Docker实践(二):容器的管理(创建、查看、启动、终止、删除)_孤天浪雨的博客-CSDN博客_docker启动已经创建的容器
1、拖取镜像
我们决定使用上图中的 httpd 官方版本的镜像,使用命令 docker pull 来下载镜像:
网址:
Docker Hub
2、创建
后台型容器:运行在后台,创建后与终端无关,只有调用docker stop、docker kill命令才能使容器停止。
- d:使用-d参数,使容器在后台运行。
- c: 通过-c可以调整容器的CPU优先级。默认情况下,所有的容器拥有相同的CPU优先级和CPU调度周期,但你可以通过Docker来通知内核给予某个或某几个容器更多的CPU计算周期。比如,我们使用-c或者–cpu-shares =0启动了C0、C1、C2三个容器,使用-c/–cpu-shares=512启动了C3容器。这时,C0、C1、C2可以100%的使用CPU资源(1024),但C3只能使用50%的CPU资源(512)。如果这个主机的操作系统是时序调度类型的,每个CPU时间片是100微秒,那么C0、C1、C2将完全使用掉这100微秒,而C3只能使用50微秒。
- -c后的命令是循环,从而保持容器的运行。
3、使用docker的命令,查看现有镜像和正在运行的容器
- docker images: 查看所有镜像
docker ps: 查看当前运行的容器docker ps -a:查看所有容器,包括停止的。
4、使用镜像运行容器:

标题含义:
- CONTAINER ID:容器的唯一表示ID。
- IMAGE:创建容器时使用的镜像。
- COMMAND:容器最后运行的命令。
- CREATED:创建容器的时间。
- STATUS:容器状态。
- PORTS:对外开放的端口。
- NAMES:容器名。可以和容器ID一样唯一标识容器,同一台宿主机上不允许有同名容器存在,否则会冲突。
这里注意,一定要添加“--gpus all ”否则无法使用GPU,也就CUDA不可用!!!
docker run --runtime=nvidia --gpus all --name=pytorch_gpu -d -t -i pytorch/pytorch:1.11.0-cuda11.3-cudnn8-devel /bin/bash
直接运行使用镜像生成的容器:
-
docker attach
-
docker exec:推荐大家使用 docker exec 命令,因为此退出容器终端,不会导致容器的停止。
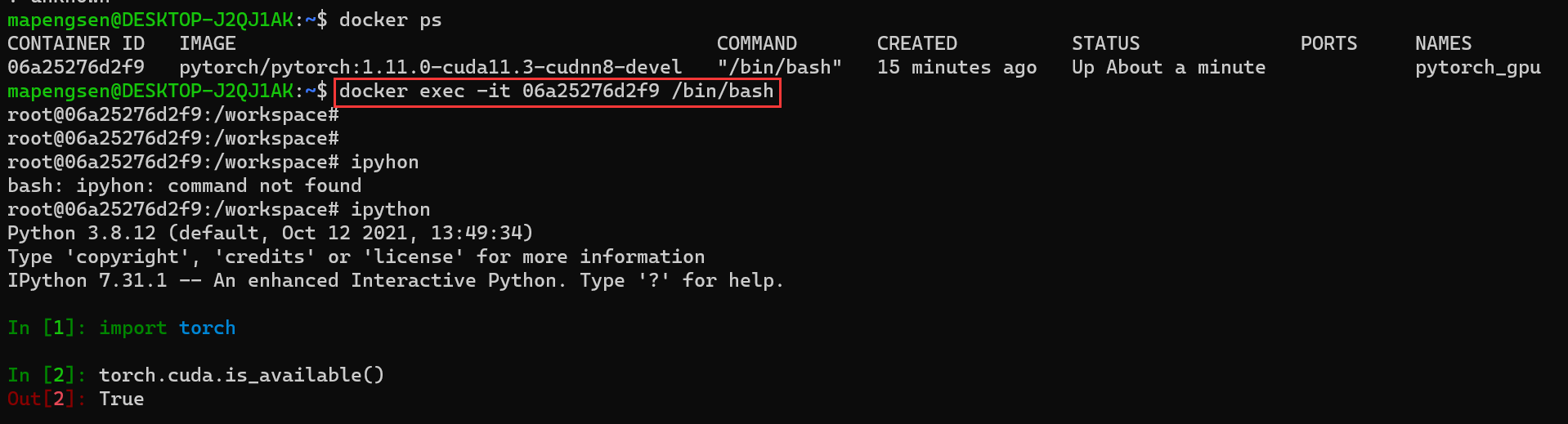
docker exec -it 06a25276d2f9 /bin/bash
这里要注意/bin/bash要和docker容器中的命令一致
import torch
torch.cuda.is_available()
5、启动容器:
三、启动
通过docker start来启动之前已经停止的docker_run镜像。
容器名:docker start docker_run,或者ID:docker start 43e3fef2266c。
–restart(自动重启):默认情况下容器是不重启的,–restart标志会检查容器的退出码来决定容器是否重启容器。
- docker run --restart=always --name docker_restart -d centos /bin/sh -c "while true;do echo hello world; sleep;done":
- --restart=always:不管容器的返回码是什么,都会重启容器。
- --restart=on-failure:5:当容器的返回值是非0时才会重启容器。5是可选的重启次数。
5、删除镜像:
镜像删除使用 docker rmi 命令,比如我们删除 hello-world 镜像:
docker rmi hello-world

删除容器:
镜像删除使用 docker rm 命令(不能够删除一个正在运行的容器,会报错。需要先停止容器),比如我们删除 这个容器:
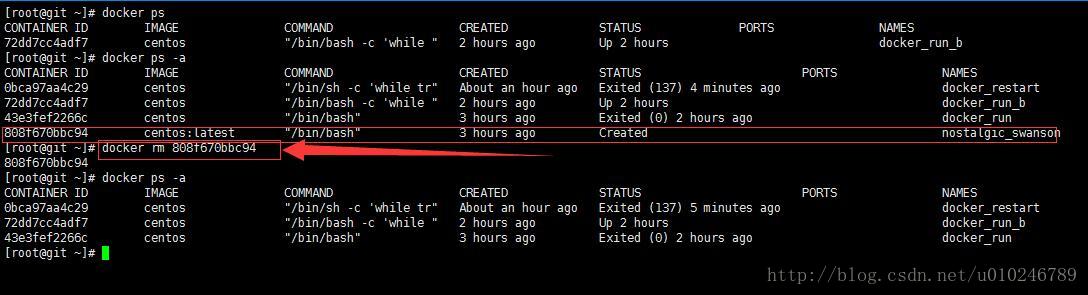
docker rm 808f670bbc94