1,概念
1)插入排序
直接插入排序、折半插入排序、2-路插入排序、表插入排序、希尔排序、快速排序、冒泡排序
2)选择排序
简单选择排序、堆排序
2, 直接插入排序(Insertion Sort)
1)原理
每次将一个待排序的记录,按其关键字大小插入到前面已经排好序的子序列中的适当位置,直到全部记录插入完成为止。
2)代码实现
public static void insertSort(int[] a){
for(int i=1; i<a.length; i++){
int temp = a[i];//待插入元素
int j;
for (j=i-1; j>=0; j--){//将大于temp的往后移动一位
if (temp < a[j]){
a[j+1] = a[j];
}else{
break;
}
}
a[j+1] = temp;//插入进来
}
}3)稳定性
稳定。
4)复杂度
①空间复杂度:O(1)。
②时间复杂度:
最好的情况:原来本身有序,比较次数为n-1次时间复杂度为O(n)
最坏的情况:原来为逆序,比较次数为1 + 2 + 3 + … + (N - 1)次 (O(n^2)),而记录的移动次数为1 + 2 + 3 + … + (N - 1)次 (O(n^2)),时间复杂度为 O(n^2)。
5)举例

3, 折半插入排序
在折半查找的基础上进行的插入排序。
1)原理
①每次插入,都从前面的有序子表中查找出待插入元素应该被插入的位置; (折半查找)
②给插入位置腾出空间,将待插入元素复制到表中的插入位置。
2)代码实现
public static void insertSortBinary(int[] a){
int low, high, mid;
int temp;//待插入的数
for (int i=1; i<a.length; i++){
temp = a[i];
//折半查找范围
low = 0;
high = i-1;
while (low <= high){
mid = (low+high) / 2;
if (a[mid] > temp){
high = mid-1;//查找左半元素
}else{
low = mid+1;
}
}
for(int j=i-1; j>= high + 1; j--){
a[j+1] = a[j];//后移空出插入位置
}
a[high + 1] = temp;//插入
}
OutputMessage.showMessage(a);
}3)稳定性
稳定的。
4)复杂度
①时间复杂度 :O(n²)
折半插入排序仅仅是减少了比较元素的次数,约为O(nlogn),而且该比较次数与待排序表的初始状态无关,仅取决于表中的元素个数n;而元素的移动次数没有改变,它依赖于待排序表的初始状态。因此,折半插入排序的时间复杂度仍然为O(n²),但它的效果还是比直接插入排序要好。
②空间复杂度:O(1)。
稳定性
折半插入排序是一种稳定的排序算法。
4, 2-路插入排序
1)原理
折半插入排序的改进,通过增加n个记录的辅助空间,减少排序过程中移动记录的次数。
①开辟一个等长的临时数组(循环数组),将待排序数组的第1个元素放到临时数组的第0位,作为初始化。将该值作为每次排序的参照,大于等于这个参照值就后插,小于参照值就前插。
②同时定义两个游标first和final分别指向临时数组当前最小值和最大值所在位置。
2)代码实现
public static void TwoInsertSort(int[] a){
int first=0, finals = 0;
int length = a.length;
int []b = new int[length];//辅助空间
b[0] = a[0];
for(int i = 1; i < length; i++){
if(a[i] > b[finals]){
finals++;
b[finals] = a[i];
}
if(a[i] < b[first]){
first=(first-1+length)%length;
b[first]=a[i];
}
if(a[i] > b[first] && a[i]< b[finals]){//用循环数组理解
int j = finals;
finals++;
while(a[i] <= b[j]){
b[(j+1)%length] = b[j];
j = (j-1+length)%length;
}
b[(j+1)%length] = a[i];////若j停留在数组最后的位置(j+1)%length
}
OutputMessage.showMessage(b);
System.out.print("finals=" + finals + ",first=" + first);
}
/*
* 将数组重新复制到a[]数组中(调整循环数组顺序)
*/
for(int i = 0; i < length;i++){
a[i] = b[(first++)%length];
}
OutputMessage.showMessage(a);
}3)稳定性
稳定
4)复杂度
和折半复杂度一致,但避免了数据的移动(不是绝对的避免)。
5)举例

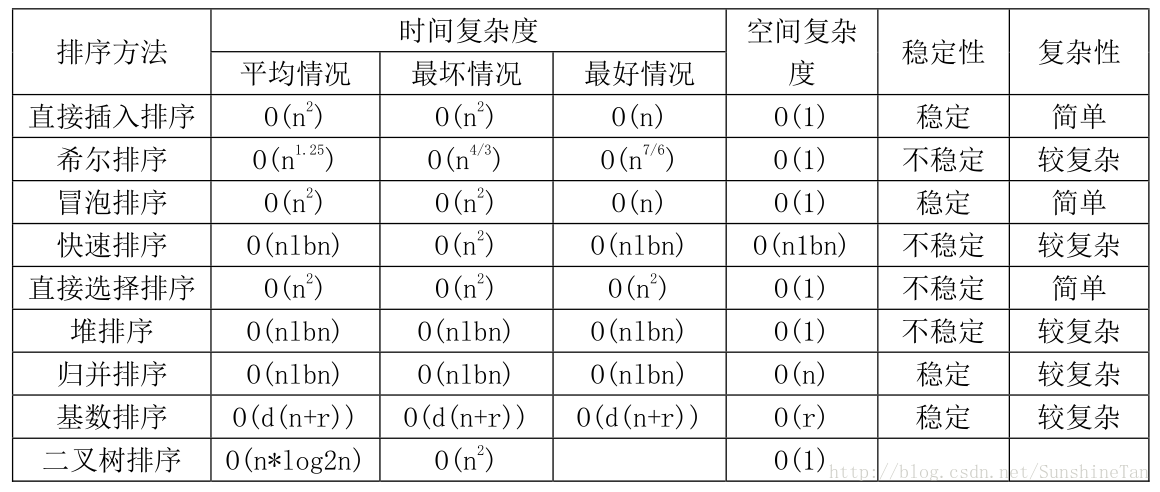
5, 表插入排序
1)原理
将一个记录插入到已排好序的有序链表中,通过修改指针的值来代替移动记录。
利用静态链表的形式,分两部完成:
①对一个有序的循环链表,插入一新的元素,修改每个节点的后继指针的指向,使顺着这个指针的指向,元素是有序的。在这个过程中,我们不移动或交换元素,只是修改指针的指向。
②顺着指针的指向调整元素的位置,使其在链表中真正做到物理有序。
2)代码实现
/**
* 表插入排序,相当于静态链表
* 从小到大排序
*/
public static void table_insertion_sort(int[] a) {
