2021SC@SDUSC

上篇,我们分析了DefaultAbstractBag,本篇,我们将分析三种"spillable"DataBag的实现
回忆一下类图
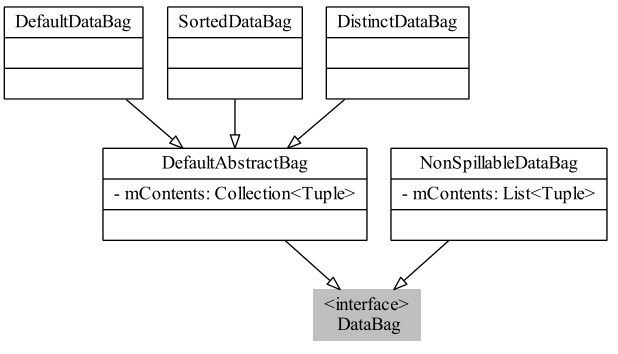
先去看看三种DataBag,三者继承于DefaultAbstractBag,DefaultAbstractBag实现DataBag接口,前篇已经对接口类、抽象类进行了分析,总结如下


其中,
以下三个接口是未实现的
+ isSorted(): boolean
+ isDistinct(): boolean
+ iterator: iterator<Tuple>
接下来分析DefaultDataBag源码
/**
* 具有多个元组(可能)的无序集合。元组存储在List中,因为不关心顺序或差异
*/
public class DefaultDataBag extends DefaultAbstractBag {
private static final long serialVersionUID = 2L;
private static final Log log = LogFactory.getLog(DefaultDataBag.class);
private static final InterSedes SEDES = InterSedesFactory.getInterSedesInstance();
public DefaultDataBag() {
mContents = new ArrayList<Tuple>();
}
/**
* 这个构造函数通过获得列表的所有权而不是复制列表的内容,从现有的元组列表中创建一个包
* @param listOfTuples List<Tuple> containing the tuples
*/
public DefaultDataBag(List<Tuple> listOfTuples) {
mContents = listOfTuples;
mSize = listOfTuples.size();
markSpillableIfNecessary();
}
@Override
public boolean isSorted() {
return false;
}
@Override
public boolean isDistinct() {
return false;
}
@Override
public Iterator<Tuple> iterator() {
return new DefaultDataBagIterator();
}
@Override
public long spill() {
// 确保我们有东西洒出来。不要创建空文件,那样会造成混乱。
if (mContents.size() == 0) return 0;
// 在溢出之前锁定容器,这样迭代器就不会在我摆弄容器时试图读取。
long spilled = 0;
synchronized (mContents) {
DataOutputStream out = null;
try {
out = getSpillFile();
} catch (IOException ioe) {
// 不要从溢出的数组中删除最后一个文件。它没有被添加为File。createTmpFile抛出IOException
warn(
"Unable to create tmp file to spill to disk", PigWarning.UNABLE_TO_CREATE_FILE_TO_SPILL, ioe);
return 0;
}
try {
Iterator<Tuple> i = mContents.iterator();
while (i.hasNext()) {
SEDES.writeDatum(out, i.next(), DataType.TUPLE);
spilled++;
// This will spill every 16383 records.
