为什么要使用克隆(clone)?
当拷贝一个变量时,原始变量与拷贝变量引用同一个对象,这就是说,改变一个变量所引用的对象将会对另外一个变量产生影响,这种情况下就可以使用就可以使用克隆。举个栗子:
学生类:
@Accessors(chain = true)
@NoArgsConstructor
@AllArgsConstructor
@Data
public class Student {
int age ;
String name;
}
测试:
Student studentA = new Student(18,"A");
System.out.println(studentA.toString());
Student studentB = studentA;
studentB.setName("B");
System.out.println(studentB.toString());
System.out.println(studentA.toString());
输出结果:

可以看出将studentA赋值给studentB并将其的名字改为B而A的名字却也发生了改变。那么此时的两者内存地址关系呢?讓我們打印一下:
System.out.println(System.identityHashCode(studentA));
System.out.println(System.identityHashCode(studentB));
結果:
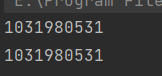
可以看出两个对象的内存地址都是一样的。说明studentB和studentA都只是一个相同引用,而这种情况下的拷贝只是引用的复制。
那么使用了克隆对象的情况呢?此时我们对例子做个简单变化。实现克隆后的学生类:
@Accessors(chain = true)
@NoArgsConstructor
@AllArgsConstructor
@Data
public class Student implements Cloneable{
int age ;
String name;
@Override
protected Student clone() throws CloneNotSupportedException {
return (Student) super.clone();
}
}
测试:
@Test
public void testClone(){
Student studentA = new Student(18,"A");
System.out.println(studentA);
Student studentB = null;
try {
studentB = studentA.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
studentB.setName("B");
System.out.println(studentB);
System.out.println(studentA);
}
输出结果:
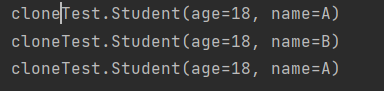
此时就可以看到此时studentA就没有改变。打印一下内存地址:
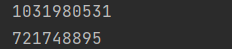
可以看出克隆后的对象引用指向的地址已经不是原来的对象。画个引用图更好理解:

可以看出克隆的对象是开辟出了一个新的内存空间。那么就会有人就会问:那么这样的方式和new一个对象又有什么差别呢?而这也是很多面试会考的问题之一。
clone一个对象和new一个对象的差别
先来大体了解下目前创建对象的几种方式:
-
new 关键字
new 操作符的本意是分配内存。程序执行到 new 操作符时,首先去看 new 操作符后面的类型,因为知道了类型,才能知道要分配多大的内存空间。分配完内存之后,再调用构造函数,填充对象的各个域,这一步叫做对象的初始化,构造方法返回后,一个对象创建完毕,可以把他的引用(地址)发布到外部,在外部就可以使用这个引用操纵这个对象。 -
反射机制
这种方式也是通过反射方法,调用构造器来初始化对象。 -
使用clone方法
clone 在第一步是和 new 相似的,都是分配内存,调用 clone 方法时,分配的内存和原对象(即调用 clone 方法的对象)相同,然后再使用原对象中对应的各个域,填充新对象的域,填充完成之后,clone 方法返回,一个新的相同的对象被创建,同样可以把这个新对象的引用发布到外部。 -
反序列化
序列化反序列化方式是从文件中还原类的对象,所以不会调用构造函数。 -
Unsafe.allocateInstance()
此方法为 native 方法,没有初始化实例字段。它只做了分配内存空间,返回内存地址,并没有调用构造函数。所以 Unsafe.allocateInstance() 方法创建的对象都是只有初始值,没有默认值也没有构造函数设置的值,因为它完全没有使用 new 机制,直接操作内存创建了对象。
本篇主要涉及new和clone的方式,因此其余三种就大体提一下略过。
由此可以看出其主要的区别:
- 在java中clone()与new都能创建对象。
- clone()不会调用构造方法;new会调用构造方法。其域为原有对象的各个域的填充。
结论:由于clone是直接的复制,而new则要调用构造方法,创建对象时要赋值初始化所以在复杂对象的创建上clone的效率会高于new一些。
注意:结论上指的是复杂对象。由于编译器会对new操作符进行一些优化,所以new创建简单对象的时间有时会更少,对刚刚的学生类再举个栗子:
@Test
public void testTime() throws CloneNotSupportedException {
long s1 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
Student student = new Student();
}
long s2 = System.currentTimeMillis();
System.out.println("new 方式耗时:"+(s2-s1));
long s3 = System.currentTimeMillis();
Student s = new Student();
for (int i = 0; i < 1000000; i++) {
Student student = s.clone();
}
long s4 = System.currentTimeMillis();
System.out.println("clone 方式耗时:"+(s4-s3));
}
结果:
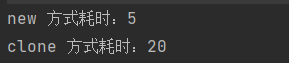
可以看出在这种对简单对象的赋值上直接选择new或许是个不错的选择。
了解了这些后再来看看如何使用克隆。
克隆的方式
浅克隆(ShallowClone)
浅克隆是指拷贝对象时仅仅拷贝对象本身(包括对象中的基本变量),而不拷贝对象包含的引用指向的对象。
对之前的学生类进行改造下,使其包含一个引用对象。
@Accessors(chain = true)
@NoArgsConstructor
@AllArgsConstructor
@Data
public class Student implements Cloneable{
int age ;
String name;
Teacher teacher;
@Override
protected Student clone() throws CloneNotSupportedException {
return (Student) super.clone();
}
}
@Accessors(chain = true)
@NoArgsConstructor
@AllArgsConstructor
@Data
public class Teacher{
int age ;
String name;
}
测试类:
@Test
public void testClone(){
Student studentA = new Student(18,"A",new Teacher(28,"陈老师"));
Student studentB = null;
try {
studentB = studentA.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
studentB.getTeacher().setAge(29);
System.out.println(studentB.getTeacher());
System.out.println(studentA.getTeacher());
}
输出:

