec => json
consumer_threads => 1 ## 增加consumer的并行消费线程数
decorate_events => true
#auto_offset_rest => "latest"
group_id => "app-log-group"
}
kafka {
## error-log-服务名称
topics_pattern => "error-log-.*"
bootstrap_servers => "192.168.11.51:9092"
codec => json
consumer_threads => 1
decorate_events => true
#auto_offset_rest => "latest"
group_id => "error-log-group"
}
}
filter {
## 时区转换
ruby {
code => "event.set('index_time',event.timestamp.time.localtime.strftime('%Y.%m.%d'))"
}
if "app-log" in [fields][logtopic]{
grok {
## 表达式,这里对应的是Springboot输出的日志格式
match => ["message", "\[%{NOTSPACE:currentDateTime}\] \[%{NOTSPACE:level}\] \[%{NOTSPACE:thread-id}\] \[%{NOTSPACE:class}\] \[%{DATA:hostName}\] \[%{DATA:ip}\] \[%{DATA:applicationName}\] \[%{DATA:location}\] \[%{DATA:messageInfo}\] ## (\'\'|%{QUOTEDSTRING:throwable})"]
}
}
if "error-log" in [fields][logtopic]{
grok {
## 表达式
match => ["message", "\[%{NOTSPACE:currentDateTime}\] \[%{NOTSPACE:level}\] \[%{NOTSPACE:thread-id}\] \[%{NOTSPACE:class}\] \[%{DATA:hostName}\] \[%{DATA:ip}\] \[%{DATA:applicationName}\] \[%{DATA:location}\] \[%{DATA:messageInfo}\] ## (\'\'|%{QUOTEDSTRING:throwable})"]
}
}
}
## 测试输出到控制台:
output {
stdout { codec => rubydebug }
}
## elasticsearch:
output {
if "app-log" in [fields][logtopic]{
## es插件
elasticsearch {
# es服务地址
hosts => ["192.168.11.35:9200"]