if ((spilled & 0x3fff) == 0) reportProgress();
}
out.flush();
out.close();
out = null;
mContents.clear();
} catch (Throwable e) {
//从溢出的数组中删除最后一个文件,因为我们没有写入它。
mSpillFiles.remove(mSpillFiles.size() - 1);
warn(
"Unable to spill contents to disk", PigWarning.UNABLE_TO_SPILL, e);
return 0;
} finally {
if (out != null) {
try {
out.close();
} catch (IOException e) {
warn("Error closing spill", PigWarning.UNABLE_TO_CLOSE_SPILL_FILE, e);
}
}
}
}
// 增加spill count
incSpillCount(PigCounters.SPILLABLE_MEMORY_MANAGER_SPILL_COUNT);
return spilled;
}
/**
*处理从包中获取下一个元组的迭代器。这个迭代器有两个问题需要处理。首先,数据可以同时存储在内存和磁盘中。第二,迭代器读取包时,可能会要求溢出。这意味着它将指向内存中的某个地方,然后突然需要切换到磁盘文件。
*/
private class DefaultDataBagIterator implements Iterator<Tuple> {
//我们必须缓冲一个元组,因为next没有简单的方法来判断是否有另一个元组可用,除了读取它。
private Tuple mBuf = null;
private int mMemoryPtr = 0;
private int mFilePtr = 0;
private DataInputStream mIn = null;
private int mCntr = 0;
private boolean hasCachedTuple = false;
DefaultDataBagIterator() {
}
@Override
public boolean hasNext() {
// 旦我们调用hasNext(),设置标志,这样我们就可以重复调用hasNext()而不获取下一个元组
if (hasCachedTuple)
return (mBuf != null);
mBuf = next();
hasCachedTuple = true;
return (mBuf != null);
}
@Override
public Tuple next() {
// 这将每1024次报告进展到下一次。
// 这应该比使用mod快得多.
if ((mCntr++ & 0x3ff) == 0) reportProgress();
// 如果缓冲里有一个,就用那个
if (hasCachedTuple) {
Tuple t = mBuf;
hasCachedTuple = false;
return t;
}
// 看看我们是否已经从内存读取过了
if (mMemoryPtr > 0) {
// 如果内存中还有数据,就从那里继续读取。
// 锁在我们检查大小之前,获取一个读取器锁,从这一点开始,我们不能让它们溢出
// us.
synchronized (mContents) {
if (mContents.size() > 0) {
return readFromMemory();
}
}
// 容器从上次读取后就溢出了。现在不需要锁住,因为它已经洒在我们身上了。我们的文件指针将已经指向新的spill文件(因为它要么已经是0,要么已经超过了旧的mSpillFiles.size()的末尾)。我们需要打开新文件,然后快进到我们已经读过的所有元组。然后我们需要重置mMemoryPtr,这样我们就知道下次通过时要从文件中读取。
try {
mIn = new DataInputStream(new BufferedInputStream(
new FileInputStream(mSpillFiles.get(mFilePtr++))));
} catch (FileNotFoundException fnfe) {
// 我们找不到自己的泄漏文件吗?这是不应该发生的。
String msg = "Unable to find our spill file.";
log.fatal(msg, fnfe);
throw new RuntimeException(msg, fnfe);
}
for (int i = 0; i < mMemoryPtr; i++) {
try {
SEDES.readDatum(mIn);
} catch (EOFException eof) {
// 这是不应该发生的,这意味着我们没有将所有元组转储到磁盘。
String msg = "Ran out of tuples to read prematurely.";
log.fatal(msg, eof);
throw new RuntimeException(msg, eof);
} catch (IOException ioe) {
String msg = "Unable to read our spill file.";
log.fatal(msg, ioe);
throw new RuntimeException(msg, ioe);
}
}
mMemoryPtr = 0;
return readFromFile();
}
//我们还没有从内存中读取,所以请继续尝试从文件中读取
return readFromFile();
}
/**
*不可执行.
