今天是2021年8月20号,晚上坐在家里面,突然看到了2021福布斯排行榜的新闻。于是有感而发,写了这篇文章。
新闻 : 排行榜123网富豪频道为您提供2021年福布斯富豪榜,榜单包括2021世界首富排行榜,以及全球各个国家富豪排名。目前杰夫·贝佐斯以1914亿美元的财富位居世界首富第一名,而中国首富为:钟睒睒(身价:626亿美元)
由于这是一个表格型的数据,也没什么反扒措施,为了节省时间,直接上pandas库吧,我只需要5行代码就行啦!
import pandas as pd
import csv
for i in range(1,16): # 爬取全部页
tb = pd.read_html(f'https://www.phb123.com/renwu/fuhao/shishi_{
i}.html')[0]
tb.to_csv(r'福布斯排行榜.csv', mode='a', encoding='utf_8_sig', index=0)
结果如下:
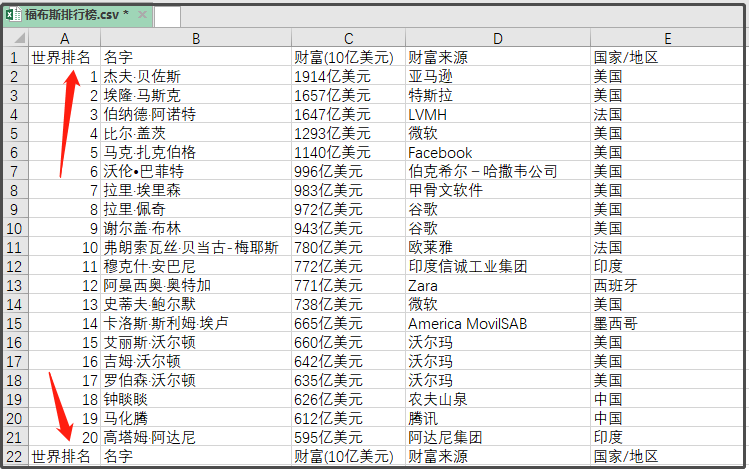
太尴尬了,标题行都在,那就有14个表头了,我们读取一下,去掉重复行吧!
df = pd.read_csv("福布斯排行榜.csv",header=None)
df.drop_duplicates(inplace=True)
df.to_excel("福布斯排行榜.xlsx",index=None)
直接使用drop_duplicates()函数,实现去重操作,并重新保存了一个新文件。
好了,开始我们的数据探索吧!
df1 = pd.read_excel("福布斯排行榜.xlsx",header=1)
df1
结果如下:
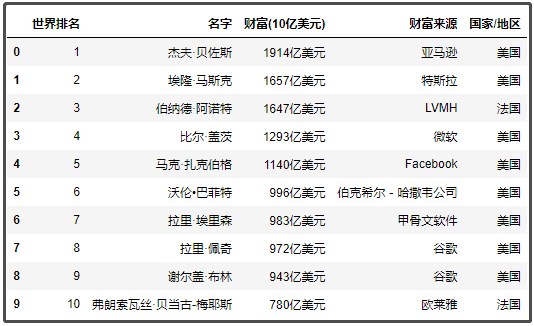
1. 排行榜世界前10
x = df1.head(10)
x
结果如下:
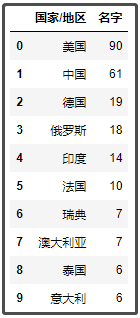
2. 上榜人数最多的前10个国家
df1.groupby("国家/地区")["名字"].count().sort_values(ascending=False)[:10].to_frame().reset_index()
结果如下:
3. 排行榜中国前10
y = df1[df1["国家/地区"] == "中国"]
y.head(10)
结果如下:
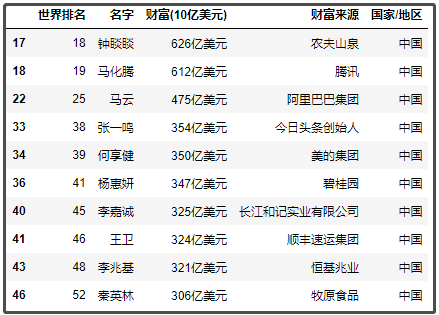
其实不管是中国前十,还是世界前十,基本都是一些咱们耳熟能详的企业。不得不说,美国佬上榜的人数确实多。
好了,了解一下就好,在心里激励一下自己吧!成不了别人,更应该加油。就当作是周末的一个鸡汤吧!