注:本文基于知乎用户@尘落风随的教程,在docker环境搭建了hadoop-3.2.2环境。由于原作者教程写于前几年,部分内容存在些许失误,本文在教程中会标注出修改的地方,并更换了部分软件源。转侵删。
-
1.1 安装Docker
-
Ubuntu 16.04 安装 Docker
-
-
1.2 使用Docker
-
2.1 安装 Java 与 Scala
-
2.1.1 修改 apt 源
-
2.1.2 安装 Scala 与 Java
-
-
2.2 安装 Hadoop
-
2.2.1 安装 Vim 与 网络工具包
-
2.2.2 安装 SSH
-
2.2.3 安装 Hadoop
-
2.2.4 在 Docker 中启动集群
-
2.2.5 运行内置WordCount例子
-
绪论
使用Docker搭建Hadoop技术平台,包括安装Docker、Java、Scala、Hadoop
集群共有5台机器,主机名分别为 h01、h02、h03、h04、h05。其中 h01 为 master,其他的为 slave。
-
JDK 1.8
-
Scala 2.11.6
-
Hadoop 3.2.2 【原文是3.2.0,但软件源已失效】
1. Docker
1.1 安装Docker
Ubuntu 16.04 安装 Docker
1.2 使用Docker
现在的 Docker 网络能够提供 DNS 解析功能,我们可以使用如下命令为接下来的 Hadoop 集群单独构建一个虚拟的网络。
dhu719@dhu719:~$ sudo docker network create --driver=bridge hadoop
以上命令创建了一个名为 Hadoop 的虚拟桥接网络,该虚拟网络内部提供了自动的DNS解析服务。
使用下面这个命令查看 Docker 中的网络,可以看到刚刚创建的名为 hadoop 的虚拟桥接网络。
dhu719@dhu719:~$ sudo docker network ls
NETWORK ID NAME DRIVER SCOPE
06548c9440f8 bridge bridge local
b21dba8dc351 hadoop bridge local
eb48a64969d1 host host local
3e8c9d771ec8 none null local
dhu719@dhu719:~$
查找 ubuntu 容器
dhu719@dhu719:~$ sudo docker search ubuntu
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
ubuntu Ubuntu is a Debian-based Linux operating sys… 9326 [OK]
dorowu/ubuntu-desktop-lxde-vnc Docker image to provide HTML5 VNC interface … 281 [OK]
rastasheep/ubuntu-sshd Dockerized SSH service, built on top of offi… 209 [OK]
consol/ubuntu-xfce-vnc Ubuntu container with "headless" VNC session… 161 [OK]
ubuntu-upstart Upstart is an event-based replacement for th… 97 [OK]
ansible/ubuntu14.04-ansible Ubuntu 14.04 LTS with ansible 96 [OK]
neurodebian NeuroDebian provides neuroscience research s… 56 [OK]
1and1internet/ubuntu-16-nginx-php-phpmyadmin-mysql-5 ubuntu-16-nginx-php-phpmyadmin-mysql-5 49 [OK]
ubuntu-debootstrap debootstrap --variant=minbase --components=m… 40 [OK]
nuagebec/ubuntu Simple always updated Ubuntu docker images w… 23 [OK]
tutum/ubuntu Simple Ubuntu docker images with SSH access 19
下载 ubuntu 16.04 版本的镜像文件
dhu719@dhu719:~$ sudo docker pull ubuntu:16.04
16.04: Pulling from library/ubuntu
34667c7e4631: Pull complete
d18d76a881a4: Pull complete
119c7358fbfc: Pull complete
2aaf13f3eff0: Pull complete
Digest: sha256:58d0da8bc2f434983c6ca4713b08be00ff5586eb5cdff47bcde4b2e88fd40f88
Status: Downloaded newer image for ubuntu:16.04
dhu719@dhu719:~$
查看已经下载的镜像
dhu719@dhu719:~$ sudo docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
<none> <none> ccac37c7045c 4 days ago 1.85GB
ubuntu 16.04 9361ce633ff1 7 days ago 118MB
dhu719@dhu719:~$
根据镜像启动一个容器,可以看出 shell 已经是容器的 shell 了
dhu719@dhu719:~$ sudo docker run -it ubuntu:16.04 /bin/bash
root@fab4da838c2f:/#
输入 exit 可以退出容器
root@fab4da838c2f:/# exit
exit
dhu719@dhu719:~$
查看本机上所有的容器
dhu719@dhu719:~$ sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
fab4da838c2f ubuntu:16.04 "/bin/bash" 2 minutes ago Exited (0) 49 seconds ago nifty_pascal
dhu719@dhu719:~$