*/
@Override
public void remove() {}
private Tuple readFromFile() {
if (mIn != null) {
// 我们已经有一个文件打开了
Tuple t;
try {
t = (Tuple) SEDES.readDatum(mIn);
return t;
} catch (EOFException eof) {
// 转到下一个例子,我们找到下一个文件,或者转到内存
try {
mIn.close();
}catch(IOException e) {
log.warn("Failed to close spill file.", e);
}
} catch (IOException ioe) {
String msg = "Unable to read our spill file.";
log.fatal(msg, ioe);
throw new RuntimeException(msg, ioe);
}
}
// 需要打开下一个文件,如果有的话。必须在这里锁定,否则我们可能会认为没有更多文件了,在我们决定这段时间和开始尝试从内存中读取之间容器可能溢出,然后我们就卡住了。如果还有其他文件要读,我们可以立即解锁。如果没有,我们需要持有锁并进入readFromMemory()
synchronized (mContents) {
if (mSpillFiles == null || mFilePtr >= mSpillFiles.size()) {
// 我们已经从文件中读取了所有要读取的东西,去内存中看看。
return readFromMemory();
}
}
// 打开下一个文件,然后再次调用我们自己,因为它将输入上面的if。
try {
mIn = new DataInputStream(new BufferedInputStream(
new FileInputStream(mSpillFiles.get(mFilePtr++))));
} catch (FileNotFoundException fnfe) {
// 我们找不到自己的泄漏文件吗?这是不应该发生的。
String msg = "Unable to find our spill file.";
log.fatal(msg, fnfe);
throw new RuntimeException(msg, fnfe);
}
return readFromFile();
}
// 只有当我们知道我们没有泄露的时候,才应该调用它。它假设在我们进入这个函数之前mContents锁已经被持有。
private Tuple readFromMemory() {
if (mContents.size() == 0) return null;
if (mMemoryPtr < mContents.size()) {
return ((List<Tuple>)mContents).get(mMemoryPtr++);
} else {
return null;
}
}
}
}
DefaultDataBag用ArrayList<Tuple>来存储内容,同时它是非独特、非排序的
接下来分析SortedDataBag源码
/**
* 有多个元组(可能)的有序集合。数据传入时存储为未排序的,只有在需要将其转储到文件或请求第一个迭代器时才进行排序。实验发现这比一开始存储它要快得多。
* 我们允许用户定义比较器,但在用户没有指定比较器的情况下提供默认比较器。 */
public class SortedDataBag extends DefaultAbstractBag{
private static final long serialVersionUID = 2L;
private static final InterSedes SEDES = InterSedesFactory.getInterSedesInstance();
private static final Log log = LogFactory.getLog(SortedDataBag.class);
transient private Comparator<Tuple> mComp;
private boolean mReadStarted = false;
private static class DefaultComparator implements Comparator<Tuple> {
@Override
@SuppressWarnings("unchecked")
public int compare(Tuple t1, Tuple t2) {
return t1.compareTo(t2);
}
@Override
public boolean equals(Object o) {
return false;
}
@Override
public int hashCode() {
return 42;
}
}
/**
* @param comp 用来进行排序的比较器。如果为空,
将使用DefaultComparator。
*/
public SortedDataBag(Comparator<Tuple> comp) {
mComp = (comp == null) ? new DefaultComparator() : comp;
mContents = new ArrayList<Tuple>();
}
@Override
public boolean isSorted() {
return true;
}
@Override
public boolean isDistinct() {
return false;
}
@Override
public Iterator<Tuple> iterator() {
return new SortedDataBagIterator();
}
@Override
public long spill() {
// 确保我们有东西洒出来。不要创建空文件,那样会造成混乱
if (mContents.size() == 0) return 0;
// 在溢出之前锁定容器,这样迭代器就不会在我摆弄容器时试图读取。
long spilled = 0;
synchronized (mContents) {
DataOutputStream out = null;
try {
out = getSpillFile();
} catch (IOException ioe) {
// 不要从溢出的数组中删除最后一个文件。它没有被添加为File。createTmpFile抛出IOException
warn(
"Unable to create tmp file to spill to disk", PigWarning.UNABLE_TO_CREATE_FILE_TO_SPILL, ioe);
return 0;
}
try {
// 我们得先整理数据,然后才能把它扔掉。我们要在密室里做这件事是假的,但没有别的办法。如果读取已经开始,那么我们已经对它排序了。没有理由再做一次。不要设置mReadStarted,因为我们可能仍然处于添加阶段,在这种情况下,稍后将添加更多(未排序的)内容。
if (!mReadStarted) {
Collections.sort((ArrayList<Tuple>)mContents, mComp);
}
Iterator<Tuple> i = mContents.iterator();
while (i.hasNext()) {
SEDES.writeDatum(out, i.next(), DataType.TUPLE);
spilled++;
// This will spill every 16383 records.
