本帖为学习笔记帖,参照b站解读西瓜书、haoyutiangang以及课堂的内容来记的,如有漏错,欢迎批评指正。
在了解决策树之前,一些概念需要知道:
Question1:什么是信息熵?
熵:对一种事物的不确定性叫做熵,或者说混乱程度。
信息:
- 消除不确定性的事物
- 调整概率
- 排除干扰
- 确定情况
噪音:不能消除不确定性的事物
数据=信息+噪音
信息熵(information entropy):是度量样本集合纯度最常用的一种指标。
Question2:熵如何量化?
参照一个不确定的事件作为单位:如抛硬币,我的不确定性相当于抛几次硬币的不确定性。如果是一枚硬币,50%正,50%反,就相当于一次抛硬币的不确定性,记为1bit。2枚硬币就是4种结果,3枚8种,以此类推,因此,抛硬币的次数与结果不确定性成指数关系。
概率均匀分布的情况:
有m种不确定情况,此时的需要抛 n = log 2 m n=\log_2^m n=log2m 枚硬币,那么此时的熵就是 n n n bit。
每种情况概率不相等情况:
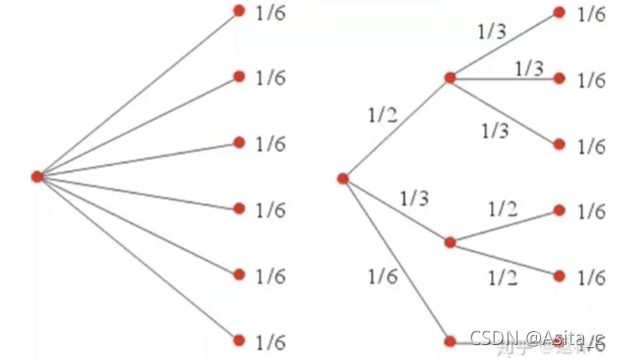
此时有三种情况,分布p分别为:1/2、1/3、1/6,我们这三种情况分别都拆成概率为1/6的情况,就近似转换成了左图的等概率情况,但实际上不是等概率,因此,我们就可以借助等概率情况来计算不等概率情况。
当分布为1/2时,此时需要的硬币为: log 2 6 − log 2 3 \log_2^6-\log_2^3 log26−log23(因为后面三种其实是一种情况),同理,分布为1/3为: log 2 6 − log 2 2 \log_2^6-\log_2^2 log26−log22,分布为1/6为: log 2 6 − log 2 1 \log_2^6-\log_2^1 log26−log21,因此左图总的需要硬币个数为(熵): 1 2 ( log 2 6 − log 2 3 ) + 1 3 ( log 2 6 − log 2 2 ) + 1 6 ( log 2 6 − log 2 1 ) = 1 2 log 2 ( 2 / 1 ) + 1 3 log 2 ( 3 / 1 ) + 1 6 log 2 ( 3 / 1 ) \frac{1}{2}(\log_2^6-\log_2^3)+\frac{1}{3}(\log_2^6-\log_2^2)+\frac{1}{6}(\log_2^6-\log_2^1)=\frac{1}{2}\log_2^{(2/1)}+\frac{1}{3}\log_2^{(3/1)}+\frac{1}{6}\log_2^{(3/1)} 21(log26−log23)+31(log26−log22)+61(log26−log21)=21log2(2/1)+31log2(3/1)+61log2(3/1)
因此,信息熵( D D D)公式为:
E n t ( D ) = − ∑ k = 1 ∣ Y ∣ p k log 2 p k \mathbf{Ent}(D)=-\sum_{k=1}^{ \vert \mathcal{Y} \vert}p_k\log_2^{p_k} Ent(D)=−k=1∑∣Y∣pklog2pk
E n t ( D ) \mathbf{Ent}(D) Ent(D) 越小,则 D D D 的纯度越高。
信息如何量化:
例:小明不知道选择题(等概率事件)是ABCD哪个选项正确时的熵: log 2 4 = 2 \log_2^4=2 log24=2
