1. 写在前面
在写fun-rec新闻推荐系统的YouTubeDNN召回的时候, 得到用户向量和新闻向量,基于用户向量,需要从海量新闻里面得到最相似的TopK个新闻, 此时需要用到快速向量检索技术,之前用过的一个工具是faiss, 具体使用方法我也记录了一篇博客Faiss(Facebook开源的高效相似搜索库)学习小记, 但是faiss在windows系统中并不是很好安装,并且看着也有些复杂, 这次又接触了另一个向量检索的好用工具包, 就是annoy了。 这篇文章主要是记录下如何用annoy工具包做向量检索。
简单的总结: annoy包用于向量最近邻检索,从海量item中快速查找相似的TopK个item
关于annoy包的详细介绍,可以见https://github.com/spotify/annoy
2. 安装annoy
首先,我们需要先安装annoy, 我们可以直接pip install annoy 或者指定源进行安装pip install -i https://pypi.tuna.tsinghua.edu.cn/simple annoy。
但是我用这个命令的时候, 会报Microsoft visual c++ 14.0 is required …, 因为我这边的系统目前是Windows,Linux或者Mac上应该是好使。

这个错误, 之前装faiss或者需要C++编译环境的那种包的时候,貌似也遇到过, 一劳永逸的方式,就是装一个C/C++编译环境,但是贼麻烦,并且占的内存也非常大。
我这里目前不想用这种方式, 采用另一种方式, 这里给定一个python万能包库, 在里面搜索annoy, 找到指定的python版本, 然后下载即可。
然后本地pip install 文件的绝对路径进行安装, 这个方法我这边好使。既然说到安装包了,就再多整理一点知识。
我们安装python包的时候, 最常用的就是用pip安装了,这里也借着这个机会, 学习了下pip常用的命令, 也一并记录到这里了, 详细内容看pip必备速查表
# 安装python包
pip install 包名
# 指定版本号
pip install 包名==版本
pip install 包名>=2.22, <3
pip install 包名!=2.22
# 指定镜像源安装
pip install -i url 包名 # 其中国内镜像源( url ) 可以是清华、中科大、豆瓣等
#清华:https://pypi.tuna.tsinghua.edu.cn/simple
#豆瓣:http://pypi.douban.com/simple/
# 本地wheel文件安装 whl文件可以去https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyhook离线下载到本地
pip install 包名.whl
# github仓库中安装
pip install git+包的github地址
# 更新python库
pip install 包名 -U
# 查看可提供安装的版本
pip install 包名==lemon
# 查看已经安装的python库
pip list
# 查询当前环境可升级的包
pip list -o
# 查看python库的信息
pip show 包名
pip show 包名 -f
# 卸载包
pip uninstall 包名
# 导出依赖包列表 freeze命令, 复用包很方便
pip freeze > requirements.txt # 获取当前环境安装python库的版本信息,导入到txt文件中
# 从依赖包中安装
pip install -r requirements.txt
# 将python库制作成wheel文件,可以提供给他人用.whl文件,先安装wheel库
pip install wheel
# 特定python库制作成wheel文件
pip wheel --wheel-dir DIR some-package[==version] # 其中,DIR是保存文件的路径,比如users/lemon/Downloads
# 根据依赖包信息,制作wheel文件
pip wheel --wheel-dir DIR -r requirements.txt
另外一种方式,直接下载包,然后离线复制到对应环境的包目录下面。
- windows环境: Anaconda -> Lib -> site-packages
- Linux环境: anaconda -> lib -> python版本 -> site-packages
- Mac环境: anaconda -> pkgs
这样,也可以去相应文件夹下看具体包实现的底层源码了。
3. annoy的基础使用
这里主要参考了annoy的GitHub的例子,写下来
from annoy import AnnoyIndex
import random
f = 40
t = AnnoyIndex(f, 'angular') # Length of item vector that will be indexed
for i in range(1000):
v = [random.gauss(0, 1) for z in range(f)]
t.add_item(i, v)
t.build(10)
#t.save('test.ann')