# 用户名密码
user => "elastic"
password => "123456"
## 索引名,+ 号开头的,就会自动认为后面是时间格式:
## javalog-app-service-2019.01.23
index => "app-log-%{[fields][logbiz]}-%{index_time}"
# 是否嗅探集群ip:一般设置true;http://192.168.11.35:9200/_nodes/http?pretty
# 通过嗅探机制进行es集群负载均衡发日志消息
sniffing => true
# logstash默认自带一个mapping模板,进行模板覆盖
template_overwrite => true
}
}
if "error-log" in [fields][logtopic]{
elasticsearch {
hosts => ["192.168.11.35:9200"]
user => "elastic"
password => "123456"
index => "error-log-%{[fields][logbiz]}-%{index_time}"
sniffing => true
template_overwrite => true
}
}
}启动logstash
/usr/local/logstash-6.6.0/bin/logstash -f /usr/local/logstash-6.6.0/script/logstash-script.conf &等待启动成功,我们再次访问192.168.11.31:8001/err
可以看到控制台开始打印日志

6
ElasticSearch与Kibana
ES和Kibana的搭建之前没写过博客,网上资料也比较多,大家可以自行搜索。
ElasticSearch集群的的搭建可以参考《ElasticSearch:集群搭建》。
搭建完成后,访问Kibana的管理页面192.168.11.35:5601,选择Management -> Kinaba - Index Patterns
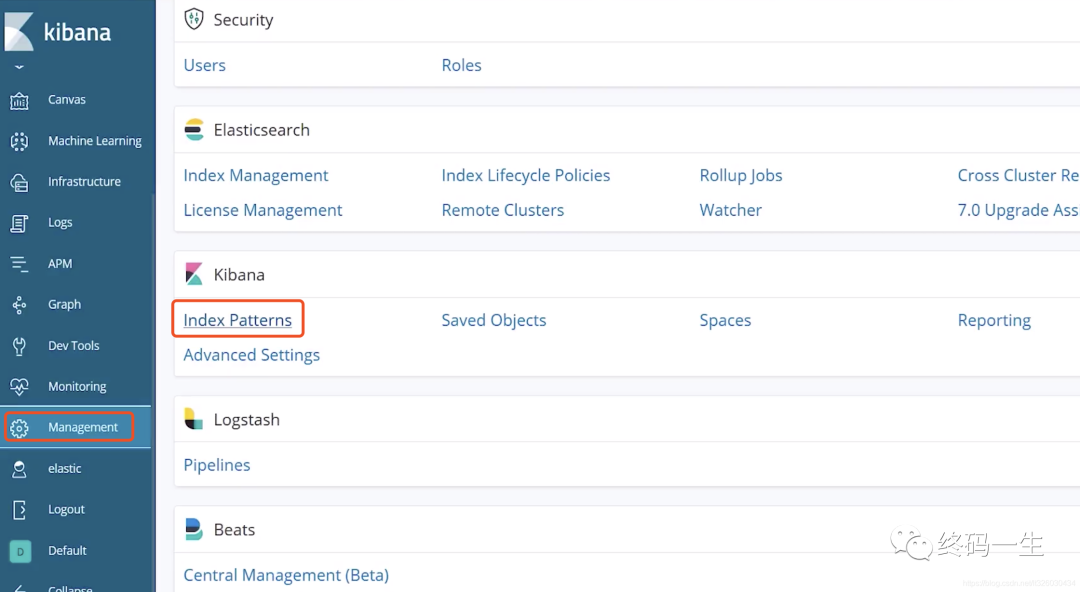
然后Create index pattern
index pattern 输入 app-log-*
Time Filter field name 选择 currentDateTime
这样我们就成功创建了索引。
我们再次访问192.168.11.31:8001/err,这个时候就可以看到我们已经命中了一条log信息
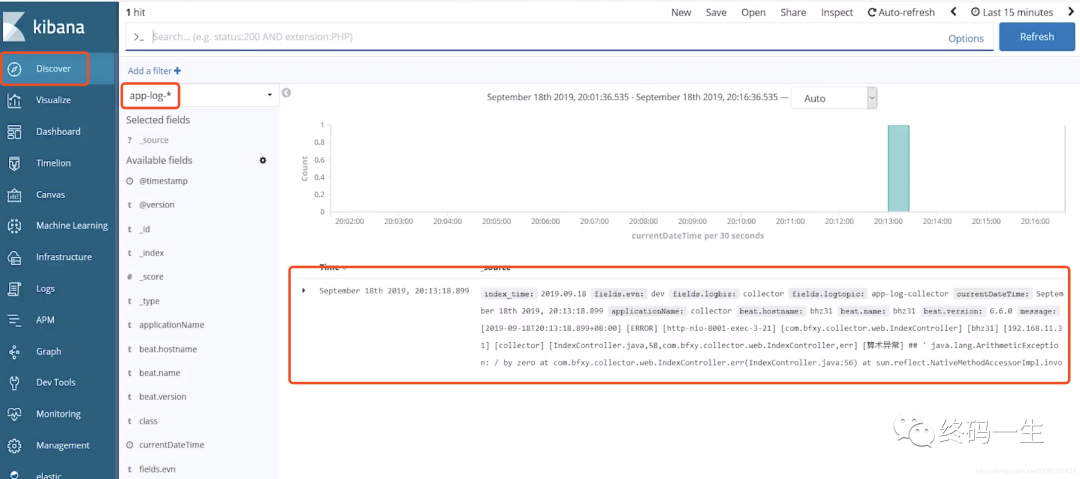
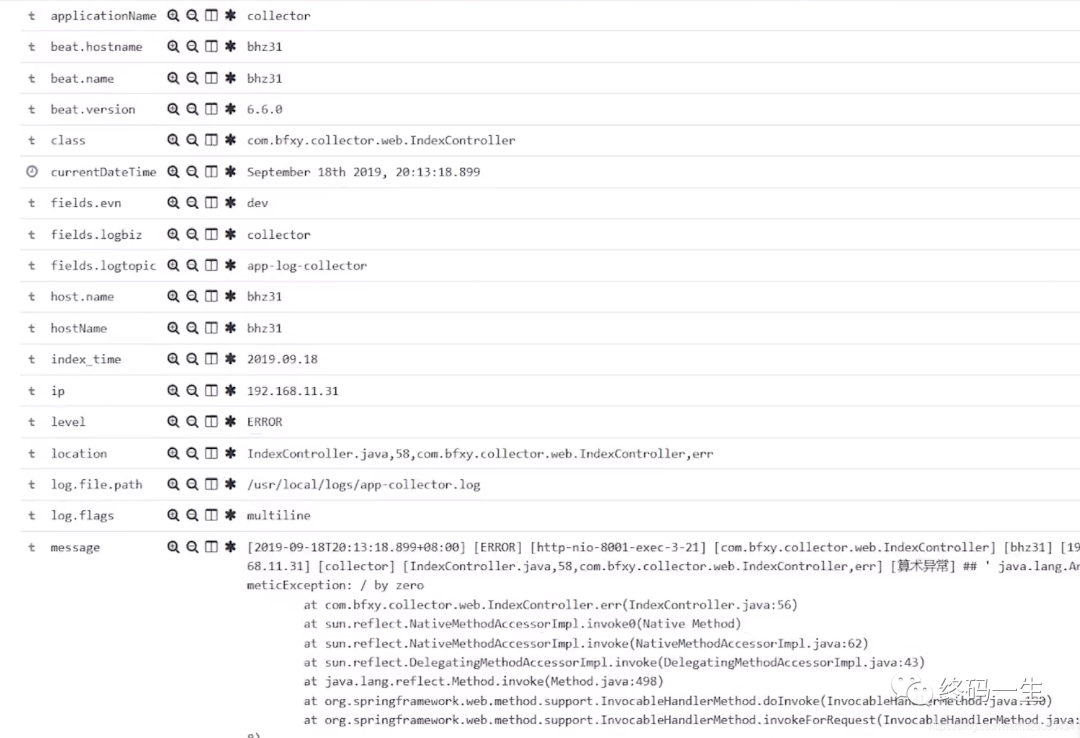
里面展示了日志的全量信息
到这里,我们完整的日志收集及可视化就搭建完成了!
来源:https://blog.csdn.net/lt326030434/article/details/107361190
PS:防止找不到本篇文章,可以收藏点赞,方便翻阅查找哦。