3. Deep Residual Learning
3.1. Residual Learning
将 H ( x ) \mathcal{H}(\mathbf{x}) H(x)视为由几个堆叠层(不一定是整个网络)拟合的底层映射,其中 x \mathrm{x} x表示这些层中第一层的输入。如果假设多个非线性层可以渐近逼近复杂函数,那么就相当于假设它们可以渐近逼近残差函数,即 H ( x ) − x \mathcal{H}(\mathbf{x})-\mathbf{x} H(x)−x(假设输入和输出具有相同的维度)。因此,不期望堆叠层逼近 H ( x ) \mathcal{H}(\mathbf{x}) H(x),而是明确地让这些层逼近残差函数 F ( x ) : = H ( x ) − x \mathcal{F}(\mathbf{x}):=\mathcal{H}(\mathbf{x})-\mathbf{x} F(x):=H(x)−x。因此,原始函数变为 F ( x ) + x \mathcal{F}(\mathbf{x})+\mathbf{x} F(x)+x。尽管这两种形式都应该能够渐近地逼近所需的函数(如假设的那样),但学习的难易程度可能有所不同。
这种重构的动机是关于退化问题的违反直觉的现象(图 1,左)。正如introduction中所讨论的,如果添加的层可以重构为恒等映射,那么更深的模型应该具有不大于其较浅模型的训练误差。退化问题表明求解器可能难以通过多个非线性层来近似恒等映射。通过残差学习重构,如果恒等映射是最优的,求解器可以简单地将多个非线性层的权重推向零以接近恒等映射。
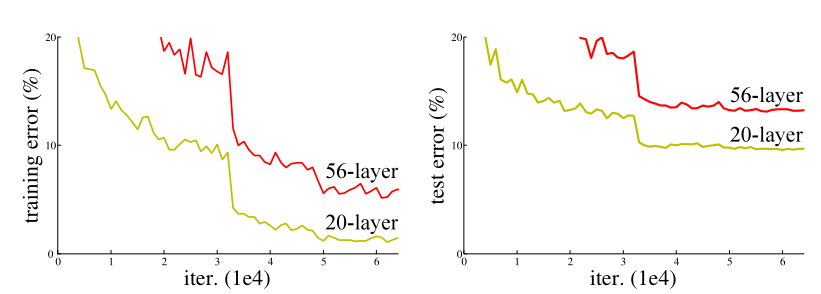
图 1. 具有 20 层和 56 层“plain”网络的 CIFAR-10 上的训练错误(左)和测试错误(右)。更深的网络有更高的训练误差,因此也有测试误差。 ImageNet 上的类似现象如图 4 所示。
在实际情况下,恒等映射不太可能是最优的,但作者的重构可能有助于解决问题。如果最优函数更接近于恒等映射而不是零映射,则求解器应该更容易参考恒等映射找到扰动,而不是将函数作为新函数来学习。通过实验(图 7)表明,学习到的残差函数通常具有较小的响应,这表明恒等映射提供了合理的预处理。
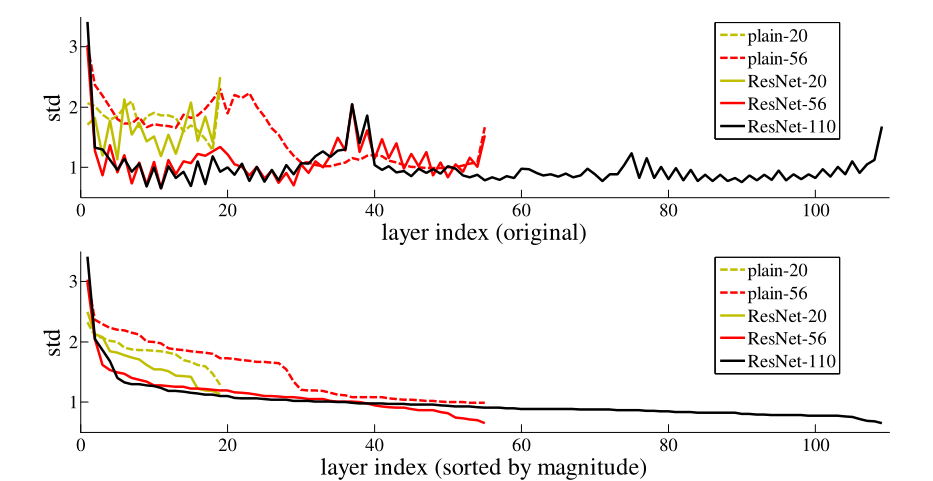
图 7. CIFAR10 上层响应的标准偏差 (std)。响应是每个 3 × 3 3 \times 3 3×3层的输出,在 BN 之后和非线性之前。顶部:图层以其原始顺序显示。底部:响应按降序排列。
3.2. Identity Mapping by Shortcuts