# ...
u = AnnoyIndex(f, 'angular')
u.load('test.ann') # super fast, will just mmap the file
print(u.get_nns_by_item(0, 1000)) # will find the 1000 nearest neighbors
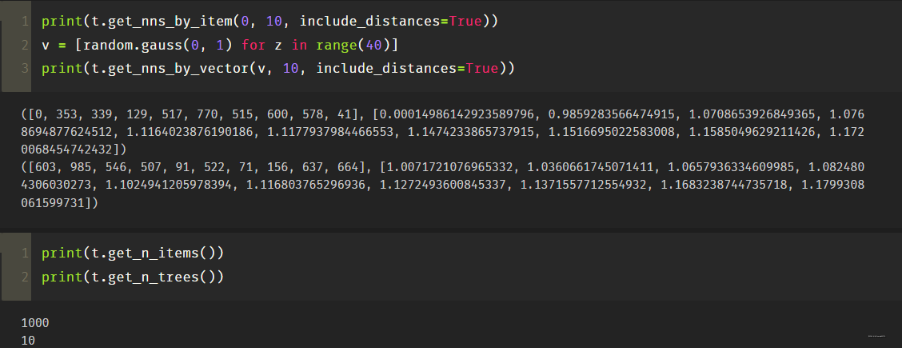
这个例子其实非常容易懂, annoy的作用就是海量向量中快速的搜索近邻向量,那么首先我们应该先为海量向量构建成高效搜索的索引, 这里采用的就是树的方式。所以前面的7行代码,主要就是在构建索引。 而真正检索的其实是最后一句, 这句话的作用是检索1000个和0位置的向量最相似的1000个向量,这里返回的结果中,会有它本身。
下面整理关于annoy常用的函数了:
-
构建索引相关的函数
AnnoyIndex(f, metric): 返回一个可读可写的存储f维向量的新索引, 这里的metric可以是"angular", “euclidean”, “manhattan”, “hamming”, or “dot”. 这里的角距离余弦相似度的归一化公式sqrt(2(1-cos(u,v)))a.add_item(i, v):在i位置(非负整数)添加向量. 这个词典最大是max(i)+1个items, 比如我有10000个item, 词典大小是0-9999位置,每个位置i存储对应item的向量, 通过这个函数,就能把词典给建立起来a.build(n_trees, n_jobs=-1): 建立一棵n_trees的森林,树越多, 精度越高, 在创建之后,就不能添加额外的的项了,n_jobs用于指定建立树的线程数, -1表示用所有额外的cpu核a.save(fn, prefault=False): 将索引保存到磁盘并加载(参见下一个函数)。保存后,不能添加更多的项目。a.load(fn, prefault=False): 从磁盘加载(mmaps)一个索引。如果prefault设置为True,它将预读取整个文件到内存中(使用mmap和MAP POPULATE)。默认是假的。
上面这几个,是如何用annoy包构建好向量词典,以及如何把向量组织起来(树的方式), 然后保存等。下面这几个,就是如何得到TopK的函数使用。 -
向量检索时用到的函数
a.get_nns_by_item(i, n, search_k=-1, include_distances=False): 返回最接近的n个item。查询过程中,将检查search_k个节点,默认为n_trees* n。serarch_k实现了准确性和速度之间的运行时间权衡。include_distances为True时将返回一个包含两个列表的2元素元组:第二个包含所有相应的距离。a.get_nns_by_vector(v, n, search_k=-1, include_distances=False): 和上面的根据item查询一样,只不过这里时给定一个查询向量v,比如给定一个用户embedding, 返回n个最近邻的item, 一般这样用的时候, 后面的距离会带着,可能作为精排那面的强特a.get_item_vector(i): 返回索引i对应的向量a.get_distance(i, j): 返回item_i和item_j的平方距离
-
索引属性函数
a.get_n_items(): 返回索引中的items个数,即词典大小a.get_n_trees(): 索引树的个数
两个超参数需要考虑: 树的数量n_trees和搜索过程中检查的节点数量search_k
- n_trees: 在构建期间提供,影响构建时间和索引大小。值越大,结果越准确,但索引越大。
- search_k: 在运行时提供,并影响搜索性能。值越大,结果越准确,但返回的时间越长。如果不提供,就是n_trees * n, n是最近邻的个数
看看我这里的几个例子:
4. YoutubeDNN中的应用
YoutubeDNN做召回的时候,我们能够根据模型得到用户的embedding和item的embedding, 我们接下来,是拿着用户的embedding, 然后去海量item中,检索最相似的TopK返回回来,作为用户的候选item。 那么假设我们已经有了user_embs和item_embs, 我们如何通过annoy进行快速近邻检索呢?
