一、文件操作
文件读写的几种方式 读:r r+ rb rb+ r 和 r+ 只读 适用于普通场景 rb 和 rb+ 适用于 文件、图片、视频、音频等文件读取 写:w w+ wb wb+ a ab w wb w+ wb 每次都会创建文件 二进制读写时要注意编码问题,默认情况下我们写入的文件编码是gbk格式 a ab a+ 在原有的文件基础之后(文件的末尾)去追加,并不会创建新文件
1.1 打开文件open()、写入文件write()、关闭文件close()
打开文件,没有则新建,此函数返回文件句柄,‘w’表示写入。‘a’表示追加
# 打开文件 默认编码是GBK中文编码,最好的习惯是在打开文件是指定一个编码格式
obj=open('./Test.txt','w',encoding='utf-8') #打开文件,没有则新建,此函数返回文件句柄
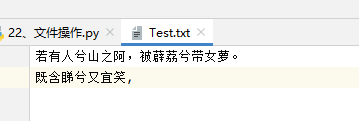
obj.write('若有人兮山之阿,') #写入内容到文件
obj.write('被薜荔兮带女萝。\n')
obj.close() #关闭文件
#文件追加
obj=open('Test.txt','a',encoding='utf-8')
obj.write('既含睇兮又宜笑,')
obj.close()代码执行后,文件相应的位置会出现《Test.txt》,文件里的内容为 下图
1.2 文件读取 read()、readline()、readlines()
with ....as.... 会在文件使用结束后,自动释放打开的文件,防止内存泄露
with open('Test.txt','r',encoding='utf-8') as f: #with ....as.... 会自动释放打开的文件,防止内存泄露
print(f.read(2))
print(f.read(2)) #第二次调用read函数,会在第一次读取的光标之后读取
print(f.readline()) #读取一行
print(f.readlines()) #读取所有一行,返回时一个列表对象需要说明的是:文件读取时起始光标为文件开头,以后每次读都是以上一次读取结束的位置作为起始位置。
1.3 小实验---文件备份
#文件备份
def CopyFile():
old_flie=input('请输入要备份的文件名')
file_list=old_flie.split('.') #split 过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串 ['Test', 'txt']
print(file_list)
#构造新的文件名 . 加上备份的后缀名
new_file=file_list[0]+'_备份.'+file_list[1]
print(new_file)
old_f=open(old_flie,'r',encoding='utf-8')
new_f=open(new_file,'w',encoding='utf-8')
conten=old_f.read()
new_f.write(conten)
old_f.close()
new_f.close()
pass
CopyFile()上面的代码 假如要备份的文件过大,读取大文件 则会导致内存被占用。一下是改良版本
#上面的代码 假如读取大文件 则会导致内存被占用
def CopyFile():
old_flie=input('请输入要备份的文件名')
file_list=old_flie.split('.') #split 过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串 ['Test', 'txt']
print(file_list)
#构造新的文件名 . 加上备份的后缀名
new_file=file_list[0]+'_备份.'+file_list[1]
print(new_file)
try:
with open(old_flie,'r',encoding='utf-8') as old_f,open(new_file,'w',encoding='utf-8') as new_f:
while True:
conten=old_f.read(1024) #设置每次读取1k个字符
new_f.write(conten) #写入到新文件
if len(conten)<1024: #如果本次读取的字符 小于1k ,跳出循环
break
pass
pass
except Exception as msg:
print(msg)
pass
CopyFile()
1.4 文件定位相关函数
tell() ------------返回当前文件读取到的位置
truncate() --------可对源文件进行截取操作 保留前15个字符 会修改源文件
seek()-------------跳转到文件的指定位置seek
.....
#文件定位
#读文件
with open('Test.txt','r+',encoding='utf-8') as f: #with ....as.... 会自动释放打开的文件,防止内存泄露
print(f.tell()) #返回当前文件读取到的位置
print(f.read(2))
print(f.read(2)) #第二次调用read函数,会在第一次读取的光标之后读取
print(f.tell())
print(f.readline()) #读取一行
print(f.readlines()) #读取所有一行,返回时一个列表对象
print(f.read())
f.truncate(15) #可对源文件进行截取操作 保留前15个字符 会修改源文件
print(f.read().encode('gbk'))
print(f.tell()) # 第二次调用read函数,会在第一次读取的光标之后读取
f.seek(-2,2)
print(f.tell()) # 第二次调用read函数,会在第一次读取的光标之后读取
#跳转到文件的指定位置seek
二、模块操作
模块导入时发生以下 3步操作 1、打开模块文件 2、执行模块对应的文件,将执行过程产生的名字丢到模块的名称空间 3、程序中调用时,指向对应的文件的相应位置
2.1 导入模块
导入模块的三种形式:
import time #导入时间模块
print(time.ctime()) #调用时间模块
from time import ctime,time
print(ctime())
#from time import *假如模块内部有 “__all__” 的方法那么 在使用from xxx import 导入时 只有all指定可以被外部调用的函数。例如那么假如外部文件使用 from xxx import 加载这个文件,只能加载到add_test一个函数。
__all__=['add_test'] #在使用from xxx import 导入时 只有all指定可以被外部调用的函数
def add_test(x,y):
return x+y
if __name__ == '__main__': #表示 只有在当前文件执行
print('模块测试,%s'%add_test(1,5))
passif __name__ == '__main__': #表示 只有在当前文件执行
2.2 系统操作
使用Python操作Windows系统的相关内容
import os
import shutil
os.rename('Test_备份.txt','测试.txt') #重命名 《Test_备份.txt》文件为《测试.txt》前提是文件必须存在
os.remove('test.py') # 删除文件《test.py》 前提是文件必须存在
os.mkdir('python') #创建文件件 只能创建一层文件
os.rmdir('python') #删除文件夹 只能删除空目录
os.makedirs('d:/Pthon/a/b') #创建文件夹多级文件夹
shutil.rmtree('d:/Pthon/a/b') #删除全部文件夹 包含子文件
print(os.getcwd()) #获取当前所在路径
print(os.path)
print(os.getcwd().join(),'venv') #路径拼接举例:文件遍历
#遍历文件方法1
lis=os.listdir('D:/') #获取D盘的文件列表
print(lis)
#遍历文件方法2
with os.scandir('d:/') as i:
for j in i:
print(j.name)
pass2.3 模块制作
-
在python中一个.py文件就是一个模块 不同的模块可以定义相同的变量名、函数名,但只应用于本模块中 模块分为 : 内置模块 第三方模块 自定义模块
2.3.1 模块制作步骤1--在当前工程下创建文件夹mod

2.3.2 写入一个固定格式的文件setup
from distutils.core import setup
#name 模块名称
#version 版本号
#description 描述
#author 作者
#py_modules 要发布的内容
setup(name='add',version='1.0',description='test',author='zxl',py_modules=['add'])2.3.3 创建 和 压缩
使用Windows命令行进入当前创建的文件夹目录下执行如下操作