if ((spilled & 0x3fff) == 0) reportProgress();
}
out.flush();
out.close();
out = null;
mContents.clear();
} catch (Throwable e) {
// 从溢出的数组中删除最后一个文件,因为我们没有写入它。
mSpillFiles.remove(mSpillFiles.size() - 1);
warn(
"Unable to spill contents to disk", PigWarning.UNABLE_TO_SPILL, e);
return 0;
} finally {
if (out != null) {
try {
out.close();
} catch (IOException e) {
warn("Error closing spill", PigWarning.UNABLE_TO_CLOSE_SPILL_FILE, e);
}
}
}
}
// 增加spill count
incSpillCount(PigCounters.SPILLABLE_MEMORY_MANAGER_SPILL_COUNT);
return spilled;
}
/**
* 处理从包中获取下一个元组的迭代器。这个迭代器有两个问题需要处理。首先,数据可以同时存储在内存和磁盘中。第二,迭代器读取包时,可能会要求溢出。这意味着它将指向内存中的某个地方,然后突然需要切换到磁盘文件。
*/
private class SortedDataBagIterator implements Iterator<Tuple> {
/**
* 在优先队列中保存元组的容器。存储元组所在的文件号,以便当从队列中读取元组时,我们知道从哪个文件中读取替换元组。
*/
private class PQContainer implements Comparable<PQContainer> {
public Tuple tuple;
public int fileNum;
@Override
public int compareTo(PQContainer other) {
return mComp.compare(tuple, other.tuple);
}
@Override
public boolean equals(Object other) {
if (other instanceof PQContainer)
return tuple.equals(((PQContainer)other).tuple);
else
return false;
}
@Override
public int hashCode() {
return tuple.hashCode();
}
}
// 我们必须缓冲一个元组,因为next没有简单的方法来判断是否有另一个元组可用,除了读取它。
private Tuple mBuf = null;
private int mMemoryPtr = 0;
private PriorityQueue<PQContainer> mMergeQ = null;
private ArrayList<DataInputStream> mStreams = null;
private int mCntr = 0;
SortedDataBagIterator() {
// 如果这是第一次读取,我们需要对数据进行排序。
synchronized (mContents) {
if (!mReadStarted) {
preMerge();
Collections.sort((ArrayList<Tuple>)mContents, mComp);
mReadStarted = true;
}
}
}
@Override
public boolean hasNext() {
// 看看能不能找到一个元组。如果是,缓冲它.
mBuf = next();
return mBuf != null;
}
@Override
public Tuple next() {
//这将每1024次报告进展到下一次.