我这里写了一个函数:
def get_youtube_recall_res(user_embs, doc_embs, user_idx_2_rawid, doc_idx_2_rawid, topk):
"""近邻检索,这里用annoy tree"""
# 把doc_embs构建成索引树
f = user_embs.shape[1]
t = AnnoyIndex(f, 'angular')
for i, v in enumerate(doc_embs):
t.add_item(i, v)
t.build(10)
# 可以保存该索引树 t.save('annoy.ann')
# 每个用户向量, 返回最近的TopK个item
user_recall_items_dict = collections.defaultdict(dict)
for i, u in enumerate(user_embs):
recall_doc_scores = t.get_nns_by_vector(u, topk, include_distances=True)
# recall_doc_scores是(([doc_idx], [scores])), 这里需要转成原始doc的id
raw_doc_scores = list(recall_doc_scores)
raw_doc_scores[0] = [doc_idx_2_rawid[i] for i in raw_doc_scores[0]]
# 转换成实际用户id
user_recall_items_dict[user_idx_2_rawid[i]] = dict(zip(*raw_doc_scores))
# 默认是分数从小到大排的序, 这里要从大到小
user_recall_items_dict = {
k: sorted(v.items(), key=lambda x: x[1], reverse=True) for k, v in user_recall_items_dict.items()}
# 保存一份
pickle.dump(user_recall_doc_dict, open('youtube_u2i_dict.pkl', 'wb'))
return user_recall_items_dict
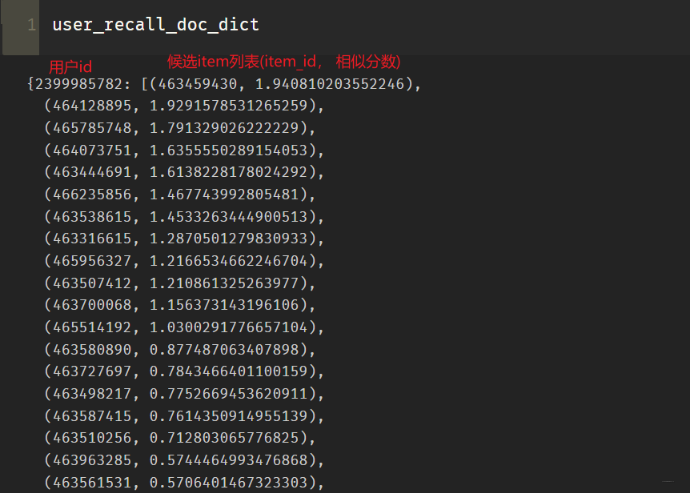
这里还有额外的两个参数是user_idx_2_rawid, doc_idx_2_rawid, 这两个是字典, 保存的是用户向量所在的位置索引与用户原始id之间的映射,以及item向量所在索引与原始item_id之间的映射, 我们最终的字典里面,应该是要保存用户原始id和item的原始id的,这个函数运行之后,得到的结果就是这个样子:
Ok, 关于annoy的探索先到这里,后面如果再学习到新知识,再进行补充。