前言:
本来想大概介绍一下,但是写着写着就多了,谢谢各位大佬们的博客,提供思路,本篇博客也是发挥了链接无处不在的特色,希望给大家带来帮助,
为什么最近(现在才感觉刚刚入门)开始频繁地写博客(另外有些事情需要外出、为了更好的给后面的人带来便利),我把整理的都写出来,给大家带来帮助皆大欢喜,没有帮助请勿吐槽,吐槽也没有关系,我尽量不因为外界而自讨没趣、生闷气
介绍
Logstash:数据处理引擎,可以处理每秒几万条的日志;它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到 ES
官网接受:图文并茂、很不错
日志搜集处理框架——[Logstash]使用详解
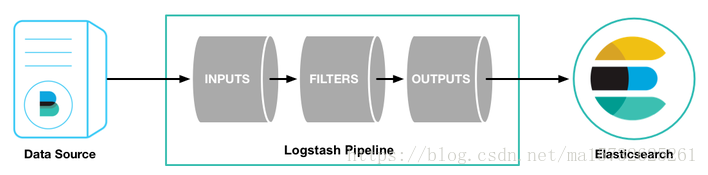
logstash做的事情分三个阶段依次执行:输入——》处理filter(不是必须)——》输出
使用管道方式进行日志的搜集处理和输出:有点类似*NIX系统的管道命令 xxx | ccc | ddd,xxx执行完了会执行ccc,然后执行ddd
如图:
安装
1、安装:可以下载tar.gz,一解压就可以了
2、命令安装:wget https://artifacts.elastic.co/downloads/logstash/logstash-5.2.1.tar.gz
详解:
logstash像上面说的支持动态的从各种数据源搜集数据
1、动态就是说通过相关的配置之后可以实时地收集指定的数据
2、各种数据源,这个怎么做到的呐?logstash用于收集的配置中有一个input,为了方便系统地了解,咱们还是上导图吧
为了方便管理咱们可以把他的配置单独的写一个文件就是配置文件啦(以.conf结尾的文件,用来管理输入、过滤器和输出相关的配置):
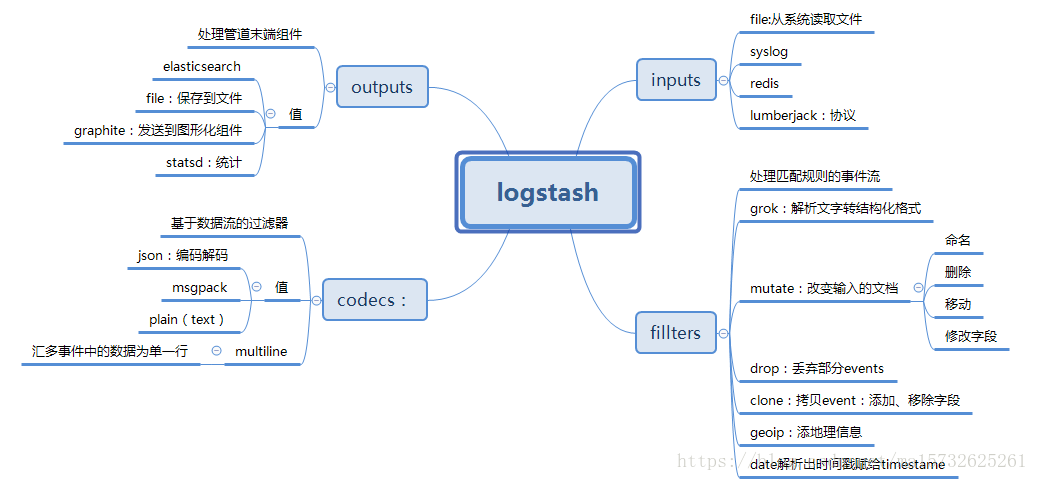
input接受数据的输入,分值的输入的方式(需要插件支持)
output输出文件到指定的地方,需要插件支持
filters和codecs:对数据进行过滤、分析、丰富、统一格式等操作
宏观的配置文件内容格式如下:
# 输入
input {
...
}
# 过滤器
filter {
...
}
# 输出
output {
...