对每几个堆叠的层采用残差学习。一个构建块如图 2 所示。本文一个构建块定义为:
y = F ( x , { W i } ) + x ( 1 ) \mathbf{y}=\mathcal{F}\left(\mathbf{x},\left\{W_{i}\right\}\right)+\mathbf{x} \quad(1) y=F(x,{
Wi})+x(1)
这里 x \mathbf{x} x和 y \mathbf{y} y是构建块的输入和输出向量。函数 F ( x , { W i } ) \mathcal{F}\left(\mathbf{x},\left\{W_{i}\right\}\right) F(x,{
Wi})表示要学习的残差映射。图2中具有两层的示例, F = W 2 σ ( W 1 x ) \mathcal{F}=W_{2} \sigma\left(W_{1} \mathbf{x}\right) F=W2σ(W1x),其中 σ \sigma σ表示ReLU,并且为了简化符号省略了偏差。操作 F + x \mathcal{F}+\mathbf{x} F+x是通过快捷连接和元素相加来执行的。采用加法后的第二个非线性(即 σ ( y ) \sigma(\mathbf{y}) σ(y),见图2)。
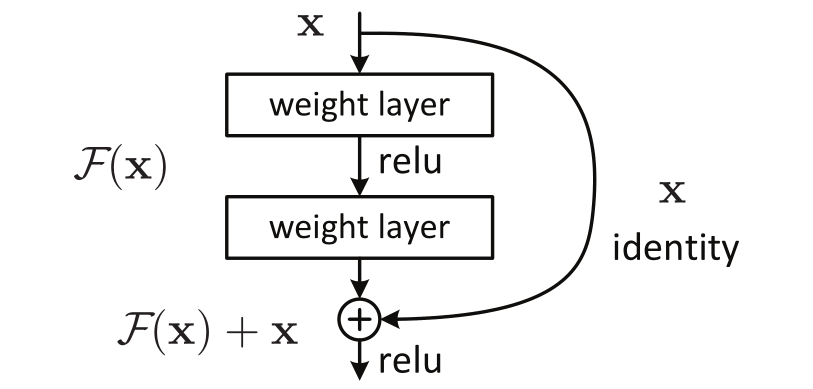
图2。残差学习:一个构建块。
等式(1)中的快捷连接既没有引入额外的参数,也没有引入计算复杂度。这不仅在实践中很有吸引力,而且在比较普通网络和残差网络时也很重要。可以公平地比较同时具有相同数量的参数、深度、宽度和计算成本的普通/残差网络(除了可忽略的元素加法)。
x \mathbf{x} x和 F \mathcal{F} F的维度在等式(1)中必须相等。如果不是这种情况(例如,当改变输入/输出通道时),可以通过快捷连接执行线性投影 W s W_{s} Ws以匹配维度:
y = F ( x , { W i } ) + W s x ( 2 ) \mathbf{y}=\mathcal{F}\left(\mathbf{x},\left\{W_{i}\right\}\right)+W_{s} \mathbf{x} \quad (2) y=F(x,{
Wi})+Wsx(2)
也可以在等式(1)中使用方阵 W s W_{s} Ws。但是作者将通过实验证明恒等映射足以解决退化问题并且是经济可行的,因此 W s W_{s} Ws仅在匹配维度时使用。残差函数 F \mathcal{F} F的形式是灵活的。本文中的实验涉及具有两层或三层的函数 F \mathcal{F} F(图 5),而更多层也是可能的。但是如果 F \mathcal{F} F只有一个层,等式(1)类似于线性层: y = W 1 x + x \mathbf{y}=W_{1} \mathbf{x}+\mathbf{x} y=W1x+x,作者没有观察到它的优势。
