前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,而学习机器学习,离不开python语言的学习,今天我开启了python数据分析之旅,希望每天可以学一点,记录一点。
一、数据预处理
在遇到一个数据分析的话题或项目时,我们所要做的第一步是认真读懂题目,分析出题目给予我们的信息,分析出题目制定的任务。机器学习项目的题目一般会给很多数据,然后这些数据之间有一定的关联,所以在使用机器学习算法进行分析数据前,需要对数据进行预处理。
因此掌握数据预处理的方法和流程,是成为算法工程师的第一步。
预处理所涉及到的操作主要有:
- 数据文件的打开和读写;
- 了解数据的初始格式;
- 探索数据之间的相关性;
- 规范化数据格式;
- 数据字段内容的替换;
- 事件规范化;
- 时间规范化:对各类数据中的时间字段进行格式统一转换
- 预聚合计算;
- 将部分数据进行编码,比如one-hot编码;
- ……
而在以上这些预处理中,我们最常用到的两个工具就是numpy和pandas。接下来的持续更新主要围绕数据的分析与处理。
二、今天学到的方法
1.引入库
代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2.读入数据
代码如下:
# 首先查看一下所在目录都有哪些文件
import os
for dir,dirnames,filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
输出结果如下:
/kaggle/input/titanic/train.csv
/kaggle/input/titanic/test.csv
/kaggle/input/titanic/gender_submission.csv
于是我们得知该数据集有三个文件。分别是train.csv、test.csv以及gender_submission.csv。
下面对文件中的数据进行查看。
dftrain_raw = pd.read_csv('/kaggle/input/tinanic/train.csv')
drtest_raw = pd.read_csv('kaggle/input/titanic/test.csv')
dftrain_raw.head()
print(dftrain_raw.head())
下面是对训练集前五项的查看:
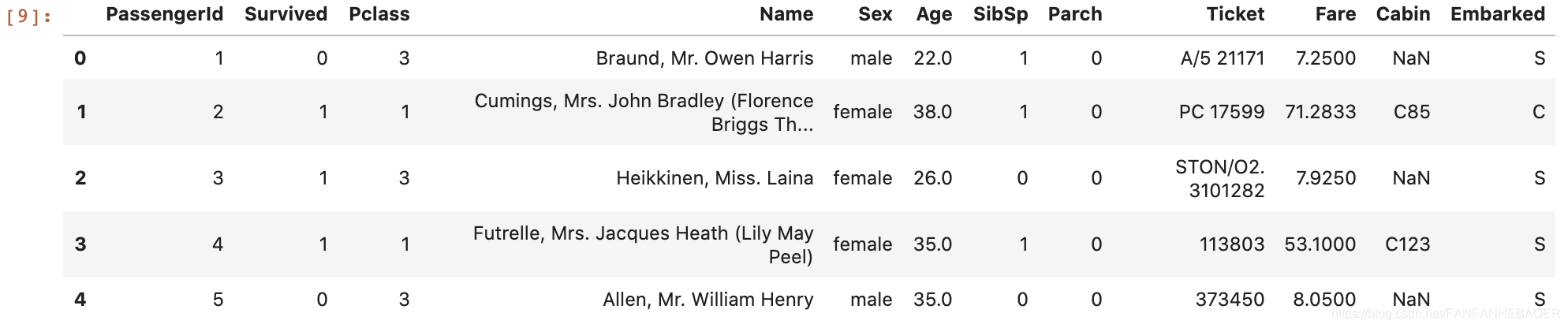
3.学习总结
os.walk()函数。
os.walk() 方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下。
os.walk() 方法是一个简单易用的文件、目录遍历器,可以帮助我们高效的处理文件、目录方面的事情。在Unix,Windows中有效。
代码示例:
import os
for root,dirs,files in os.walk("./", topdown=False):
for name in files:
print(os.path.join(root.name))
for name in dirs:
print(os.path.join(root,name))
value_counts()
value_counts()是一种查看表格某列中有多少个不同值的快捷方法,并计算每个不同值有在该列中有多少重复值。
value_counts()是Series拥有的方法,一般在DataFrame中使用时,需要指定对哪一列或行使用。
代码示例:
%matplotlib inline
%config InlineBackend.figure_format = 'png'
ax = dftrain_raw['Survived'].value_counts().plot(kind = 'bar',figsize = (12,8),fontsize=15,rot=0)
ax.set_ylabel('Counts',fontsize = 15)
ax.set_xlabel('Survived',fontsize = 15)
plt.show()

总结
以上就是今天要记录的内容,果然真的记录下来的时候,会发现自己每天学习的内容是多么的少。以后要加油。