启动一个状态为退出的容器,最后一个参数为容器 ID
dhu719@dhu719:~$ sudo docker start fab4da838c2f
fab4da838c2f
dhu719@dhu719:~$
进入一个容器
并不是所有容器都可以这么干
dhu719@dhu719:~$ sudo docker exec -it fab4da838c2f /bin/bash
root@fab4da838c2f:/#
查看正在运行的容器
dhu719@dhu719:~$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
fab4da838c2f ubuntu:16.04 "/bin/bash" 7 minutes ago Up 3 minutes nifty_pascal
dhu719@dhu719:~$
关闭一个容器
dhu719@dhu719:~$ sudo docker stop fab4da838c2f
fab4da838c2f
dhu719@dhu719:~$
以上,Docker 的基础使用,在下面会用到,大部分的操作都会在容器里完成,比用虚拟机安装好多了。
2. 安装集群
主要是安装 JDK 1.8 的环境,因为 Spark 要 Scala,Scala 要 JDK 1.8,以及 Hadoop,以此来构建基础镜像。
2.1 安装 Java 与 Scala
进入之前的 Ubuntu 容器
先更换 apt 的源
2.1.1 修改 apt 源
备份源
root@fab4da838c2f:/# cp /etc/apt/sources.list /etc/apt/sources_init.list
root@fab4da838c2f:/#
先删除源文件,这个时候没有 vim 工具..
root@fab4da838c2f:/# rm /etc/apt/sources.list
使用 echo 命令将源写入新文件
root@fab4da838c2f:/# echo "deb http://mirrors.aliyun.com/ubuntu/ xenial main
> deb-src http://mirrors.aliyun.com/ubuntu/ xenial main
>
> deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main
> deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates main
>
> deb http://mirrors.aliyun.com/ubuntu/ xenial universe
> deb-src http://mirrors.aliyun.com/ubuntu/ xenial universe
> deb http://mirrors.aliyun.com/ubuntu/ xenial-updates universe
> deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates universe
>
> deb http://mirrors.aliyun.com/ubuntu/ xenial-security main
> deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security main
> deb http://mirrors.aliyun.com/ubuntu/ xenial-security universe
> deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security universe" > /etc/apt/sources.list
root@fab4da838c2f:#
阿里源如下
deb http://mirrors.aliyun.com/ubuntu/ xenial main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial main
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates main
deb http://mirrors.aliyun.com/ubuntu/ xenial universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial universe
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates universe
deb http://mirrors.aliyun.com/ubuntu/ xenial-security main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security main
deb http://mirrors.aliyun.com/ubuntu/ xenial-security universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security universe
再使用 apt update 来更新
apt update
2.1.2 安装 Scala 与 Java
直接输入命令
root@fab4da838c2f:/# apt install openjdk-8-jdk
来安装 jdk 1.8
测试一下安装结果
root@fab4da838c2f:/# java -version
openjdk version "1.8.0_191"
OpenJDK Runtime Environment (build 1.8.0_191-8u191-b12-2ubuntu0.16.04.1-b12)
OpenJDK 64-Bit Server VM (build 25.191-b12, mixed mode)
root@fab4da838c2f:/#
再输入
root@fab4da838c2f:/# apt install scala
直接安装 Scala
测试一下安装结果
root@fab4da838c2f:/# scala
Welcome to Scala version 2.11.6 (OpenJDK 64-Bit Server VM, Java 1.8.0_191).
Type in expressions to have them evaluated.