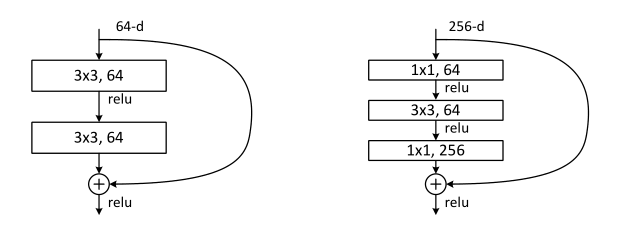
图 5. ImageNet 的更深的残差函数 F。左图:ResNet34 的构建块(在 56 × 56 56 \times 56 56×56特征图上),如图 3 所示。右图:ResNet-50/101/152 的“瓶颈”构建块。
作者还注意到,尽管为简单起见,上述符号是关于全连接层的,但它们适用于卷积层。函数 F ( x , { W i } ) \mathcal{F}\left(\mathbf{x},\left\{W_{i}\right\}\right) F(x,{ Wi})可以表示多个卷积层。逐通道地在两个特征图上执行元素相加。
3.3. Network Architectures
作者测试了各种普通/残差网络,并观察到一致的现象。为了提供讨论的实例,表述了 ImageNet 的两个模型,如下所示。
Plain Network. 普通baseline(图 3,中)主要受到 VGG 网络(图 3,左)哲学的启发。卷积层大多具有 3 × 3 3 \times 3 3×3滤波器,并遵循两个简单的设计规则:(i)对于相同的输出特征图大小,各层具有相同数量的滤波器; (ii) 如果特征图大小减半,则滤波器的数量加倍,以保持每层的时间复杂度。直接通过步长为 2 的卷积层执行下采样。网络以全局平均池化层和带有 softmax 的 1000 路全连接层结束。图 3(中)中加权层的总数为 34。
值得注意的是,本文的普通baseline比 VGG 网络具有更少的滤波器和更低的复杂性(图 3,左)。本文的 34 层baseline有 36 亿次 FLOP(乘加),这只是 VGG-19(196 亿次 FLOP)的 18%。
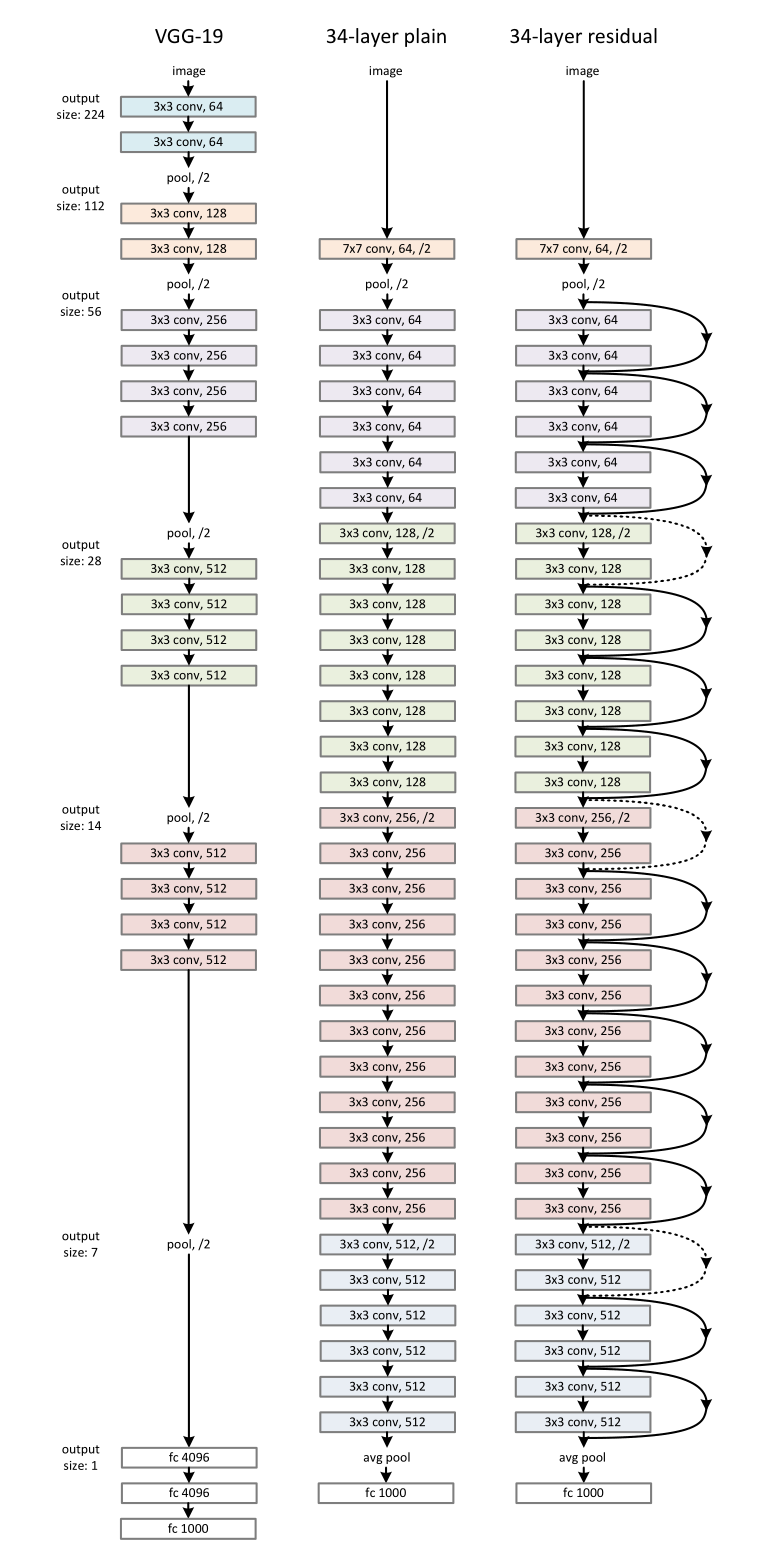
图 3. ImageNet 的示例网络架构。左:作为参考的 VGG-19 模型(196 亿 FLOPs)。中间:具有 34 个参数层(36 亿次浮点运算)的普通网络。右图:具有 34 个参数层(36 亿次浮点运算)的残差网络。虚线的快捷方式增加了维度。表 1 显示了更多细节和其他变体。