可以看出此时即使的是使用了clone方法。但是改变其引用时,还是把原始的引用给修改了。让我们分别打印一下此时的两个student中teacher的内存地址:
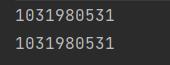
可以得出两个student对象中的对象引用其实是指的同一个teacher对象,本质还是复制的引用。
画个引用图如下:

由此可见这种方式只复制基本类型的数据,引用类型的数据只复制了引用的地址,引用的对象并没有复制,在新的对象中修改引用类型的数据会影响原对象中的引用,而这种克隆的方式也叫做浅克隆。
而为了解决浅克隆的弊端,而有了深克隆。
深克隆(DeepClone)
深克隆:
是在引用类型的类中也实现了clone,是clone的嵌套,复制后的对象与原对象之间完全不会影响。因此将上述例子的学生和教师类再改一下实现深克隆。
@Accessors(chain = true)
@NoArgsConstructor
@AllArgsConstructor
@Data
public class Student implements Cloneable{
int age ;
String name;
Teacher teacher;
@Override
protected Student clone() throws CloneNotSupportedException {
Student student = (Student) super.clone();
student.setTeacher( student.getTeacher().clone());
return student;
}
}
@Accessors(chain = true)
@NoArgsConstructor
@AllArgsConstructor
@Data
public class Teacher implements Cloneable{
int age ;
String name;
@Override
protected Teacher clone() throws CloneNotSupportedException {
return (Teacher) super.clone();
}
}
再按刚刚的测试代码再输出一遍:

可以看出此时的年龄已经修改成功,内存地址也不再相同。此时的引用关系应为:

(ps:使用序列化也能完成深克隆的功能:对象序列化后写入流中,此时也就不存在引用什么的概念了,再从流中读取,生成新的对象,新对象和原对象之间也是完全互不影响的。但是序列里的引用对象也要都实现Serializable接口)
进一步可以想到如果teacher里面还有个subject的引用对象呢?
其实很简单,这种只是相当于再嵌套一层。也就是说,要实现student的深克隆,就要实现teacher的深克隆,最终是subject中实现一层浅克隆。
所以可以认为使用clone实现的深克隆其实是浅克隆中嵌套了浅克隆。
本篇到此为止了,就结束了如果您看到了最后,不妨收藏、点赞、评论一下吧!!!
持续更新,您的三连就是我最大的动力,虚心接受大佬们的批评和指点,共勉!