告诉小明C有一半概率是正确的,小明知道C有一般概率后的不确定性(熵): 1 6 log 2 6 + 1 6 log 2 6 + 1 2 log 2 2 + 1 6 log 2 6 = 1.79 \frac{1}{6}\log_2^6+\frac{1}{6}\log_2^6+\frac{1}{2}\log_2^2+\frac{1}{6}\log_2^6=1.79 61log26+61log26+21log22+61log26=1.79,因此,告诉小明C有一半概率是正确的相当于提供的信息为: 2 − 1.79 = 0.21 2-1.79=0.21 2−1.79=0.21
信息增益(ID3):
西瓜书上的定义是这样的:
假定离散属性 a a a 有 V V V 个可能的取值 { a 1 , a 2 , . . . , a V } \{a^1,a^2,...,a^V\} {
a1,a2,...,aV},若使用 a a a 来对样本集 D D D 进行划分,则会产生 V V V 个分支结点,其中,第 v v v 个分支结点包含了 D D D 中所有在属性 a a a 上的取值为 a v a^v av 的样本,记为 D v D^v Dv。我们根据信息熵的公式,再考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重 ∣ D v ∣ / ∣ D ∣ \vert D^v \vert / \vert D \vert ∣Dv∣/∣D∣,即样本数越多的分支结点的影响越大,于是可计算出属性 a a a 对样本集 D D D 的“信息增益”(information gain)
G a i n ( D , a ) = E n t ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) \mathbf{Gain}(D,a)=\mathbf{Ent}(D)-\sum_{v=1}^V\frac{\vert D^v \vert}{\vert D\vert}\mathbf{Ent}(D^v) Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
**注:**这里由引出了一个概念:条件熵
条件熵
条件熵 H ( Y ∣ X ) H(Y\vert X) H(Y∣X) 表示在已知随机变量 X X X 的条件下随机变量 Y Y Y 的不确定性。记为随机变量 X X X 给定条件下的随机变量 Y Y Y 的条件熵 H ( Y ∣ X ) H(Y\vert X) H(Y∣X)
推导:
H ( Y ∣ X ) = ∑ x ∈ X p ( x ) H ( Y ∣ X = x ) = − ∑ x ∈ X p ( x ) ∑ y ∈ Y p ( y ∣ x ) log p ( y ∣ x ) = − ∑ x ∈ X ∑ y ∈ Y p ( x , y ) log p ( y ∣ x ) \begin{aligned} H(Y\vert X) &=\sum_{x \in X}p(x)H(Y\vert X=x)\\ &=-\sum_{x \in X}p(x)\sum_{y \in Y}p(y \vert x)\log p(y\vert x)\\ &=-\sum_{x\in X}\sum_{y\in Y}p(x,y)\log p(y\vert x) \end{aligned} H(Y∣X)=x∈X∑p(x)H(Y∣X=x)=−x∈X∑p(x)y∈Y∑p(y∣x)logp(y∣x)=−x∈X∑y∈Y∑p(x,y)logp(y∣x)
其中 H ( X ) H( X) H(X) 表示的是信息熵 ⟺ \iff ⟺ E n t ( D ) \mathbf{Ent}(D) Ent(D) (一个意思不同描述);
所以:条件熵也可以写成:
∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) \sum_{v=1}^V\frac{\vert D^v \vert}{\vert D\vert}\mathbf{Ent}(D^v) v=1∑V∣D∣∣Dv∣Ent(Dv)
所以:信息增益=信息熵-条件熵
以一个具体的例子来计算信息增益,具体详情在西瓜书 P 75 P_{75} P75~ P 77 P_{77} P77 页
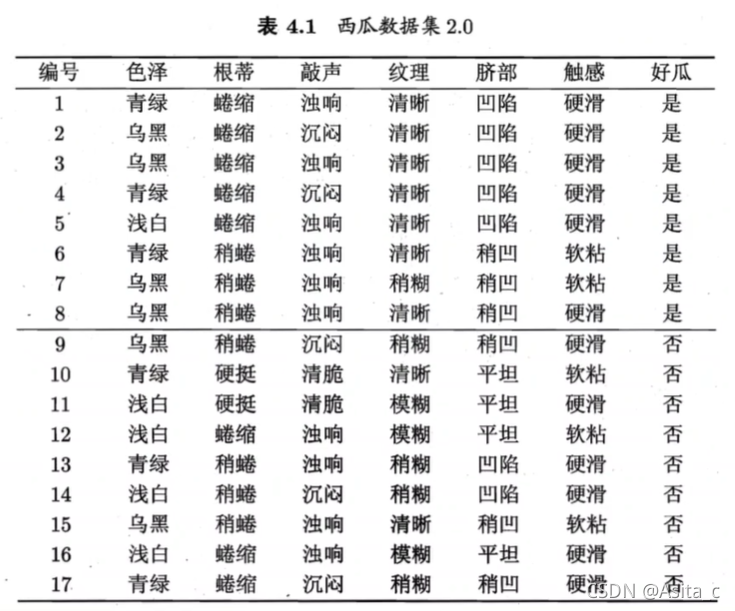
正例 p 1 = 8 17 p_1=\frac{8}{17} p1=178,反例 p 2 = 9 17 p_2=\frac{9}{17} p2=179
根结点的信息熵为:
E n t ( D ) = − ∑ k = 1 2 p k log 2 P k = − ( 8 17 log 2 8 17 + 9 17 log 2 9 17 ) = 0.998 \begin{aligned} \mathbf{Ent}(D)&=-\sum_{k=1}^2p_k\log_2^{P_k}\\ &=-\left( \frac{8}{17}\log_2^{\frac{8}{17}} +\frac{9}{17}\log_2^{\frac{9}{17}}\right)\\ &=0.998 \end{aligned} Ent(D)=−k=1∑2pklog2Pk=−(178log2178+179log2179)=0.998
以色泽为例,计算色泽的信息增益:
色泽有3种:青绿、乌黑、浅白,三种颜色的子集分别记为 D 1 , D 2 , D 3 D^1,D^2,D^3 D1,D2,D3
三个分支结点的信息熵为:
E n t ( D 1 ) = − ( 3 6 log 2 3 6 + 3 6 log 2 3 6 ) = 1.000 \mathbf{Ent}(D^1)=-\left( \frac{3}{6}\log_2{\frac{3}{6}}+\frac{3}{6}\log_2{\frac{3}{6}} \right)=1.000 Ent(D1)=−(63log263+63log263)=1.000
E n t ( D 2 ) = − ( 4 6 log 2 4 6 + 2 6 log 2 2 6 ) = 0.918 \mathbf{Ent}(D^2)=-\left( \frac{4}{6}\log_2{\frac{4}{6}}+\frac{2}{6}\log_2{\frac{2}{6}} \right)=0.918 Ent(D2)=−(64log264+62log262)=0.918
E n t ( D 3 ) = − ( 1 5 log 2 1 5 + 4 5 log 2 4 5 ) = 0.722 \mathbf{Ent}(D^3)=-\left( \frac{1}{5}\log_2{\frac{1}{5}}+\frac{4}{5}\log_2{\frac{4}{5}} \right)=0.722 Ent(D3)=−(51log251+54log254)=0.722
属性“色泽”的信息增益为:
G a i n ( D , 色 泽 ) = E n t ( D ) − ∑ v = 1 3 ∣ D v ∣ ∣ D ∣ E n t ( D v ) = 0.998 − ( 6 17 ∗ 1.000 + 6 17 ∗ 0.918 + 5 17 ∗ 0.722 ) = 0.109 \begin{aligned} \mathbf{Gain}(D,色泽)&=\mathbf{Ent}(D)-\sum_{v=1}^3 \frac{\vert D^v \vert}{\vert D \vert}\mathbf{Ent}(D^v)\\ &=0.998-\left( \frac{6}{17}*1.000+\frac{6}{17}*0.918+\frac{5}{17}*0.722 \right)\\ &=0.109 \end{aligned} Gain(D,色泽)=Ent(D)−v=1∑3∣D∣∣Dv∣Ent(Dv)=0.998−(176∗1.000+176∗0.918+175∗0.722)=0.109