TableSortEntity[] arr = getTableSortArr(a);
int current, pre;//current当前节点 pre前一个节点
for (int i = 2; i < a.length + 1; i++) { //修改next域,使其按指针指向有序
pre = 0;
current = arr[pre].getNext();
while (arr[i].getData() >= arr[current].getData()) { // >= 保证了排序的稳定性
pre = current;
current = arr[pre].getNext();
}
arr[i].setNext(current);
arr[pre].setNext(i);
}
current = arr[0].getNext();
int i = 0;
while (current != 0) { //顺着静态链表的指针指向,回写数据到原数组
a[i++] = arr[current].getData();
current = arr[current].getNext();
}
array_table(arr);
}private static TableSortEntity[] getTableSortArr(int[] a) {
int MAX = 20;
TableSortEntity[] arr = new TableSortEntity[a.length + 1];//arr[0]为头结点,为循环终止创造条件,头结点值域MAX应大于原序列中的最大值。
for (int i = 0; i < a.length; i++) { //把数据赋给链表
TableSortEntity tableSortEntity = new TableSortEntity();
tableSortEntity.setData(a[i]);
tableSortEntity.setNext(0);
arr[i + 1] = tableSortEntity;
}
TableSortEntity tableSortEntity = new TableSortEntity();
tableSortEntity.setData(MAX);
tableSortEntity.setNext(1);//头节点和第一个节点构成了循环链表
arr[0] = tableSortEntity;
return arr;
}private static void array_table(TableSortEntity[] arr) {
int q, p = arr[0].getNext();
for (int i = 1; i < arr.length; i++) {
while (p < i)
p = arr[p].getNext();
q = arr[p].getNext(); // q记录下一次待归位节点的下标
if (p != i) { //如果p与i相等,则表明已在正确的位置上,那就不需要调整了
TableSortEntity temp = arr[i];
arr[i] = arr[p];
arr[p] = temp;
arr[i].setNext(p);
}
p = q;
}
System.out.println("排序结果:");
for (int j = 1; j < arr.length; j++) {
System.out.print(arr[j].getData() + ",");
}
}public class TableSortEntity {
int data; //值域
int next; //静态链表的链域
}3)稳定性
稳定
4)复杂度
时间复杂度:O(n2),避免了移动。
5)举例
6, 分段插入排序
1)原理
①已知一组升序排列数据a[1]、a[2]、……a[n],一组无序数据b[1]、b[2]、……b[m],需将二者合并成一个升序数列。先将数组a分成x等份(x<<n),每等份有n/x个数据。将每一段的第一个数据先储存在数组c中:c[1]、c[2]、……c[x]。
②运用插入排序处理数组b中的数据。插入时b先与c比较,确定了b在a中的哪一段之后,再到a中相应的段中插入b。随着数据的插入,a中每一段的长度会有变化,所以在每次插入后,都要检测一下每段数据的量的标准差s,当其大于某一值时,将a重新分段。在数据量特别巨大时,可在a中的每一段中分子段,b先和主段的首数据比较,再和子段的首数据比较,可提高速度。
2)优缺点
优点:快,比较次数少;
缺点:不适用于较少数据的排序,s的临界值无法确切获知,只能凭经验取。
7, 希尔排序(Shell’s Sort,缩小增量排序,Diminishing Increment Sort)
1)原理
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
2)代码实现
/**
* 希尔排序 针对有序序列在插入时采用交换法
* @param arr
*/
public static void shellSort(int[] arr) {
//增量gap,并逐步缩小增量
for (int gap = arr.length / 2; gap > 0; gap /= 2) {
//从第gap个元素,逐个对其所在组进行直接插入排序操作
for (int i = gap; i < arr.length; i++) {
int j = i;
while (j - gap >= 0 && arr[j] < arr[j - gap]) {
//插入排序采用交换法
swap(arr, j, j - gap);
j -= gap;
}
}
}
}3)稳定性
不稳定。
4)复杂度
最坏时间复杂度依然为O(n2),一些经过优化的增量序列如Hibbard经过复杂证明可使得最坏时间复杂度为O(n3/2).
