经过前几年一轮房价大涨,到现在因为国家大力调控等原因,市场已经褪去热度,正在慢慢变得稳定,价格也相较最高时下降了些。那现在房价到底怎样?接下来又会是怎样的发展的趋势?这里我们就可以通过 Python 把最近的房价数据抓取下来进行分析。
模块安装
这里需要安装以下模块,当然如果已安装就不用再装了:
# 安装引用模块pip3 install bs4pip3 install requestspip3 install lxmlpip3 install numpypip3 install pandas
配置请求头
一般我们在抓取网站时,为了应对网站的反爬机制,我们会把请求的头信息进行封装处理,以下是最简单的处理,就是将请求客户端信息进行随机选择并使用,代码如下:
# 代理客户端列表USER_AGENTS = ["Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)","Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)","Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)","Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)","Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20","Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",]# 创建请求头信息def create_headers():headers = dict()headers["User-Agent"] = random.choice(USER_AGENTS)headers["Referer"] = "http://www.ke.com"return headers
配置代理IP
除了上面配置请求头外,如果你用相同的 IP 大量请求抓取时,很可能会被封 IP,被封后再用这个 IP 请求网站时,会提示你请求超时,为避免被封最好我们通过代理 IP 去抓取,怎样才能找到能用的代理 IP?
# 引入模块from bs4 import BeautifulSoupimport requestsfrom lib.request.headers import create_headers# 定义变量proxys_src = []proxys = []# 请求获取代理地址def spider_proxyip(num=10):try:url = 'http://www.xicidaili.com/nt/1'# 获取代理 IP 列表req = requests.get(url, headers=create_headers())source_code = req.content# 解析返回的 htmlsoup = BeautifulSoup(source_code, 'lxml')# 获取列表行ips = soup.findAll('tr')# 循环遍历列表for x in range(1, len(ips)):ip = ips[x]tds = ip.findAll("td")proxy_host = "{0}://".format(tds[5].contents[0]) + tds[1].contents[0] + ":" + tds[2].contents[0]proxy_temp = {tds[5].contents[0]: proxy_host}# 添加到代理池proxys_src.append(proxy_temp)if x >= num:breakexcept Exception as e:print("获取代理地址异常:")print(e)
房价数据对象
在这里我们将新房的房价信息,创建成一个对象,后续我们只要将获取到的数据保存成对象,再处理就会方便很多。NewHouse 对象代码如下所示:
# 新房对象class NewHouse(object):def __init__(self, xiaoqu, price, total):self.xiaoqu = xiaoquself.price = priceself.total = totaldef text(self):return self.xiaoqu + "," + \self.price + "," + \self.total
获取房价信息并保存
好了,做好以上准备,下面我们就以贝壳为例,批量爬取其北京地区新房数据,并保存到本地。其实只要能抓取到数据,想保存成什么格式都可以,当然也可以保存到数据库。这里我主要想说的是如何抓取数据,所以这里就保存成最简单的 txt 文本格式。
# 创建文件准备写入with open("newhouse.txt", "w", encoding='utf-8') as f:# 获得需要的新房数据total_page = 1loupan_list = list()page = 'http://bj.fang.ke.com/loupan/'# 调用请求头headers = create_headers()# 请求 url 并返回结果response = requests.get(page, timeout=10, headers=headers)html = response.content# 解析返回 htmlsoup = BeautifulSoup(html, "lxml")# 获取总页数try:page_box = soup.find_all('div', class_='page-box')[0]matches = re.search('.*data-total-count="(\d+)".*', str(page_box))total_page = int(math.ceil(int(matches.group(1)) / 10))except Exception as e:print(e)print('总页数:' + total_page)# 配置请求头headers = create_headers()# 从第一页开始遍历for i in range(1, total_page + 1):page = 'http://bj.fang.ke.com/loupan/pg{0}'.format(i)print(page)response = requests.get(page, timeout=10, headers=headers)html = response.content# 解释返回结果soup = BeautifulSoup(html, "lxml")# 获得小区信息house_elements = soup.find_all('li', class_="resblock-list")# 循环遍历获取想要的元素for house_elem in house_elements:price = house_elem.find('span', class_="number")desc = house_elem.find('span', class_="desc")total = house_elem.find('div', class_="second")loupan = house_elem.find('a', class_='name')# 开始清理数据try:price = price.text.strip() + desc.text.strip()except Exception as e:price = '0'loupan = loupan.text.replace("\n", "")# 继续清理数据try:total = total.text.strip().replace(u'总价', '')total = total.replace(u'/套起', '')except Exception as e:total = '0'# 作为对象保存到变量loupan = NewHouse(loupan, price, total)print(loupan.text())# 将新房信息加入列表loupan_list.append(loupan)# 循环获取的数据并写入到文件中for loupan in loupan_list:f.write(loupan.text() + "\n")
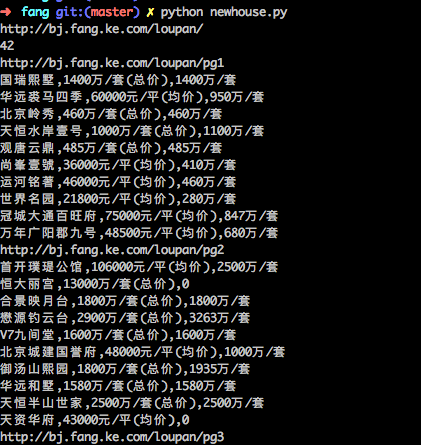
代码写好了,现在我们就可以通过命令 python newhouse.py 运行代码进行数据抓取了。抓取的结果如下图所示:
总结
本文为大家介绍了如何通过 Python 将房产网上的新房数据批量抓取下来,然后就可以将每天抓取的结果跟历史数据进行对比分析,来判断楼市的大概趋势。其中涉及到了用 BeautifulSoup 进行 html 解析,整个代码来看实现方式并不难,希望通过这个过程可以为你提供一些帮助。
在学编程,学Python的小伙伴们,一个人摸黑学会很难,博主也是过来人, 这里新建了一个扣群:1020465983,给大家准备了学习资源、好玩的项目,欢迎大家加入一起交流。