在第一篇中,我们实现了一个简单单因子的策略模型,但是在实际中,我们是远远不会满足于一个因子甚至几个因子的。
市场上目前挖掘出来的因子成千上万个,如何有效筛选出比较好的几个因子构建一个选股模型呢?
手动从无穷多个因子中筛选出几个因子显然不太现实,现在网上的主流思想都是使用线性回归模型以及机器学习模型从众多的因子中筛选出有效因子。
一般投资者构建多因子模型的思路如下:
首先根据自己的喜好人工选择因子,或者基于统计数据选择因子,又或者直接将所有因子投喂给模型,构建自己的因子库之后合成或者预测选股择时的信号,根据投资的目标对选股以及择时信号做出反应。
而在本篇文章中,我们将采用机器学习的算法对股票进行选股买入。
目录
策略思路
1、回测时间:2020年
2、模型训练时间:前五个月,股票池采用沪深300成分股。
3、调仓时间:每个月的第一个交易日。
4、数据获取:基于本篇中粗略手动筛选出来的几个因子,获取沪深300成分股当前的因子数据。
5、数据处理:对因子数据进行去极值和标准化处理,计算沪深300成分股当前的月收益率,这里只需要判断收益率的正负就好。
6、委托下单:基于以上五步训练出来的模型,对未来一个月的收益率进行预测,并将筛选出来的股票调仓到持仓中。最后并将数据继续喂给模型。
构建本策略因子库
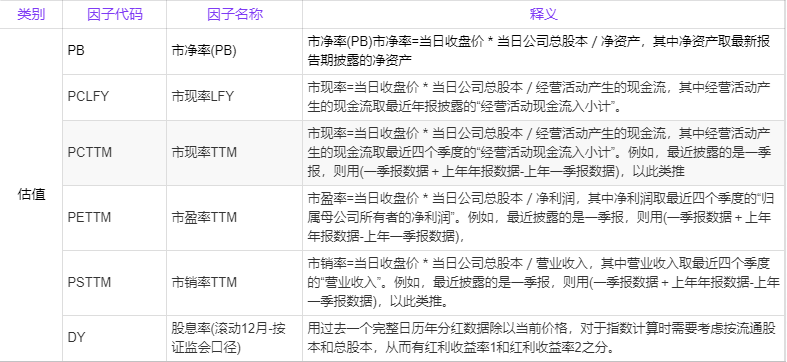
为了方便以下的研究,本篇暂且选择一个大类因子,一共6个因子构建多因子模型,其中这些因子的信息如下所示:
回测结果
回测结果如下所示,其中累计收益率为23.33%,夏普比率为1.72,说明模型有待优化,可以参考上文中对模型的展望对模型进行优化改进。
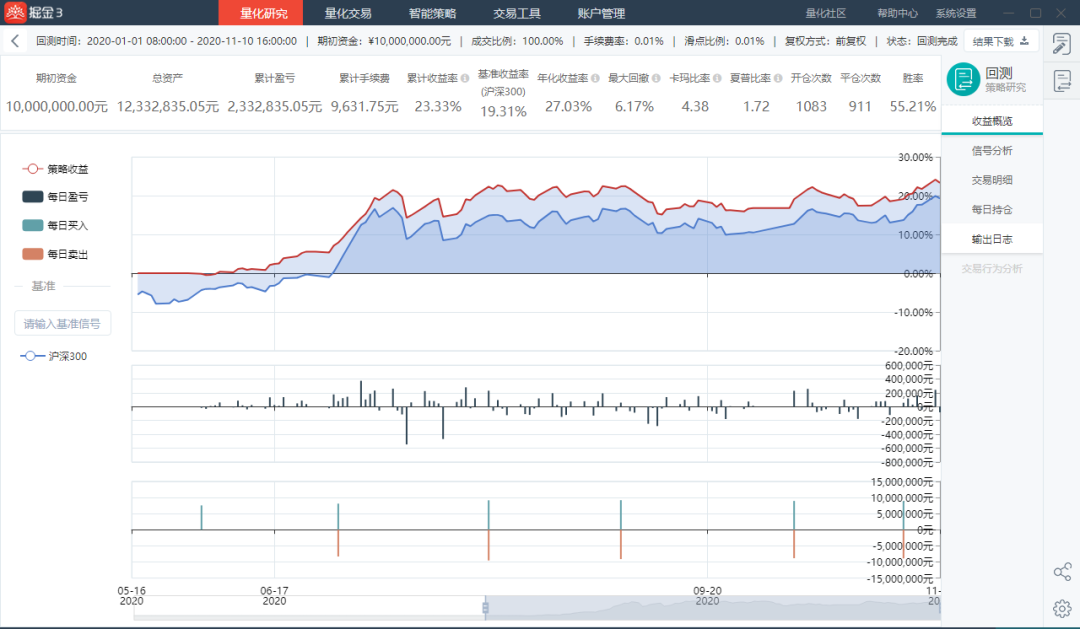
(回测报告由掘金量化提供)
模型评价和展望
优点:本篇中实现了机器学习模型滚动训练,采用了掘金2020年的几个因子的数据,在2020年前半年训练出模型,在后半年在回测中将预测会涨的股票调仓进持仓中,该模型可以很好的应用于市场中。
缺点:这个模型的思想虽然有可取之处,但是调仓周期一个月还是有点长;其次,对于因子数据的平稳性以及有效性,在该策略中没有进行检验和处理;
对该模型的改进的展望:
1、可以设置多一些因子数据放进模型中。
2、可以在预测模型建立之前筛选出合适的因子或者构造新的因子。
3、对数据进行有效性检验以及处理。
4、可以加入择时因子,适时买入。
5、这个模型中筛选出股票之后是将持仓先全部平仓再买入筛选出来的股票,这里可以先去判断筛选出来的股票池中的股票是否在持仓中,不在的话再委托买入,同时卖出在持仓但不在股票池中的股票。
6、这个模型做的是二分类模型,可以考虑换成回归模型,对股票收益率进行回归和预测,买入预测收益率最大的前几支股票。
策略源代码
# coding=utf-8
from __future__ import print_function, absolute_import
from gm.api import *
import datetime
import pandas as pd
