文章目录
会议:2019 ICML
单位:University of Illinois at Urbana- Champaign & IBM
作者:Kaizhi Qian, Yang Zhang
- 可能有用的创新点:(1)encoder输入不仅有mel,还有编码后的src——
abstract
- 解决问题:non-parallel data, many-to-many VC,zero-shot VC
- 方法:通过一个AutoEncoder提取bn,使用self- reconstruction loss实现distribution- matching style transfer
1. introduction
VC可以看作是一个style transfer的问题。
- GAN方法是一种基于理论判别的方法,训练比较复杂,尽管图像上有很好的结果,但是目前的研究结果证明GAN生成的数据可能会骗过判别器,但是无法欺骗人耳。
- CVAE(conditional VAE)训练上相对简单,完成 self-reconstruction以及最大化输出概率的变分下界即可。原理是:预测一个假想的独立风格的hidden variable,然后拼上新的风格,就可以生成迁移风格之后的输出。但他不能确保分布一致性,并且输出会有over-smooth的情况。
- 是否有一种方法,像CVAE一样好训练,并可以像GAN一样满足分布一致性?
- AUTOVC使用了autoencoder的结构以及autoencoder loss,通过 carefully-tuned dimension reduction and temporal downsampling限制信息流。
3. Style Transfer Autoencoder
The Autoencoder Framework

- Es是预训练好的,Ec和Es的输入来自同一个人的不同句子
- U 说话人向量;Z 内容向量;X speech segment
- 问题定义:说话人U1变为说话人U2,如果U1/U2都是训练集已知的话,是multi-speaker VC的任务;如果U1或者U2是训练集unseen的,定义为zero-shot 的问题;
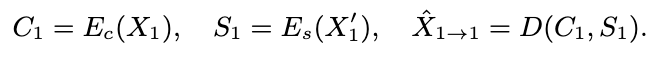

Why does it work?
理论依据:
- Es编码的是说话人信息,同一说话人的的spk_emb相同,不同说话人的spk_emb不同;

- 初衷:bn的维度设计的刚好只能编码说话人无关的信息;四张图的小标题配合Ec编码后结果非常生动
- 但实际上有矛盾点:重建效果很好,但是转换效果不好。
4. AUTOVC Architecture

- content encoder的输入: mel + Es(mel),输入了src说话人的向量;降采样过程时间维度抽帧,channel减少,提取出说话人无关的文本表征;
- decoder:首先预测mel80,然后过post-net,再预测一次;