//这应该比使用mod快得多
if ((mCntr++ & 0x3ff) == 0) reportProgress();
//如果缓冲里有一个,就用那个
if (mBuf != null) {
Tuple t = mBuf;
mBuf = null;
return t;
}
//检查一下我们是否只需要从内存中读取。
boolean spilled = false;
synchronized (mContents) {
if (mSpillFiles == null || mSpillFiles.size() == 0) {
return readFromMemory();
}
// 检查我们是否从内存中读取,但我们溢出了
if (mMemoryPtr > 0 && mContents.size() == 0) {
spilled = true;
}
}
if (spilled) {
DataInputStream in;
// 我们需要打开新文件,然后快进到我们已经读过的所有元组。然后我们需要将该文件的第一个元组放到优先队列中。无论来自内存的元组已经在队列中,都是可以的,因为它们保证在我们快进的点之前。我们可以保证我们想要为快进读取的文件是mSpillFiles中的最后一个元素,因为我们不支持在调用iterator()之后调用add(),而且spill()不会创建空文件。
try {
in = new DataInputStream(new BufferedInputStream(
new FileInputStream(mSpillFiles.get(
mSpillFiles.size() - 1))));
if (mStreams == null) {
//这次泄漏之前我们没有任何文件
mMergeQ = new PriorityQueue<PQContainer>(1);
mStreams = new ArrayList<DataInputStream>(1);
}
mStreams.add(in);
} catch (FileNotFoundException fnfe) {
// 我们找不到自己的泄漏文件吗?这是不应该发生的。
String msg = "Unable to find our spill file.";
log.fatal(msg, fnfe);
throw new RuntimeException(msg, fnfe);
}
// 快进到我们已经放入队列的元组之后。
for (int i = 0; i < mMemoryPtr; i++) {
try {
SEDES.readDatum(in);
} catch (EOFException eof) {
// 这是不应该发生的,这意味着我们没有将所有元组转储到磁盘。
String msg = "Ran out of tuples to read prematurely.";
log.fatal(msg, eof);
throw new RuntimeException(msg, eof);
} catch (IOException ioe) {
String msg = "Unable to find our spill file.";
log.fatal(msg, ioe);
throw new RuntimeException(msg, ioe);
}
}
mMemoryPtr = 0;
// 将该文件中的下一个元组添加到队列中。
addToQueue(null, mSpillFiles.size() - 1);
// 从优先级队列中读取下一个条目。
}
// 我们有spill文件,所以我们需要从这些文件/其中之一或从内存中读取下一个元组。
return readFromPriorityQ();
}
/**
* 不可执行
*/
@Override
public void remove() {}
private Tuple readFromPriorityQ() {
if (mMergeQ == null) {
// 第一次读取时,我们需要设置文件流的队列和数组,在内存中为列表的大小加1。
mMergeQ =
new PriorityQueue<PQContainer>(mSpillFiles.size() + 1);
、
// 再加一个,以防以后洒出来
mStreams =
new ArrayList<DataInputStream>(mSpillFiles.size() + 1);
Iterator<File> i = mSpillFiles.iterator();
while (i.hasNext()) {
try {
DataInputStream in =
new DataInputStream(new BufferedInputStream(
new FileInputStream(i.next())));
mStreams.add(in);
// 将该文件中的第一个元组添加到合并队列中。
addToQueue(null, mStreams.size() - 1);
} catch (FileNotFoundException fnfe) {
// 我们找不到自己的泄漏文件吗?这是不应该发生的。
String msg = "Unable to find our spill file.";
log.fatal(msg, fnfe);
throw new RuntimeException(msg, fnfe);
}
}
// Prime one from memory too
if (mContents.size() > 0) {
addToQueue(null, -1);
}
}
// 把排在前面的那个拿出来
PQContainer c = mMergeQ.poll();
if (c == null) return null;
// 将从队列中读取的下一个元组添加到队列中。缓冲我们要返回的元组,因为我们要重用c
Tuple t = c.tuple;
addToQueue(c, c.fileNum);
return t;
}
private void addToQueue(PQContainer c, int fileNum) {
if (c == null) {
c = new PQContainer();
}
c.fileNum = fileNum;
if (fileNum == -1) {
// 需要从内存中读取。由于这个元组被放到队列中,我们可能已经溢出,因此内存可能是空的。但我不在乎,因为那样我就不会再从记忆中添加任何东西了。
synchronized (mContents) {
c.tuple = readFromMemory();
}
if (c.tuple != null) {
