Pytorch 残差网络 ResNet
0. 环境介绍
环境使用 Kaggle 里免费建立的 Notebook
小技巧:当遇到函数看不懂的时候可以按 Shift+Tab 查看函数详解。
1. ResNet
1.1 简介
卷积神经网络中加更多的层不一定总是增加精度。
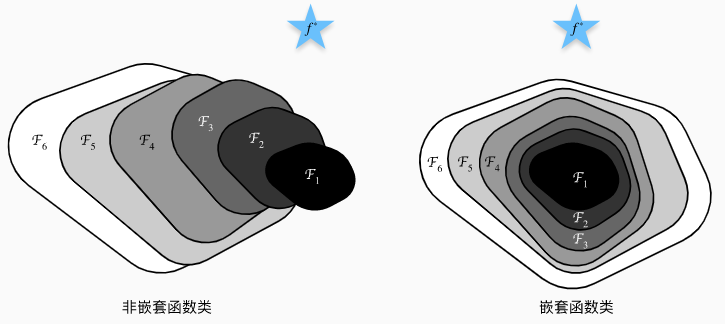
假设 f ∗ f^* f∗ 是我们要找到的函数,对于非嵌套函数(non-nested function)类,较复杂的函数类并不总是向 f ∗ f^* f∗ 靠拢,(从 F 1 F_1 F1 到 F 6 F_6 F6 函数复杂度越来越高)。可以看到左侧非嵌套函数 F 6 F_6 F6 误差更大了。
右侧的嵌套函数(nested function)不会出现这种情况。
对于深度神经网络,如果我们能将新添加的层训练成恒等映射(identity function) f ( x ) = x f(x)=x f(x)=x,新模型和原模型将同样有效。
同时,由于新模型也可能得出更优的解来拟合训练数据集,因此添加层似乎更容易降低训练误差。
我的理解:大概意思就是如果添加新的层能减小误差就保留参数,如果添加新的层误差变大就训练其参数不生效,往 f ( x ) = x f(x) = x f(x)=x 上训练,其中 x x x 是输入, f ( x ) f(x) f(x) 是新加的一层运算后的结果。
ResNet 论文地址:https://arxiv.org/abs/1512.03385
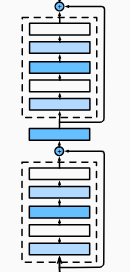
1.2 残差块
左侧是一个正常块,右侧是一个残差块:
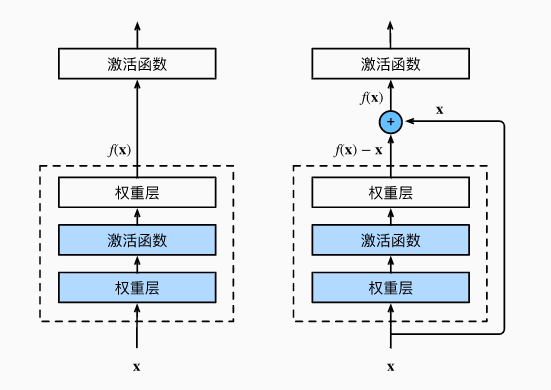
- 串联一个层改变函数类,我们希望能扩大函数类
- 残差块加入快速通道来得到 f ( x ) = x + g ( x ) f(x) = x + g(x) f(x)=x+g(x) 的结构
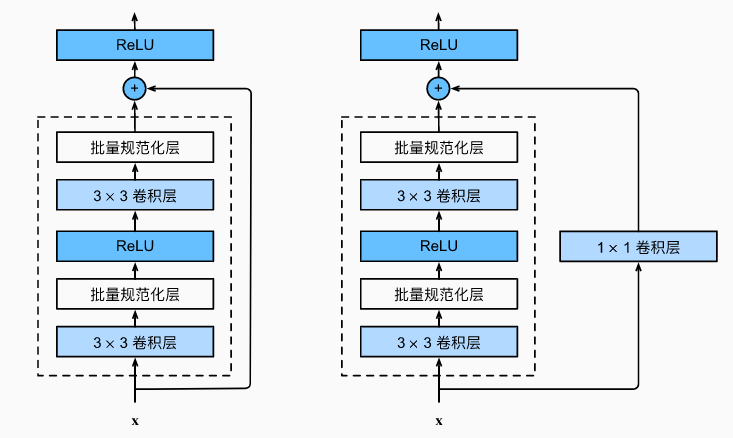
具体的 ResNet 块细节,左侧不包含 1 × 1 1 \times 1 1×1 卷积,右侧包含 1 × 1 1 \times 1 1×1 卷积:
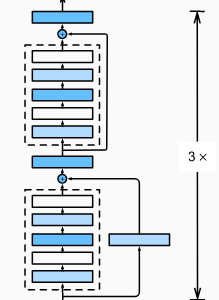
1.3 网络结构
ResNet-18(类似 VGG 和 GoogLeNet,替换成了 ReNet 块):
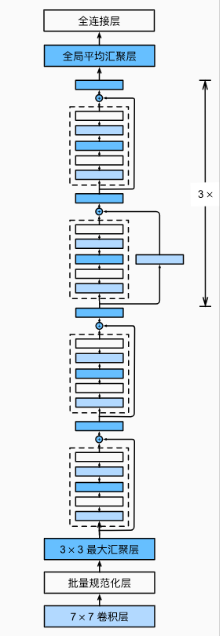
前面是高宽减半的 ResNet 块(步幅为 2)。
后接多个高宽不变的 ResNet 块。
残差块使得很深的网络更加容易训练
- 甚至可以训练一千层的网络
残差网络对随后的深层神经网络设计产生了深远影响,无论是卷积类网络还是全连接网络。
2. 代码实现
2.1 残差块
!pip install -U d2l
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module): #@save
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
# 第二个卷积层可以保证输出形状和输入形状相同, 比如 224-3+2+1 = 224
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
# 1 × 1 卷积一般步长为 1,老师代码里是等于传进来的参数,不知道是不是多余了
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
use_1x1conv 代表是否使用 1 × 1 1 \times 1 1×1 卷积。
ReLU(inplace=True) 的意思是是对从上层网络传递下来的 tensor 直接进行修改,这样能够节省运算内存,不用多存储其他变量。
2.2 验证残差块输出形状
输入与输出形状一致:
# (输入通道数, 输出通道数)
blk = Residual(3,3)
# (batch, 输入通道数, 图像高, 图像宽)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shape
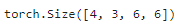
增加输出通道数,输出形状相对于输入减半:
# (输入通道数, 输出通道数, 使用 1×1 卷积, 第一个卷积层步长)
blk = Residual(3,6, use_1x1conv=True, strides=2)
blk(X).shape
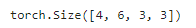
2.3 网络结构
定义一个 resnet_block 函数用于定义连续的 ResNet 块:
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
first_block 默认为 False 表示输出特征图高宽减半,若为 True 表示不减半。
第 1 1 1 段:
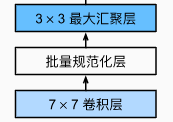
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第 2 2 2 段:
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
第 3 3 3 段:
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
最后一段:
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))
2.4 验证网络输出形状
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)

2.5 训练
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
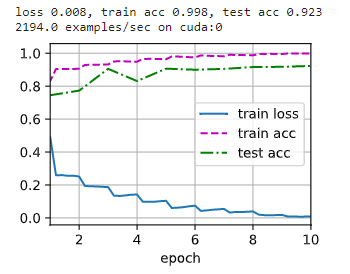
在训练集上有点过拟合,但是在测试集上精度达到了 0.923 0.923 0.923。
3. Q&A
Q: f ( x ) = x + g ( x ) f(x) = x + g(x) f(x)=x+g(x),这样就能保证结果至少不变坏吗?如果 g ( x ) g(x) g(x) 不是变好,也不是什么都不做,而是变坏了呢?
A: g ( x ) g(x) g(x) 也是训练出来的,如果模型发现 g ( x ) g(x) g(x) 很难训练或者训练后没好处的话,它就会拿不到梯度,假如 x x x 传入的时候已经效果很好, g ( x ) g(x) g(x) 的权重很可能就不会更新或者变成很小的权重,不会对结果做什么贡献。
假设: f , g f, g f,g 是网络模型中的某些层的运算,令 y 1 = f ( x ) y_1 = f(x) y1=f(x), y 2 = g ( f ( x ) ) y_2 = g(f(x)) y2=g(f(x)), y 3 = f ( x ) + g ( f ( x ) ) y_3 = f(x) + g(f(x)) y3=f(x)+g(f(x))
求梯度
∂ y 1 ∂ w ∂ y 2 ∂ w = ∂ g ( y 1 ) ∂ y 1 ⋅ ∂ y 1 ∂ w ∂ y 3 ∂ w = ∂ y 1 ∂ w + ∂ y 2 ∂ w \frac{\partial y_1}{\partial w} \\ \frac{\partial y_2}{\partial w} = \frac{\partial g(y_1)}{\partial y_1} \cdot \frac{\partial y_1}{\partial w} \\ \frac{\partial y_3}{\partial w} = \frac{\partial y_1}{\partial w} + \frac{\partial y_2}{\partial w} ∂w∂y1∂w∂y2=∂y1∂g(y1)⋅∂w∂y1∂w∂y3=∂w∂y1+∂w∂y2
若 ∂ g ( y 1 ) ∂ y 1 \frac{\partial g(y_1)}{\partial y_1} ∂y1∂g(y1) 梯度很小,那么 ∂ y 2 ∂ w \frac{\partial y_2}{\partial w} ∂w∂y2 的梯度也会很小。现在引入 ResNet 块后就如上第三个式子一样,即使 ∂ y 2 ∂ w \frac{\partial y_2}{\partial w} ∂w∂y2 梯度很小,还有 ∂ g ( y 1 ) ∂ y 1 \frac{\partial g(y_1)}{\partial y_1} ∂y1∂g(y1) 保留梯度(即:大数 + 小数 = 大数,大数 × 小数可能变成一个小数)。
Q:如果 x x x 和 g ( x ) g(x) g(x) 都很小怎么办呢?(待解决)