Residual Network. 在上述普通网络的基础上,插入快捷连接(图 3,右),将网络转换为对应的残差版本。当输入和输出具有相同的维度时,可以直接使用恒等快捷方式(等式(1))(图 3 中的实线快捷方式)。当维度增加时(图 3 中的虚线快捷方式),考虑两个选项:(A)快捷方式仍然执行恒等映射,为增加维度填充额外的零。该选项不引入额外参数; (B) 等式(2) 中的投影快捷方式用于匹配维度(通过 1 × 1 1\times 1 1×1卷积完成)。对于这两个选项,当快捷方式跨越两种大小的特征图时,它们以 2 的步幅执行。
3.4. Implementation
对 ImageNet 的实现遵循 [21, 41] 中的实践。调整图像大小,其较短的边在 [ 256 , 480 ] [256,480] [256,480]中随机采样以进行缩放[41]。从图像或其水平翻转中随机采样 224 × 224 224 \times 224 224×224裁剪,减去每像素平均值 [21]。使用[21]中的标准颜色增强。在每个卷积之后和激活之前,在 [16] 之后立即采用批量归一化 (BN) [16]。像 [13] 中那样初始化权重,并从头开始训练所有普通/残差网络。使用小批量大小为 256 的 SGD。学习率从 0.1 开始,当误差达到稳定水平时除以 10,模型被训练最多 60 × 1 0 4 60 \times 10^{4} 60×104次迭代。使用 0.0001 的权重衰减和 0.9 的动量。不使用 dropout [14],遵循 [16] 中的做法。
在测试中,对于比较研究,采用标准的10-crop测试。为了获得最佳结果,采用 [41, 13] 中的全卷积形式,并在多个尺度上平均分数(调整图像大小,使较短的边在 { 224 , 256 , 384 , 480 , 640 } \{224,256,384,480,640\} { 224,256,384,480,640})。
参考文献
[13] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, 2015.
[14] G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov. Improving neural networks by preventing coadaptation of feature detectors. arXiv:1207.0580, 2012.
[16] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.
[21] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
[41] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.