}配置文件
其实上面已经开始说配置文件了;
目前我用的是比较简单的,就用到了一个grok,所以其他的有待研究
刚才在网上找了【关小西】的一篇博客,感觉挺不错的入门教程:
结合着大佬的博客,粘一个配置文件出来:
input {
# 从文件读取日志信息
file {
path => "/var/log/error.log"
type => "error"//type是给结果增加一个type属性,值为"error"的条目
start_position => "beginning"//从开始位置开始读取
# 使用 multiline 插件,传说中的多行合并
codec => multiline {
# 通过正则表达式匹配,具体配置根据自身实际情况而定
pattern => "^\d"
negate => true
what => "previous"
}
}
}
#可配置多种处理规则,他是有顺序,所以通用的配置写下面
# filter {
# grok {
# match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
# }
output {
# 输出到 elasticsearch
elasticsearch {
hosts => ["192.168.22.41:9200"]
index => "error-%{+YYYY.MM.dd}"//索引名称
}
} file {
type => "tms_inbound.log"
path => "/JavaWeb/tms2.wltest.com/logs/tms_inbound.es.*.log"
codec => json {
charset => "UTF-8"
}
}
file {
type => "tms_outbound.log"
path => "/JavaWeb/tms2.wltest.com/logs/tms_outbound.es.*.log"
codec => json {
charset => "UTF-8"
}
} 启动
接下来可以将文件保存为testLogs.conf文件,保存到logstash的bin路径下,进入logstash的bin路径下运行:
bin/logstash -f testLogs.conf
//如果放到conf文件夹下
bin/logstash -f conf/testLogs.conf//路径要对应上,这里是conf/testLogs.conflogstash 后可以加:
-f:指定配置文件,根据配置文件配置logstash
-e:字符串,配置,默认“”stdin输入、stdout输出(在控制台输入、输出),可通过命令行接受设置
-l:输出地址,默认控制台输出
-t:测试配置文件是否正确后退出
如:
bin/logstash -e 'input { stdin { } } output { stdout {} }'-e 可通过命令行接受设置
bin/logstash -e 'input { stdin { } } output { stdout { codec => rubydebug } }'
bin/logstash -e 'input { stdin { } } output { elasticsearch { host => localhost } }'也可以像上面说的写配置文件启动:
#写一个配置文件,放到bin目录下,启动
bin/logstash -f logstash-simple.conf
bin/logstash -f ./config/
bin/logstash -f etc/#加载 etc文件夹下所有 *.conf 的文本文件
#后台运行nohup bin/logstash -f etc/ &启动时不管指定了多少个配置文件,最后在启动的时候logstash会简单地将所有配置文件整合到了一起、编译成一个文件,不过不区分的话可能会有重复读取的问题(a文件执行走一遍、b文件执行走一遍:重复读取、嗯、没毛病),这种情况可以借助type(用法见上面的例子)或tags标签独立出不同源的数据,然后在output的时候、filter做grok正则解析的时候 借助if判断 来选择 不同的目的地 或索引
if "from_sys" in [tags]
#或者:
if [tags][0] == "achie_log"{
elasticsearch {
……
}
}
if [tags][0] == "exam_log"{
elasticsearch {
……
}
}插件安装
logstash默认支持一些插件(自带插件),但是如果您要用的插件,logstash本身没有,那就需要安装了:
首先为了防止下载过慢或者无法下载,咱们先改个地方:
进入logstash的安装目录,修改Gemfile命名的文件的source这一项,让插件从从国内下载:
source “https://ruby.taobao.org/”
安装命令:
1、从github中https://github.com/logstash-plugins 下载搜索关键字找到指定的插件,下载下来,相关主页下面有安装介绍
2、或者bin/plugin install 要安装的插件的名字
这个名字我一般从GitHub复制一下,拷贝过来,手动输担心错
这样就OK了,运行配置文件的时候如果是少插件,logstash会给出提示,根据提示安装相应的插件,相信大家的实力。
后语:
刚2018年4月21日12:50:53发现一个配置总结,一般常用的配置,借助这篇可以可以参考一下
搭建ELK(ElasticSearch+Logstash+Kibana)日志分析系统(十五) logstash将配置写在多个文件