Shell排序比冒泡排序快5倍,比插入排序大致快2倍。Shell排序比起QuickSort,MergeSort,HeapSort慢很多。但是它相对比较简单,它适合于数据量在5000以下并且速度并不是特别重要的场合。它对于数据量较小的数列重复排序是非常好的。
5)举例
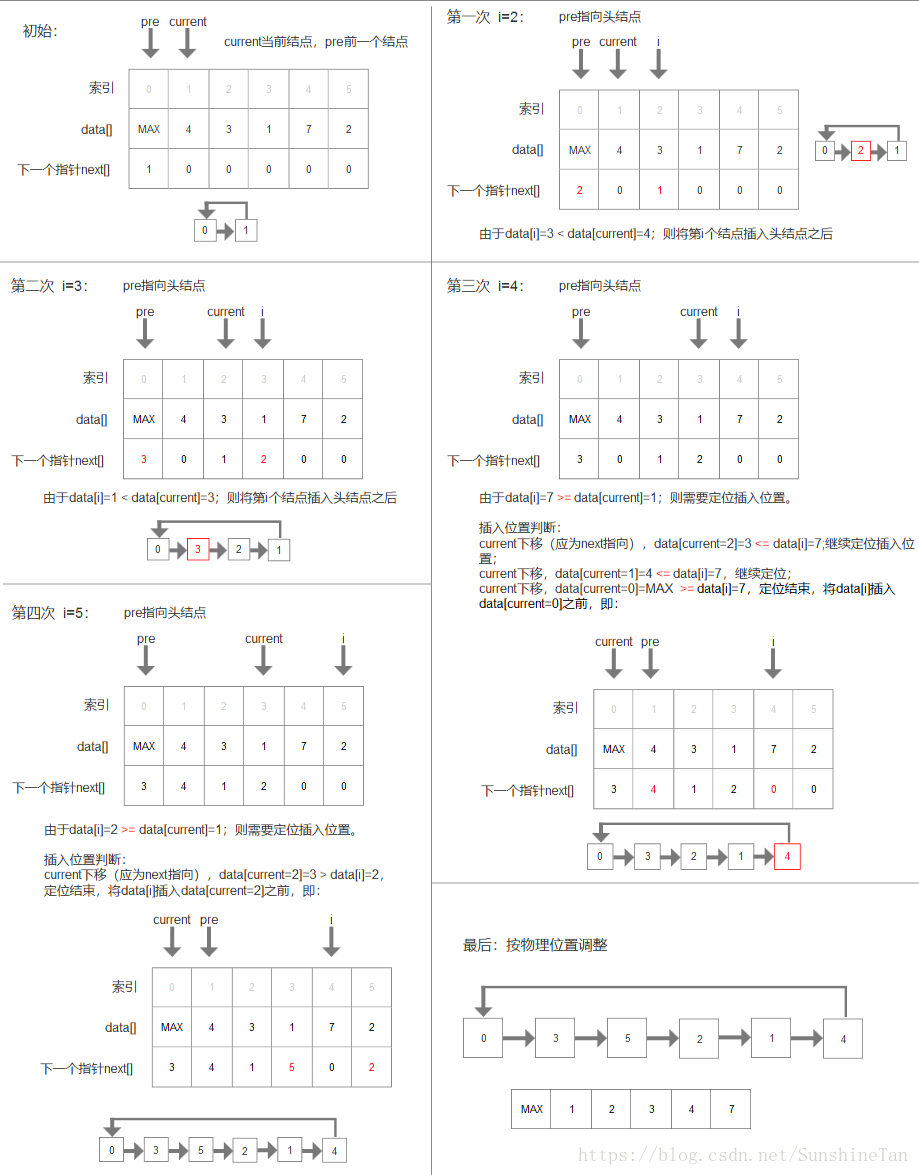
如下图所示。
首先,步长k=5,则R1和R6分为一组,依次类推,共5个子序列:{R1,R6},{R2,R7},{R3,R8},{R4,R9},{R5,R10}.
在每一对子序列内,从小到大排序,然后合并结果为第一趟排序结果。
第二趟排序,k=4。以此类推,直到k=1停止。
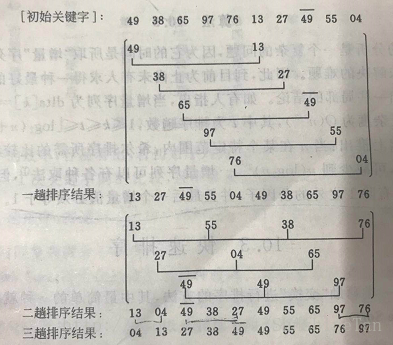
8, 快速排序
1)原理
整体思想:
①先从数列中取出一个数作为基准数。
②分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
③再对左右区间重复第二步,直到各区间只有一个数。

一次划分:
①设置2个变量i=0、j=N-1;
②第一个数为基准key;
③j向前搜索,j–,找到第一个比key小的数A[j],将A[i]与A[j]交换;
④i向后搜索,i++,找到第一个比key大的数A[i],将A[i]与A[j]交换;
⑤重复第三、四步,直到i>=j。

2)代码实现
package QuickSort;
/**
* 快速排序(从大到小)
* @author luo
* 分析:
* 1,分解:以a[p]为基准将啊[p:r]划分为3段:a[p:q-1](小于基准元素),a[q](等于基准元素即就是a[p]),a[q+1:r](大于基准)
* 2,递归求解
* 3,合并
*/
public class QuickSort {
/**
* 递归算法
* @param a
* @param p 起始下标
* @param r 结束下标
*/
public static void QuickSort1(int[] a,int p,int r){
if (p < r){
int q = Partition(a,p,r);
QuickSort1(a,p,q-1);
QuickSort1(a,q+1,r);
}
}
/**
* 划分元素
* a[p]为基准元素
* @param a
* @param p 划分起始下标
* @param r 划分结束下标
* @return
*/
public static int Partition(int a[],int p,int r){
int temp=0;//存储交换
int i=p,j=r+1;
/**基准*/
int x=a[p];
while(true)
{
while(a[++i]>x && i<r);//找出比x大的数
while(a[--j]<x);//找出比x小的数
if(i >= j)
{
break;
}
temp=a[i];
a[i]=a[j];
a[j]=temp;
}
a[p]=a[j];
a[j]=x;
return j;
}
}
package QuickSort;
public class Main{
public static void main(String[] args){
int[] a= {2,3,8,9,1};
QuickSort.QuickSort1(a, 0, 4);
for (int i = 0; i < a.length; i++) {
System.out.println(a[i]);
}
}
}3)稳定性
不稳定。(在快速排序的随机选择比较子阶段)
4)复杂度
快速排序的运行时间和划分是否对称有关。
①最坏情况
划分的2个区域包含n-1个和1个元素。
T(n) = T(n-1) + O(n) = O(n^2)
②最好情况
划分对称,2个区域都为n/2个元素。
T(n) = 2T(n/2) + O(n) = O(nlogn)
9, 冒泡排序(Bubble Sort,泡沫排序或气泡排序)
1)原理
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
2)代码实现
改进(增加交换标记)
package AllSort;
import java.nio.channels.ShutdownChannelGroupException;
public class Main {
public static void main(String[] args){
int[] arr = new int[]{1,9,4,2,8};
BubbleSort.sort(arr);
show("冒泡排序结果:", arr);
}
private static void show(String s, int[] arr){
String result = s;
for (int i = 0; i < arr.length; i++) {
result += arr[i];
result += ",";
}
System.out.println(result);
}
}package AllSort;
public class Swap {
public static void Swap(int[] arr, int a, int b){
int temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
}package AllSort;
/**
* 冒泡排序
* @author luo
*
*/
public class BubbleSort {
public static void sort(int[] a){
