学习kaldi已经接近两个月了,终于将kaldi中语音的特征数据提取出来,对于其分帧的标签进行对齐,即将输入到TensorFlow搭建的模型中,下面详细的讲解一下如何提取语音的特征以及对音素标签进行对齐,提取语音MFCC+delta+deltas的39维度特征在上将博客已经讲完,可以翻看前面博客,下面着重讲一下如何提取语音的的对齐特征。
以thchs30语料进行试验,对mono模型的对齐特征进行提取:
1:原始phone下的音素标签;


2:进入kaldi/src/bin/ ,运行./ali-to-phones,详细脚本如下所示;
3:然后在命令行输入 set nu/set nonu可以查看行数;
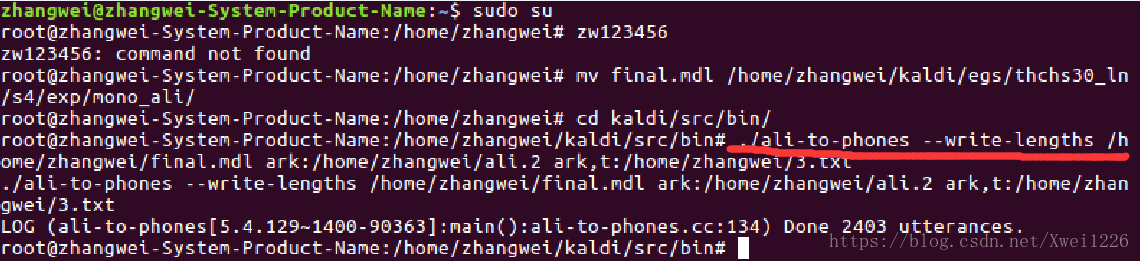

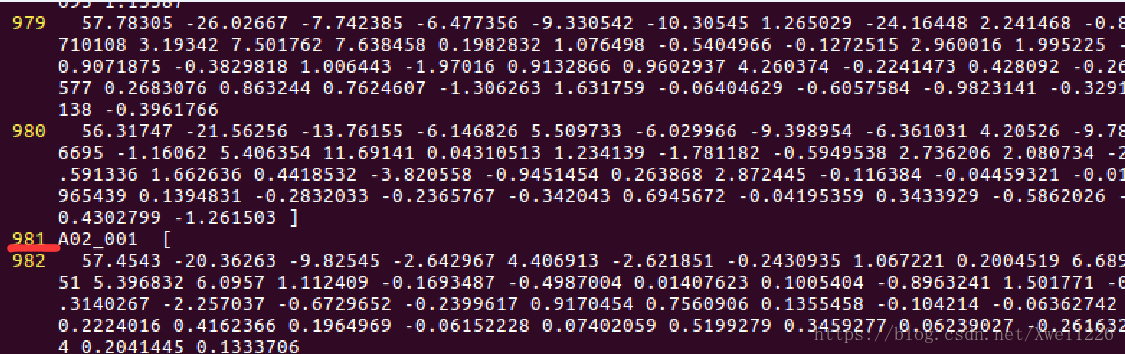
从标签可以看出,对于thchs训练集中,第一句话一共分为979帧,和上面的音素符号进行了对齐。如有不懂欢迎留言。