Type :help for more information.
scala>
按 Ctrl + D 退出 Scala 的交互模式
2.2 安装 Hadoop
-
在当前容器中将配置配好
-
导出为镜像
-
以此镜像为基础创建五个容器,并赋予 hostname
-
进入 h01 容器,启动 Hadoop
2.2.1 安装 Vim 与 网络工具包
安装 vim,用来编辑文件
root@fab4da838c2f:/# apt install vim
安装 net-tools
root@fab4da838c2f:/# apt install net-tools
2.2.2 安装 SSH
安装 SSH,并配置免密登录,由于后面的容器之间是由一个镜像启动的,就像同一个模具出来的 5 把锁与钥匙,可以互相开锁。所以在当前容器里配置 SSH 自身免密登录就 OK 了。
安装 SSH
root@fab4da838c2f:/# apt-get install openssh-server
安装 SSH 的客户端
root@fab4da838c2f:/# apt-get install openssh-client
进入当前用户的用户根目录
root@fab4da838c2f:/# cd ~
root@fab4da838c2f:~#
生成密钥,不用输入,一直回车就行,生成的密钥在当前用户根目录下的 .ssh 文件夹中
以
.开头的文件与文件夹ls是看不到的,需要ls -al才能查看。
root@fab4da838c2f:~# ssh-keygen -t rsa -P ""
将公钥追加到 authorized_keys 文件中
root@fab4da838c2f:~# cat .ssh/id_rsa.pub >> .ssh/authorized_keys
root@fab4da838c2f:~#
启动 SSH 服务
root@fab4da838c2f:~# service ssh start
* Starting OpenBSD Secure Shell server sshd [ OK ]
root@fab4da838c2f:~#
免密登录自己
root@fab4da838c2f:~# ssh 127.0.0.1
Welcome to Ubuntu 16.04.6 LTS (GNU/Linux 4.15.0-45-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
Last login: Tue Mar 19 07:46:14 2019 from 127.0.0.1
root@fab4da838c2f:~#
修改 .bashrc 文件,启动 shell 的时候,自动启动 SSH 服务
用 vim 打开 .bashrc 文件
root@fab4da838c2f:~# vim ~/.bashrc
按一下 i 键,使得 vim 进入插入模式,此时终端的左下角会显示为 -- INSERT --,将光标移动到最后面,添加一行
service ssh start
添加完的结果为,只显示最后几行
if [ -f ~/.bash_aliases ]; then
. ~/.bash_aliases
fi
# enable programmable completion features (you don't need to enable
# this, if it's already enabled in /etc/bash.bashrc and /etc/profile
# sources /etc/bash.bashrc).
#if [ -f /etc/bash_completion ] && ! shopt -oq posix; then
# . /etc/bash_completion
#fi
service ssh start
按一下 Esc 键,使得 vim 退出插入模式
再输入英文模式下的冒号 :,此时终端的左下方会有一个冒号 : 显示出来
再输入三个字符 wq!,这是一个组合命令
-
w是保存的意思 -
q是退出的意思 -
!是强制的意思
再输入回车,退出 vim。
此时,SSH 免密登录已经完全配置好。
2.2.3 安装 Hadoop
下载 Hadoop 的安装文件
root@fab4da838c2f:~# wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
【注:原文这里的hadoop3.2.0已失效,这里替换为清华开源软件镜像站提供的hadoop3.2.2,后续涉及到hadoop版本的地方也一并进行了更换,不再赘述】
解压到 /usr/local 目录下面并重命名文件夹
root@fab4da838c2f:~# tar -zxvf hadoop-3.2.2.tar.gz -C /usr/local/
root@fab4da838c2f:~# cd /usr/local/
root@fab4da838c2f:/usr/local# mv hadoop-3.2.2 hadoop
root@fab4da838c2f:/usr/local#
修改 /etc/profile 文件,添加一下环境变量到文件中
先用 vim 打开 /etc/profile
vim /etc/profile
追加以下内容
JAVA_HOME 为 JDK 安装路径,使用 apt 安装就是这个,用
update-alternatives --config java可查看
#java
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#hadoop
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_DATANODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
【注:原文中HADOOP_CONF_DIR处变量地址有误,HADOOP_PREFIX应为HADOOP_HOME,本文已做出修正 】
使环境变量生效
root@fab4da838c2f:/usr/local# source /etc/profile
root@fab4da838c2f:/usr/local#
在目录 /usr/local/hadoop/etc/hadoop 下
-
修改 hadoop-env.sh 文件,在文件末尾添加一下信息
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
-
修改 core-site.xml,修改为