import numpy as np
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# 中位数去极值法
def filter_MAD(df, factors, n=3):
"""
df: 去极值的因子数据
factor: 待去极值的因子字段
n: 中位数偏差值的上下界倍数
return: 经过处理的因子df
"""
for factor in factors:
median = df[factor].quantile(0.5)
new_median = ((df[factor] - median).abs()).quantile(0.5)
max_range = median + n * new_median
min_range = median - n * new_median
for i in range(df.shape[0]):
if df.loc[i, factor] > max_range:
df.loc[i, factor] = max_range
elif df.loc[i, factor] < min_range:
df.loc[i, factor] = min_range
return df
# 策略中必须有init方法
def init(context):
#从掘金中导入因子数据
context.factor_names=['PB','PCLFY','PCTTM','PETTM','PSTTM','DY']
#获取沪深300成分股股票
context.hs300=get_constituents(index='SHSE.000300')
#每月的第一个交易日的09:40:00执行策略algo_1
schedule(schedule_func=algo_1, date_rule='1m', time_rule='9:40:00')
#设置预测模型
context.clf = AdaBoostClassifier(n_estimators=100, random_state=0)
#回测开始后前五个月左右训练模型,之后的时间每个月执行下单委托,所以这里要加一个判断的日期
#设置训练模型的时间,这里设置回测开始时间的20周
context.if_date=datetime.datetime.strptime(context.backtest_start_time,'%Y-%m-%d %H:%M:%S')+datetime.timedelta(weeks=20)
def algo_1(context):
#获取因子数据以上仅展示部分代码,完整代码请点击下方地址获取。
基于机器学习选股策略 - 掘金量化社区 - 量化交易者的交流社区掘金量化社区是量化投资者策略研讨、答疑解惑、资源共享的互动交流论坛。https://bbs.myquant.cn/topic/2382
声明:本内容首发至掘金量化公众号与掘金量化社区,仅供学习、交流、演示之用,不构成任何投资建议!如需转载原创文章请联系掘金小Q(myquant2018)。