boolean isSwap = false;//交换标准。未发生交换为false
for (int i = 0; i < a.length; i++) {
isSwap = false;
for(int j = 0; j< a.length - 1 - i; j++){
if (a[j] > a[j+1]) {
Swap.Swap(a, j, j+1);
isSwap = true;
}
}
if(!isSwap){
break;
}
}
}
}3)稳定性
稳定。
4)复杂度
最好的情况,n-1次比较,移动次数为0,时间复杂度为O(n)。
最坏的情况,n(n-1)/2次比较,等数量级的移动,时间复杂度为O(O^2)。
平均时间复杂度:O(n^2)
空间复杂度:O(1)
10, 简单选择排序
1)原理
设所排序序列的记录个数为n。i取1,2,…,n-1,从所有n-i+1个记录(Ri,Ri+1,…,Rn)中找出排序码最小的记录,与第i个记录交换。执行n-1趟 后就完成了记录序列的排序。
2)代码实现
/**
* 简单选择排序
* 原理:从i到args.length-1,每次迭代将i到args.length-1中最小(最大)的那个数交换到i的位置,然后i++,再循环
* @param array 待排序的数组
*/
public static void simpleSelectMethod(int[] array) {
//minLoc用于记录i+1到args.length-1这个区间的最小值的下标(i会递增),i表示要交换的位置。
for (int i = 0, j = 0, minLoc = 0; i < array.length; i++) {
minLoc = i;
for (j = i + 1; j < array.length; j++) {//找出i+1到args.length-1这个区间的最小值的下标
if (array[j] < array[minLoc]) {
minLoc = j;
}
}
if (minLoc != i) {//如果minLoc!=i,说明minLoc有变化,就进行交换
int temp = array[i];
array[i] = array[minLoc];
array[minLoc] = temp;
}
}
OutputMessage.showMessage(array);
}3)稳定性
不稳定。
4)复杂度
最坏情况:比较次数为 n(n-1)/2,交换次数为n-1;
最好情况:比较次数为 n(n-1)/2,交换次数为0。
平均:O(n^2)
11,堆排序
1)原理
①构建最大堆。
②选择顶,并与第0位置元素交换
③由于步骤2的的交换可能破环了最大堆的性质,第0不再是最大元素,需要调用maxHeap调整堆(沉降法),如果需要重复步骤2
是对树型选择排序占用空间多的改进。
堆的定义
定义一:
小(大)根堆:完全二叉树中任意结点小于(大于)其孩子。
定义二:
n个元素的序列{k1,k2,…,kn}满足以下关系时,称为堆。

2)代码实现
public static void heapSort(int[] array) {
if (array == null || array.length <= 1) {
return;
}
buildMaxHeap(array);
for (int i = array.length - 1; i >= 1; i--) {
ArrayUtils.exchangeElements(array, 0, i);
maxHeap(array, i, 0);
}
OutputMessage.showMessage(array);
}
private static void buildMaxHeap(int[] array) {
if (array == null || array.length <= 1) {
return;
}
int half = array.length / 2;
for (int i = half; i >= 0; i--) {
maxHeap(array, array.length, i);
}
}
private static void maxHeap(int[] array, int heapSize, int index) {
int left = index * 2 + 1;
int right = index * 2 + 2;
int largest = index;
if (left < heapSize && array[left] > array[index]) {
largest = left;
}
if (right < heapSize && array[right] > array[largest]) {
largest = right;
}
if (index != largest) {
ArrayUtils.exchangeElements(array, index, largest);
maxHeap(array, heapSize, largest);
}
}package util;
public class ArrayUtils {
public static void printArray(int[] array) {
System.out.print("{");
for (int i = 0; i < array.length; i++) {
System.out.print(array[i]);
if (i < array.length - 1) {
System.out.print(", ");
}
}
System.out.println("}");
}
public static void exchangeElements(int[] array, int index1, int index2) {