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://h01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop3/hadoop/tmp</value>
</property>
</configuration>
-
修改 hdfs-site.xml,修改为
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop3/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>/home/hadoop3/hadoop/hdfs/data</value>
</property>
</configuration>
-
修改 mapred-site.xml,修改为
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
-
修改 yarn-site.xml,修改为
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>h01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
-
修改 workers 为
h01
h02
h03
h04
h05
【注:原文中worker文件名为误写,当前目录中的文件名实为workers】
此时,hadoop已经配置好了
2.2.4 在 Docker 中启动集群
先将当前容器导出为镜像,并查看当前镜像
dhu719@dhu719:~$ sudo docker commit -m "haddop" -a "hadoop" fab4da838c2f newhadoop
sha256:648d8e082a231919faeaa14e09f5ce369b20879544576c03ef94074daf978823
dhu719@dhu719:~$ sudo docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
newuhadoop latest 648d8e082a23 7 seconds ago 1.82GB
<none> <none> ccac37c7045c 4 days ago 1.85GB
ubuntu 16.04 9361ce633ff1 7 days ago 118MB
dhu719@dhu719:~$
【注:原文里此处及以下命令中,镜像名作者均误写为newuhadoop,实为newhadoop,本文已修正】
启动 5 个docker终端,分别执行这几个命令
第一条命令启动的是 h01 是做 master 节点的,所以暴露了端口,以供访问 web 页面
--network hadoop 参数是将当前容器加入到名为
hadoop的虚拟桥接网络中,此网站提供自动的 DNS 解析功能
dhu719@dhu719:~$ sudo docker run -it --network hadoop -h "h01" --name "h01" -p 9870:9870 -p 8088:8088 newhadoop /bin/bash
* Starting OpenBSD Secure Shell server sshd [ OK ]
root@h01:/#
启动h01后exit退回到dhu719用户,继续启动h02~h05
其余的四条命令就是几乎一样的了
dhu719@dhu719:~$ sudo docker run -it --network hadoop -h "h02" --name "h02" newhadoop /bin/bash
[sudo] password for dhu719:
* Starting OpenBSD Secure Shell server sshd [ OK ]
root@h02:/#
dhu719@dhu719:~$ sudo docker run -it --network hadoop -h "h03" --name "h03" newhadoop /bin/bash
[sudo] password for dhu719:
* Starting OpenBSD Secure Shell server sshd [ OK ]
root@h03:/#
dhu719@dhu719:~$ sudo docker run -it --network hadoop -h "h04" --name "h04" newhadoop /bin/bash
[sudo] password for dhu719:
* Starting OpenBSD Secure Shell server sshd [ OK ]
root@h04:/#
dhu719@dhu719:~$ sudo docker run -it --network hadoop -h "h05" --name "h05" newhadoop /bin/bash
[sudo] password for dhu719:
* Starting OpenBSD Secure Shell server sshd [ OK ]
root@h05:/#
【注:此处代码可以进行优化。为减少进入/退出h02~h05容器与反复输密码的操作,可以在指令中添加-d参数。以h02为例,具体代码为sudo docker run -itd --network hadoop -h "h02" --name "h02" newhadoop /bin/bash,运行完毕后只返回容器ID,依然处于当前用户dhu719中。h03 h04 h05同理。】
接下来,在 h01 主机中,启动 Haddop 集群
dhu719@dhu719:~$ sudo docker start h01
dhu719@dhu719:~$ sudo docker exec -it h01 /bin/bash
先进行格式化操作
不格式化操作,hdfs会起不来
root@h01:/usr/local/hadoop/bin# ./hadoop namenode -format
进入 hadoop 的 sbin 目录
root@h01:/# cd /usr/local/hadoop/sbin/
root@h01:/usr/local/hadoop/sbin#
启动
root@h01:/usr/local/hadoop/sbin# ./start-all.sh
Starting namenodes on [h01]
h01: Warning: Permanently added 'h01,172.18.0.7' (ECDSA) to the list of known hosts.
