一:需求与思路
需求:将新浪新闻的首页的所有新闻爬取到本地 http://news.sina.com.cn/
思路:首先爬首页,通过正则表达式获取所有的新闻链接,然后依次爬取新闻,并存储到本地。
二:实战
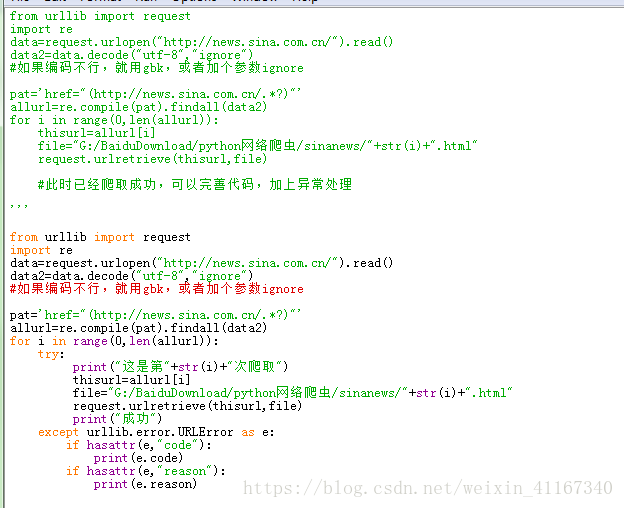
运行程序

查看爬取结果:

三:综上代码:
from urllib import request
import re
data=request.urlopen("http://news.sina.com.cn/").read()
data2=data.decode("utf-8","ignore")
pat='href="(http://news.sina.com.cn/.*?)"'
allurl=re.compile(pat).findall(data2)
for i in range(0,len(allurl)):
try:
print("这是第"+str(i)+"次爬取")
thisurl=allurl[i]file="G:/BaiduDownload/python网络爬虫/sinanews/"+str(i)+".html"
request.urlretrieve(thisurl,file)
print("成功")
except urllib.error.URLError as e:if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)