int temp = array[index1];
array[index1] = array[index2];
array[index2] = temp;
}
}
3)稳定性
不稳定
4)复杂度
时间复杂度 O(nlogn)
5)举例
输出对顶元素后,调整剩余元素成为一个新堆
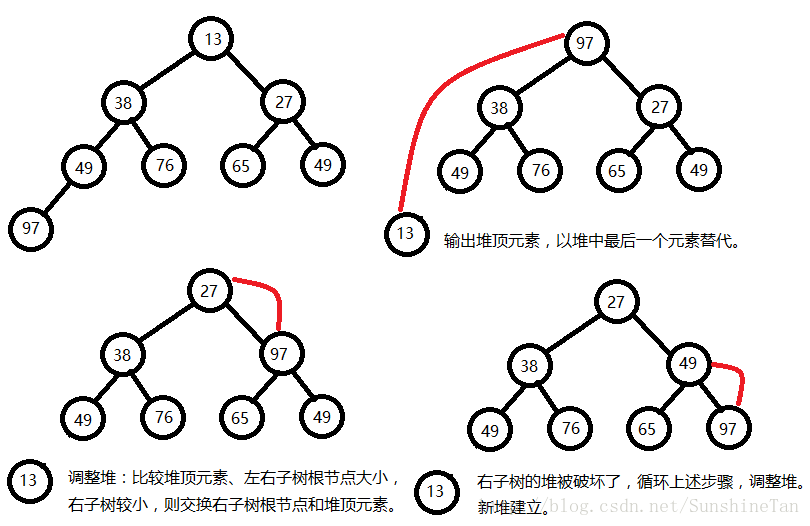
将无序序列建成一个堆:
对于无序序列{49,38,65,97,76,13,27,49},依次放入二叉树。自叶子结点到堆顶筛选,如图所示。
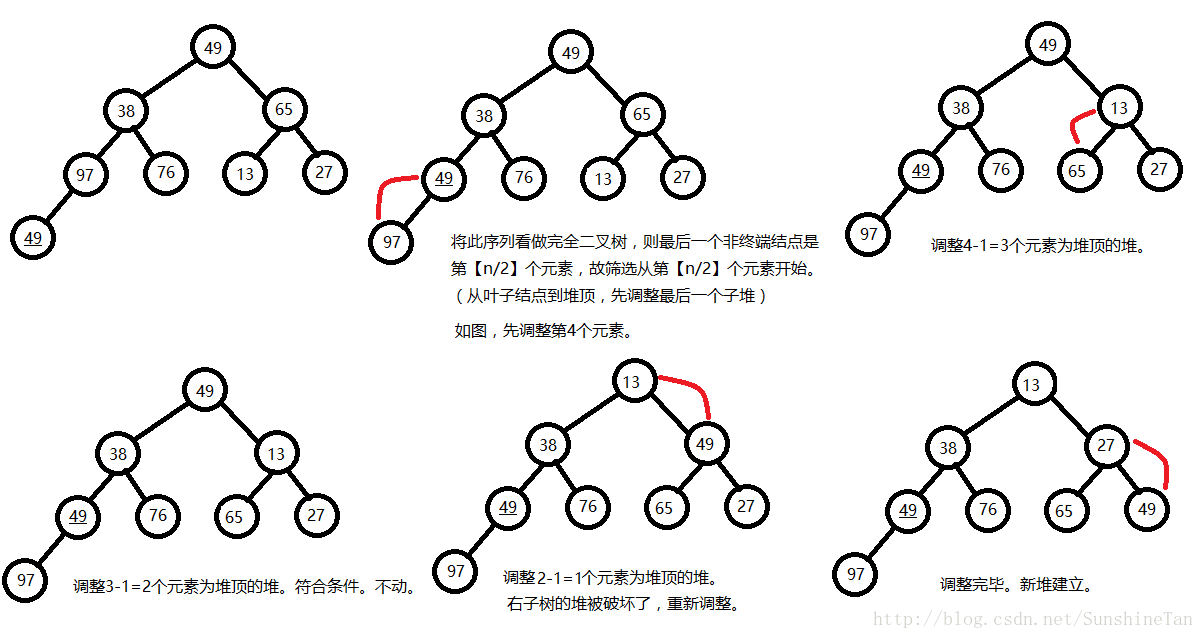
12, 合并排序(Merging Sort,归并排序)
1)原理
将待排序元素分成大小大致相同的2个子集,分别对2个子集(继续分)进行排序,最终将排好序的子集合并。
2)代码实现
递归、分治法
package MergeSort;
/**
* 合并排序
* @author luo
*
*/
public class MergeSort {
/**
* 递归法
* @param a
* @param n
*/
public static void MergeSort1(int[] a, int left, int right){
int b[] = new int[right + 1];//用来存储的
if(left < right){//下标合法(至少有2个元素)
int mid = (left + right)/2;//取中点
MergeSort1(a, left, mid);//排序前半部分
MergeSort1(a, mid + 1, right);//排序后半部分
Merge(a, b, left, mid, right);//将a的前后两半段合并排序
Copy(a, b, left, right);//b复制回a
}
}
/**
* 将b数组复制回a
* @param a
* @param b
* @param left 起始下标
* @param right 结束下标
*/
public static void Copy(int[] a, int[] b, int left, int right){
for (int i = left; i <= right; i++) {
a[i] = b[i];
}
}
/**
*
* 分治思想的合并排序
* 基本思想:将待排序元素分成大小大致相同的2个子集合,分别对2个集合排序,最终将排序好的子集合合并。
* @param a
* @param n
*/
public static void MergeSort2(int[] a, int n){
int b[] = new int[n];
/**合并大小*/
int size = 1;
while(size < n){
MergePass(a, b, size, n);//合并到b数组
size += size;
MergePass(b, a, size, n);//合并到a数组
}
}
/**
* 合并到y数组,合并大小为s的相邻子数组
* @param x
* @param y x和y合并到y数组
* @param s 合并大小
* @param n
*/
public static void MergePass(int[] x, int[] y, int s, int n){
int i=0,j;//循环变量
while(i <= n-2*s){
Merge(x,y,i,i+s-1,i+2*s-1);
i = i + 2 * s;
}
//剩下的元素个数少于2s
if( i+s < n )
Merge( x, y, i, i+s-1, n-1 );
else
for( j=i; j<=n-1; j++ )
y[j] = x[j];
}
/**
* 合并操作:合并排好序的函数,放在d数组
* 合并 c[l:m]和 c[l+m: r] 到 d[l:r],既将2个子集合合并为一个大的集合
* @param c
* @param d
* @param l
* @param m
* @param r
*/
public static void Merge(int[] c, int[] d, int l, int m, int r){
int i=l, j=m+1, index_d = l, q;
//判断下标有没有越界
while( (i <= m) && (j <= r) ){
if(c[i]<=c[j]){
//一般比较第i个数和第i+1的数
d[index_d++]=c[i++];//前者小,将前者放到d数组中
}else{
d[index_d++]=c[j++];//否则将后者放到d数组中
}
}
if(i>m){
for(q=j; q<=r; q++){
d[index_d++] = c[q];
}
}else{
for(q=i;q<=m;q++){
d[index_d++]=c[q];
}
}
}
}package MergeSort;
import java.util.Scanner;
public class Main{
private static int MAX_SIZE = 10;
public static void main(String[] args){
int i,n;//n是个数
int a1[] = new int[MAX_SIZE];//升序排列,head[]里放小数,tail放大数。
int a2[] = new int[MAX_SIZE];//升序排列,head[]里放小数,tail放大数。
System.out.println("请输入您需要排序数的总数: ");