Starting datanodes
h05: Warning: Permanently added 'h05,172.18.0.11' (ECDSA) to the list of known hosts.
h02: Warning: Permanently added 'h02,172.18.0.8' (ECDSA) to the list of known hosts.
h03: Warning: Permanently added 'h03,172.18.0.9' (ECDSA) to the list of known hosts.
h04: Warning: Permanently added 'h04,172.18.0.10' (ECDSA) to the list of known hosts.
h03: WARNING: /usr/local/hadoop/logs does not exist. Creating.
h05: WARNING: /usr/local/hadoop/logs does not exist. Creating.
h02: WARNING: /usr/local/hadoop/logs does not exist. Creating.
h04: WARNING: /usr/local/hadoop/logs does not exist. Creating.
Starting secondary namenodes [h01]
Starting resourcemanager
Starting nodemanagers
root@h01:/usr/local/hadoop/sbin#
【注:这步很容易报错,前面步骤中很多细节都会导致结点拉不起来。如果报Cannot set priority of namenode process Cannot set priority of datenode process等错误,先去查/usr/local/hadoop/etc/hadoop下面的几个配置文件是否配置正确(比如忘记删),如果仍然排除不了,仔细查看报错原因,然后借助网络求助。】
访问本机的 8088 与 9870 端口就可以看到监控信息了
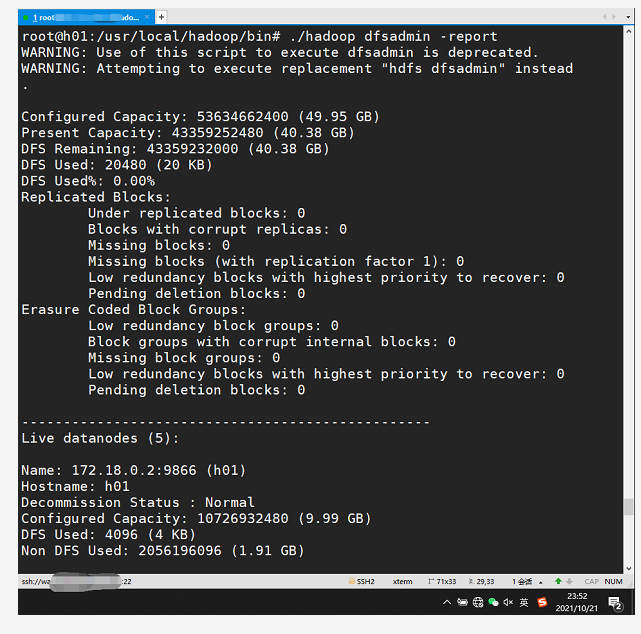
使用命令 ./hadoop dfsadmin -report 可查看分布式文件系统的状态
root@h01:/usr/local/hadoop/bin# ./hadoop dfsadmin -report
WARNING: Use of this script to execute dfsadmin is deprecated.
WARNING: Attempting to execute replacement "hdfs dfsadmin" instead.