同理,其他属性的信息增益为:
G a i n ( D , 根 蒂 ) = 0.143 ; G a i n ( D , 敲 声 ) = 0.141 ; \mathbf{Gain}(D,根蒂)=0.143;\mathbf{Gain}(D,敲声)=0.141; Gain(D,根蒂)=0.143;Gain(D,敲声)=0.141;
G a i n ( D , 纹 理 ) = 0.318 ; G a i n ( D , 脐 部 ) = 0.289 ; \mathbf{Gain}(D,纹理)=0.318;\mathbf{Gain}(D,脐部)=0.289; Gain(D,纹理)=0.318;Gain(D,脐部)=0.289;
G a i n ( D , 触 感 ) = 0.006 ; \mathbf{Gain}(D,触感)=0.006; Gain(D,触感)=0.006;
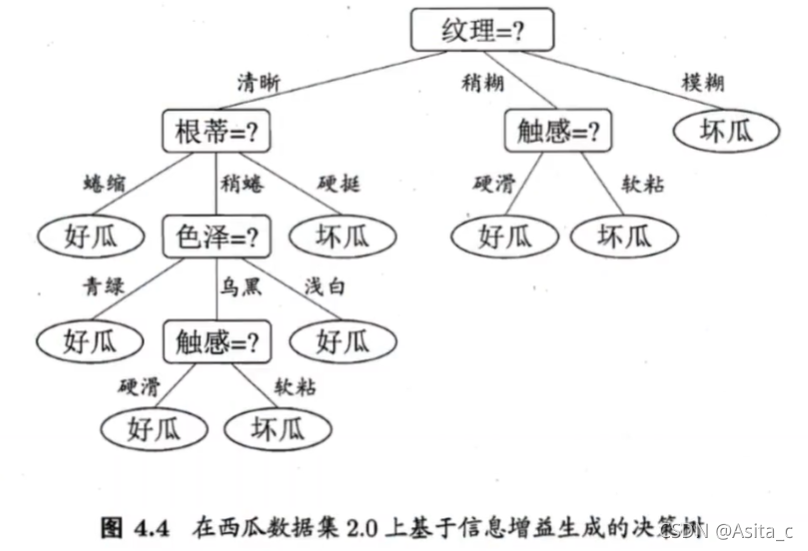
属性“纹理”的信息增益最大,因此作为第一层的划分属性,然后根据纹理属性的三个取值的基础上,继续求信息增益,一直下去得到的决策树为:
信息增益率( C 4.5 \mathbf{C4.5} C4.5)
由于信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的 C 4.5 \mathbf{C4.5} C4.5 决策树算法不直接使用信息增益,而是使用“增益率”来选择最优划分属性,增益率定义为:
G a i n _ r a t i o ( D , a ) = G a i n ( D , a ) I V ( a ) \mathbf{Gain}\_\mathbf{ratio}(D,a)=\frac{\mathbf{Gain}(D,a)}{\mathbf{IV}(a)} Gain_ratio(D,a)=IV(a)Gain(D,a)
其中, I V ( a ) = − ∑ v = 1 V ∣ D V ∣ ∣ D ∣ log 2 ∣ D v ∣ ∣ D ∣ \mathbf{IV}(a)=-\sum_{v=1}^V\frac{\vert D^V \vert}{\vert D \vert}\log_2^{\frac{\vert D^v \vert}{\vert D \vert}} IV(a)=−v=1∑V∣D∣∣DV∣log2∣D∣∣Dv∣, I V ( a ) \mathbf{IV}(a) IV(a) 表示属性 a a a 的固有值,属性 a a a 的可能取值数目越多(即 V V V越大),则 I V ( a ) \mathbf{IV}(a) IV(a) 的通常值越大,所以信息增益率可以起到“惩罚”个数多的属性的目的。
使用方法: [ Q u i n l a n , 1993 ] [\mathbf{Quinlan,1993}] [Quinlan,1993] :先从候选划分属性中找出信息增益高于平均水平的属性,再从中选取增益率高的。
基尼指数
C A R T \mathbf{CART} CART 决策树 [ B r e i m a n e t a l . , 1984 ] [\mathbf{Breiman \ et \ al., \ 1984}] [Breiman et al., 1984] 使用“基尼系数”( G i n i i n d e x \mathbf{Gini \ index} Gini index)来选择划分属性。数据集“ D D D” 的纯度可用基尼值来度量:
G i n i ( D ) = ∑ k = 1 ∣ Y ∣ ∑ k , ≠ k p k p k , = 1 − ∑ k = 1 Y p k 2 \begin{aligned} \mathbf{Gini}(D)&=\sum_{k=1}^{\vert \mathcal{Y} \vert} \sum_{k^{,} \neq k}p_kp_{k^,}\\ &=1-\sum_{k=1}^{\mathcal{Y}}p_k^2 \end{aligned} Gini(D)=k=1∑∣Y∣k,=k∑pkpk,=1−k=1∑Ypk2
G i n i ( D ) \mathbf{Gini}(D) Gini(D) 反映了从数据集 D D D 中随机抽取两个样本,其类别标记不一样的概率,即 G i n i ( D ) \mathbf{Gini}(D) Gini(D) 越小,数据集 D D D 纯度越高。
属性 a a a 的基尼指数定义为:
G i n i _ i n d e x ( D , a ) = ∑ v = 1 V ∣ D v ∣ ∣ D ∣ G i n i ( D v ) \mathbf{Gini\_index}(D,a)=\sum_{v=1}^{V}\frac{\vert D^v \vert}{\vert D \vert}\mathbf{Gini}(D^v) Gini_index(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)
因此,在候选集合 A A A 中应该选择使得划分后基尼系数最小的属性作为最优划分属性,即:
a ∗ = arg min a ∈ A G i n i _ i n d e x ( D , a ) a_*=\argmin_{a \in A}\mathbf{Gini\_index}(D,a) a∗=a∈AargminGini_index(D,a)
以下是三种基本算法的决策树的区别
| 算法 | 支持模型 | 树结构 | 特征选择 | 连续值处理 | 缺失值处理 | 剪枝 | 特征属性多次使用 |
|---|---|---|---|---|---|---|---|
| ID3 | 分类 | 多叉树 | 信息增益 | 不支持 | 不支持 | 不支持 | 不支持 |
| C4.5 | 分类 | 多叉树 | 信息增益率 | 支持 | 支持 | 支持 | 不支持 |
| CART | 分类回归 | 二叉树 | 基尼指数均方差 | 支持 | 支持 | 支持 | 支持 |
-
划分标准的差异:ID3 使用信息增益偏向特征值多的特征,C4.5 使用信息增益率克服信息增益的缺点,偏向于特征值小的特征,CART 使用基尼指数克服C4.5 需要求log 的巨大计算量,偏向于特征值较多的特征。
-
使用场景的差异:ID3 和C4.5 都只能用于分类问题,CART 可以用于分类和回归问题;ID3 和C4.5 是多叉树,速度较慢,CART 是二叉树,计算速度很快;
-
样本数据的差异:ID3 只能处理离散数据且缺失值敏感,C4.5 和CART 可以处理连续性数据且有多种方式处理缺失值;从样本量考虑的话,小样本建议C4.5、大样本建议CART。C4.5 处理过程中需对数据集进行多次扫描排序,处理成本耗时较高,而CART 本身是一种大样本的统计方法,小样本处理下泛化误差较大;
-
样本特征的差异:ID3 和C4.5 层级之间只使用一次特征,CART 可多次重复使用特征; •剪枝策略的差异:ID3 没有剪枝策略,C4.5 是通过悲观剪枝策略来修正树的准确性,而CART 是通过代价复杂度剪枝。