Scanner in = new Scanner(System.in);
n = in.nextInt();
System.out.println("请输入排序数: ");
for(i=0; i<n; i++){
a1[i] = in.nextInt();
a2[i] = in.nextInt();
}
MergeSort.MergeSort1( a1, 0, n-1 );//合并排序
MergeSort.MergeSort2( a2, n );//合并排序
System.out.println("排序完成:");
String result_Str1 = "";
String result_Str2 = "";
for(i=0; i<n; i++){
result_Str1 += a1[i];
result_Str1 += " ";
result_Str2 += a2[i];
result_Str2 += " ";
}
System.out.println("MergeSort1:" + result_Str1);
System.out.println("MergeSort2:" + result_Str2);
}
}3)稳定性
稳定。
4)复杂度
T(n)=2T(n/2) + O(n) = O(nlogn)
5)举例
13, 基数排序(Radix Sorting,桶排序bucket sort)
基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或bin sort。
1)原理
将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
基数排序的方式可以采用LSD(Least significant digital)或MSD(Most significant digital),LSD的排序方式由键值的最右边开始,而MSD则相反,由键值的最左边开始。
①最高位优先(MSD,Most Significant Digit first)法
先按k1排序分组,同一组中记录,关键码k1相等,再对各组按k2排序分成子组,之后,对后面的关键码继续这样的排序分组,直到按最次位关键码kd对各子组排序后。再将各组连接起来,便得到一个有序序列。
②最低位优先(LSD,Least Significant Digit first)法
先从kd开始排序,再对kd-1进行排序,依次重复,直到对k1排序后便得到一个有序序列。
2)代码实现
public static void RadixSort(int[] number, int d){ //d表示最大的数有多少位
int k = 0;
int n = 1;
int m = 1; //控制键值排序依据在哪一位
int[][] temp = new int[10][number.length]; //数组的第一维表示可能的余数0-9
int[] order = new int[10]; //数组orderp[i]用来表示该位是i的数的个数
while (m <= d) {
for (int i = 0; i < number.length; i++) {
int lsd = ((number[i] / n) % 10);
temp[lsd][order[lsd]] = number[i];
order[lsd]++;
}
for (int i = 0; i < 10; i++) {
if (order[i] != 0)
for (int j = 0; j < order[i]; j++) {
number[k] = temp[i][j];
k++;
}
order[i] = 0;
}
n *= 10;
k = 0;
m++;
}
}3)稳定性
稳定。
4)复杂度
时间效率 :设待排序列为n个记录,d个关键码,关键码的取值范围为radix,则进行链式基数排序的时间复杂度为O(d(n+radix)),其中,一趟分配时间复杂度为O(n),一趟收集时间复杂度为O(radix),共进行d趟分配和收集。
空间效率:需要2*radix个指向队列的辅助空间,以及用于静态链表的n个指针。
5)举例
以LSD为例,假设原来有一串数值如下所示:
73, 22, 93, 43, 55, 14, 28, 65, 39, 81
首先根据个位数的数值,在走访数值时将它们分配至编号0到9的桶子中:
0
1 81
2 22
3 73 93 43
4 14
5 55 65
6
7
8 28
9 39
第二步
接下来将这些桶子中的数值重新串接起来,成为以下的数列:
81, 22, 73, 93, 43, 14, 55, 65, 28, 39
接着再进行一次分配,这次是根据十位数来分配:
0
1 14
2 22 28
3 39
4 43
5 55
6 65
7 73
8 81
9 93
第三步
接下来将这些桶子中的数值重新串接起来,成为以下的数列:
14, 22, 28, 39, 43, 55, 65, 73, 81, 93
这时候整个数列已经排序完毕;如果排序的对象有三位数以上,则持续进行以上的动作直至最高位数为止。LSD的基数排序适用于位数小的数列,如果位数多的话,使用MSD的效率会比较好。MSD的方式与LSD相反,是由高位数为基底开始进行分配,但在分配之后并不马上合并回一个数组中,而是在每个“桶子”中建立“子桶”,将每个桶子中的数值按照下一数位的值分配到“子桶”中。在进行完最低位数的分配后再合并回单一的数组中。
14,Bit排序算法(位排序、bitmap算法)
1)原理
32位机器上,一个整形,比如int a; 在内存中占32bit位,可以用对应的32bit位对应十进制的0-31个数,bitmap算法利用这种思想处理大量数据的排序与查询.