mMergeQ.add(c);
}
return;
}
// 从指定的文件中读取下一个元组
DataInputStream in = mStreams.get(fileNum);
if (in != null) {
// 这个文件里还有数据
try {
c.tuple = (Tuple) SEDES.readDatum(in);
mMergeQ.add(c);
} catch (EOFException eof) {
// 从该文件中的元组中取出。将数组中的slot设置为null,这样我们就不会一直试图从这个文件中读取数据。
try {
in.close();
}catch(IOException e) {
log.warn("Failed to close spill file.", e);
}
mStreams.set(fileNum, null);
} catch (IOException ioe) {
String msg = "Unable to find our spill file.";
log.fatal(msg, ioe);
throw new RuntimeException(msg, ioe);
}
}
}
// 函数假设在进入该函数之前读取器锁已经被持有。
private Tuple readFromMemory() {
if (mContents.size() == 0) return null;
if (mMemoryPtr < mContents.size()) {
return ((ArrayList<Tuple>)mContents).get(mMemoryPtr++);
} else {
return null;
}
}
/**
* 如果有太多的溢出文件,预合并。这避免了在我们的合并中有一个太大的风扇的问题。hadoop团队的实验表明,100是最优的溢出文件数量。这个函数修改mSpillFiles数组,并假设写锁已经被持有。它不会解锁它。元组被重新构造为元组、求值并被重写为元组。这是昂贵的,但我需要这样做,以使用提供给我的排序规范。
*/
private void preMerge() {
if (mSpillFiles == null ||
mSpillFiles.size() <= MAX_SPILL_FILES) {
return;
}
// 当有超过max spill文件,收集max spill文件在一起,并合并到一个文件。然后从mSpillFiles中删除其他文件。新的溢出文件附加在列表的末尾,所以我可以继续下去,直到我得到一个足够小的数字,而不用太担心大小不均匀的合并。将mSpillFiles转换为链表,因为我们将从中间删除片段,我们想要高效地做它。
try {
LinkedList<File> ll = new LinkedList<File>(mSpillFiles);
LinkedList<File> filesToDelete = new LinkedList<File>();
while (ll.size() > MAX_SPILL_FILES) {
ListIterator<File> i = ll.listIterator();
mStreams =
new ArrayList<DataInputStream>(MAX_SPILL_FILES);
mMergeQ = new PriorityQueue<PQContainer>(MAX_SPILL_FILES);
for (int j = 0; j < MAX_SPILL_FILES; j++) {
try {
File f = i.next();
DataInputStream in =
new DataInputStream(new BufferedInputStream(
new FileInputStream(f)));
mStreams.add(in);
addToQueue(null, mStreams.size() - 1);
i.remove();
filesToDelete.add(f);
} catch (FileNotFoundException fnfe) {
// 我们找不到自己的泄漏文件吗?这是不应该发生的。
String msg = "Unable to find our spill file.";
log.fatal(msg, fnfe);
throw new RuntimeException(msg, fnfe);
}
}
// 获取一个新的溢出文件。这将在溢出文件列表的末尾添加一个。我还需要把它添加到我的链表中这样当我把链表移回spill文件时它还在。
DataOutputStream out = null;
try {
out = getSpillFile();
ll.add(mSpillFiles.get(mSpillFiles.size() - 1));
Tuple t;
while ((t = readFromPriorityQ()) != null) {
t.write(out);
}
out.flush();
} catch (IOException ioe) {
String msg = "Unable to find our spill file.";
log.fatal(msg, ioe);
throw new RuntimeException(msg, ioe);
} finally {
try {
out.close();
} catch (IOException e) {
warn("Error closing spill", PigWarning.UNABLE_TO_CLOSE_SPILL_FILE, e);
}
}
}
// 删除已合并为新文件的文件
for(File f : filesToDelete){
if( f.delete() == false){
log.warn("Failed to delete spill file: " + f.getPath());
}
}
// 清除列表,以便当给mSpillFiles分配一个新值时,finalize不会删除任何文件
mSpillFiles.clear();
// 现在,将我们的新列表移回spill files数组
mSpillFiles = new FileList(ll);
} finally {
// 重置mStreams和mMerge,以便它们将被正确分配用于常规合并。
mStreams = null;
mMergeQ = null;
}
}
}
}
SortedDataBag使用ArrayList<Tuple>存储数据,并且在构造时并不会进行排序,只有在被使用的时候才会调用排序函数
篇幅原因,我们将在下一篇分析DistinctDataBag