①表示
第一个4就是(从最后一位开始,分别代表0 1 2 3 4 ……)
00000000000000000000000000010000
而输入2的时候
00000000000000000000000000010100
输入3时候
00000000000000000000000000011100
输入1的时候
00000000000000000000000000011110思想比较简单,关键是十进制和二进制bit位需要一个map图,把十进制的数映射到bit位。
②map映射表
假设需要排序或者查找的总数N=10000000,那么我们需要申请内存空间的大小为int a[1 + N/32],其中:a[0]在内存中占32位可以对应十进制数0-31,依次类推:
bitmap表为:
a[0]--------->0-31
a[1]--------->32-63
a[2]--------->64-95
a[3]--------->96-127
……那么十进制数如何转换为对应的bit位,下面介绍用位移将十进制数转换为对应的bit位。
③位移转换
对于十进制数n, n/32为对应数组下标;n%32为数组内第几个数。
如:n=24,那么 n/32=0,则24在a[0]数组中,左右往左第n%32=24位的位置上。
利用移位0-31使得对应32bit位为1.
2)优缺点
优点:
1.运算效率高,不许进行比较和移位;
2.占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M。
缺点:
所有的数据不能重复。即不可对重复的数据进行排序和查找。
3)举例
对1亿个不重复的正整数(0-99999999)进行排序,内存只有50MB。(出自《编程珠玑》)
思路:充分利用计算机的每一个bit位来节约空间。如上需求中,我们预设1亿个bit位,初始置0。从待排序集合中每读取一个数,在对应的第多少位bit上置1。最后,遍历该bit位集合,每个为1的bit位,则输出对应的正整数,最终输出结果已经排序完成,所需内存空间仅需:1亿bit/8=12.5MB。
实现方案:使用int数组来模拟bit位序列。1 int = 4 byte = 32 bit,因此需要1亿/32=3125000个int数来表达1亿个bit位。
4)C代码实现
#include <stdio.h>
#define BITSPERWORD 32
#define SHIFT 5
#define MASK 0x1F
#define N 10000000
int a[1 + N/BITSPERWORD];//申请内存的大小
//set 设置所在的bit位为1
//clr 初始化所有的bit位为0
//test 测试所在的bit为是否为1
void set(int i) { a[i>>SHIFT] |= (1<<(i & MASK)); }
void clr(int i) { a[i>>SHIFT] &= ~(1<<(i & MASK)); }
int test(int i){ return a[i>>SHIFT] & (1<<(i & MASK)); }
int main()
{ int i;
for (i = 0; i < N; i++)
clr(i);
while (scanf("%d", &i) != EOF)
set(i);
for (i = 0; i < N; i++)
if (test(i))
printf("%d\n", i);
return 0;
}windows系统下,在输入回车换行后的空行位置,按 ctrl+z,再回车确认,即可输入EOF。
代码中:
①i>>SHIFT
i右移5位,2^5=32,相当于i/32,即求出十进制i对应在数组a中的下标。
②i & MASK
其中MASK=0X1F,十六进制转化为十进制为31,二进制为0001 1111,i&(0001 1111)相当于保留i的后5位。 相当于i%32
15, TopN算法
有N(N>>10000)个整数,求出其中的前K个最大的数。(TopK问题,Top10问题)。
1.最简单的方法:将n个数排序,排序后的前k个数就是最大的k个数,这种算法的复杂度是O(nlogn)(选出的这m个数排好序了)
2.O(n)的方法:利用快排的patition思想,基于数组的第m个数来调整,将比第m个数小的都位于数组的左边,比第m个数大的都调整到数组的右边,这样调整后,位于数组右边的m个数最大的数(这m个数不一定是排好序的)(选出的这m个数可能无序) 如下方法(3)
3.O(nlogk)的方法:先创建一个大小为m的最小堆,接下来我们每次从输入的n个整数中读入一个数,如果这个数比最小堆的堆顶元素还要大,那么替换这个最小堆的堆顶并调整。如下方法(1)(2)
1)采用小顶堆或者大顶堆
①原理
根据数据前K个建立K个节点的小顶堆,在后面的N-K的数据的扫描中,如果数据大于小顶堆的根节点,则根节点的值覆为该数据,并调节节点至小顶堆。如果数据小于或等于小顶堆的根节点,小根堆无变化。
②场景
求最大K个采用小顶堆,而求最小K个采用大顶堆。
③代码
package sort;
import io.OutputMessage;
public class TopKByHeap {
/**
* 创建k个节点的小根堆
*
* @param a
* @param k
* @return
*/
private static int[] createHeap(int a[], int k) {
int[] result = new int[k];
for (int i = 0; i < k; i++) {
result[i] = a[i];
}
for (int i = 1; i < k; i++) {
int child = i;
int parent = (i - 1) / 2;
int temp = a[i];
while (parent >= 0 &&child!=0&& result[parent] >temp) {
result[child] = result[parent];
child = parent;
parent = (parent - 1) / 2;
}
result[child] = temp;
}
return result;
}
private static void insert(int a[], int value) {
a[0]=value;
int parent=0;
while(parent<a.length){
int lchild=2*parent+1;
int rchild=2*parent+2;
int minIndex=parent;
if(lchild<a.length&&a[parent]>a[lchild]){
minIndex=lchild;
}
if(rchild<a.length&&a[minIndex]>a[rchild]){
minIndex=rchild;
}
if(minIndex==parent){
break;
}else{
int temp=a[parent];
a[parent]=a[minIndex];
a[minIndex]=temp;
parent=minIndex;
}
}
}
public static int[] getTopKByHeap(int input[], int k) {
int heap[] = createHeap(input, k);
for(int i=k;i<input.length;i++){
if(input[i]>heap[0]){
insert(heap, input[i]);
}
}
return heap;
}
} TopKByHeap.getTopKByHeap(a,3);2)PriorityQueue优先队列:
①原理
PriorityQueue是从JDK1.5开始提供的新的数据结构接口,它是一种基于优先级堆的极大优先级队列。优先级队列是不同于先进先出队列的另一种队列。每次从队列中取出的是具有最高优先权的元素。如果不提供Comparator的话,优先队列中元素默认按自然顺序排列,也就是数字默认是小的在队列头,字符串则按字典序排列(参阅 Comparable),也可以根据 Comparator 来指定,这取决于使用哪种构造方法。优先级队列不允许 null 元素。依靠自然排序的优先级队列还不允许插入不可比较的对象(这样做可能导致 ClassCastException)。
PriorityQueue构造固定容量的优先队列,模拟大顶堆,这种队列本身数组实现,无容量限制,可以指定队列长度和比较方式,然后将数据依次压入,当队列满时会poll出小值,最后需要注意的是,priorityQueue本身遍历是无序的,可以使用内置poll()方法,每次从队首取出元素。
②代码
package sort;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.Iterator;
import java.util.List;
import java.util.PriorityQueue;
import java.util.Random;
/**
* 固定容量的优先队列,模拟大顶堆,用于解决求topN小的问题
* @author 张恩备
* @date 2016-11-25 下午02:29:31
*/
public class FixSizedPriorityQueue<E extends Comparable> {
private PriorityQueue<E> queue;
private int maxSize; // 堆的最大容量
public FixSizedPriorityQueue(int maxSize) {
if (maxSize <= 0)
throw new IllegalArgumentException();
this.maxSize = maxSize;
this.queue = new PriorityQueue(maxSize, new Comparator<E>() {
public int compare(E o1, E o2) {
// 生成最大堆使用o2-o1,生成最小堆使用o1-o2, 并修改 e.compareTo(peek) 比较规则
return (o2.compareTo(o1));
}
});
}
public void add(E e) {
if (queue.size() < maxSize) { // 未达到最大容量,直接添加
queue.add(e);
} else { // 队列已满
E peek = queue.peek();
if (e.compareTo(peek) < 0) { // 将新元素与当前堆顶元素比较,保留较小的元素
queue.poll();
queue.add(e);
}
}
}
public List<E> sortedList() {
List<E> list = new ArrayList<E>(queue);
Collections.sort(list); // PriorityQueue本身的遍历是无序的,最终需要对队列中的元素进行排序
return list;
}
public void printResult(){
// 或者直接用内置的 poll() 方法,每次取队首元素(堆顶的最大值)
while (!queue.isEmpty()) {
System.out.print(queue.poll() + ", ");
}
}
} final FixSizedPriorityQueue pq = new FixSizedPriorityQueue<Integer>(3);
for (int i=0; i<a.length; i++) {
pq.add(a[i]);
}
pq.printResult();3)快排过程法
①原理
实现步骤:根据快排规则,选择一个数为基准(代码是以最后一个数)分化数据,并记录基准数最后的落点下标,最后判断下标和k-1值大小(下标从0开始),不相等就继续朝k-1数量方向分化:
下标小于k-1,对下标右侧(partion,end)继续二分;
下标大于k-1,对下标左侧(first,partion)继续二分;
直到k个数为top,但这k个数并没有顺序。
②场景
适用于无序单个数组,快排过程法利用快速排序的过程来求Top k。
③代码
public class TopK{
int partion(int a[],int first,int end){
int i=first;
int main=a[end];
for(int j=first;j<end;j++){
if(a[j]<main){
int temp=a[j];
a[j]=a[i];
a[i]=temp;
i++;
}
}
a[end]=a[i];
a[i]=main;
return i;
}
void getTopKMinBySort(int a[],int first,int end,int k){
if(first<end){
int partionIndex=partion(a,first,end);
if(partionIndex==k-1)return;
else if(partionIndex>k-1)getTopKMinBySort(a,first,partionIndex-1,k);
else getTopKMinBySort(a,partionIndex+1,end,k);
}
}
public static void main(String []args){
int a[]={2,20,3,7,9,1,17,18,0,4};
int k=6;
new TopK().getTopKMinBySort(a,0,a.length-1,k);
for(int i=0;i<k;i++){
System.out.print(a[i]+" ");
}
}
} 4)合并法
①原理
实现描述:采用Merge的方法,设定一个数组下标扫描位置记录临时数组和top结果数组,然后从临时数组记录下标开始遍历所有数组并比较大小,将最大值存入结果数组,最大值对应所在数组下标加一存入临时数组,以使其从下位开始遍历,时间复杂度为O(k*m)。(m:为数组的个数)。
②场景
这种方法适用于几个数组有序的情况,来求Top k。
③代码
/**
* 已知几个递减有序的m个数组,求这几个数据前k大的数
* a[4,3,2,1],b[6,5,3,1] -> result[6,5,4]
*/
public class TopKByMerge{
public static int[] getTopK(List<List<Integer>>input,int k){
int index[]=new int[input.size()];//保存每个数组下标扫描的位置;
int result[]=new int[k];
for(int i=0;i<k;i++){
int max=Integer.MIN_VALUE;
int maxIndex=0;
for(int j=0;j<input.size();j++){
if(index[j]<input.get(j).size()){
if(max<input.get(j).get(index[j])){
max=input.get(j).get(index[j]);
maxIndex=j;
}
}
}
if(max==Integer.MIN_VALUE){
return result;
}
result[i]=max;
index[maxIndex]+=1;
}
return result;
}
public static void main(String[] args) {
List<Integer> a = new ArrayList<Integer>();
a.add(4);
a.add(3);
a.add(2);
a.add(1);
List<Integer> b = new ArrayList<Integer>();
b.add(6);
b.add(5);
b.add(3);
b.add(1);
List<List<Integer>> ab = new ArrayList<List<Integer>>();
ab.add(a);
ab.add(b);
int r[] = getTopK(ab, 3);
for (int i = 0; i < r.length; i++) {
System.out.println(r[i]);
}
}
}