Configured Capacity: 5893065379840 (5.36 TB)
Present Capacity: 5237598752768 (4.76 TB)
DFS Remaining: 5237598629888 (4.76 TB)
DFS Used: 122880 (120 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (5):
Name: 172.18.0.10:9866 (h03.hadoop)
Hostname: h03
Decommission Status : Normal
Configured Capacity: 1178613075968 (1.07 TB)
DFS Used: 24576 (24 KB)
Non DFS Used: 71199543296 (66.31 GB)
DFS Remaining: 1047519793152 (975.58 GB)
DFS Used%: 0.00%
DFS Remaining%: 88.88%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Tue Mar 19 09:12:13 UTC 2019
Last Block Report: Tue Mar 19 09:10:46 UTC 2019
Num of Blocks: 0
Name: 172.18.0.11:9866 (h02.hadoop)
Hostname: h02
Decommission Status : Normal
Configured Capacity: 1178613075968 (1.07 TB)
DFS Used: 24576 (24 KB)
Non DFS Used: 71199625216 (66.31 GB)
DFS Remaining: 1047519711232 (975.58 GB)
DFS Used%: 0.00%
DFS Remaining%: 88.88%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Tue Mar 19 09:12:13 UTC 2019
Last Block Report: Tue Mar 19 09:10:46 UTC 2019
Num of Blocks: 0
Name: 172.18.0.7:9866 (h01)
Hostname: h01
Decommission Status : Normal
Configured Capacity: 1178613075968 (1.07 TB)
DFS Used: 24576 (24 KB)
Non DFS Used: 71199633408 (66.31 GB)
DFS Remaining: 1047519703040 (975.58 GB)
DFS Used%: 0.00%
DFS Remaining%: 88.88%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Tue Mar 19 09:12:13 UTC 2019
Last Block Report: Tue Mar 19 09:10:46 UTC 2019
Num of Blocks: 0
Name: 172.18.0.8:9866 (h05.hadoop)
Hostname: h05
Decommission Status : Normal
Configured Capacity: 1178613075968 (1.07 TB)
DFS Used: 24576 (24 KB)
Non DFS Used: 71199625216 (66.31 GB)
DFS Remaining: 1047519711232 (975.58 GB)
DFS Used%: 0.00%
DFS Remaining%: 88.88%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Tue Mar 19 09:12:13 UTC 2019
Last Block Report: Tue Mar 19 09:10:46 UTC 2019
Num of Blocks: 0
Name: 172.18.0.9:9866 (h04.hadoop)
Hostname: h04
Decommission Status : Normal
Configured Capacity: 1178613075968 (1.07 TB)
DFS Used: 24576 (24 KB)
Non DFS Used: 71199625216 (66.31 GB)
DFS Remaining: 1047519711232 (975.58 GB)
DFS Used%: 0.00%
DFS Remaining%: 88.88%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Tue Mar 19 09:12:13 UTC 2019
Last Block Report: Tue Mar 19 09:10:46 UTC 2019
Num of Blocks: 0
root@h01:/usr/local/hadoop/bin#
Hadoop 集群已经构建好了![]()
2.2.5 运行内置WordCount例子
把license作为需要统计的文件
root@h01:/usr/local/hadoop# cat LICENSE.txt > file1.txt
root@h01:/usr/local/hadoop# ls
在 HDFS 中创建 input 文件夹
root@h01:/usr/local/hadoop/bin# ./hadoop fs -mkdir /input
root@h01:/usr/local/hadoop/bin#
上传 file1.txt 文件到 HDFS 中
root@h01:/usr/local/hadoop/bin# ./hadoop fs -put ../file1.txt /input
root@h01:/usr/local/hadoop/bin#
查看 HDFS 中 input 文件夹里的内容
root@h01:/usr/local/hadoop/bin# ./hadoop fs -ls /input
Found 1 items
-rw-r--r-- 2 root supergroup 150569 2019-03-19 11:13 /input/file1.txt
root@h01:/usr/local/hadoop/bin#
运作 wordcount 例子程序
root@h01:/usr/local/hadoop/bin# ./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount /input /output
输出如下
2019-03-19 11:18:23,953 INFO client.RMProxy: Connecting to ResourceManager at h01/172.18.0.7:8032
2019-03-19 11:18:24,381 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1552986653954_0001
2019-03-19 11:18:24,659 INFO input.FileInputFormat: Total input files to process : 1
2019-03-19 11:18:25,095 INFO mapreduce.JobSubmitter: number of splits:1
2019-03-19 11:18:25,129 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
2019-03-19 11:18:25,208 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1552986653954_0001
2019-03-19 11:18:25,210 INFO mapreduce.JobSubmitter: Executing with tokens: []
2019-03-19 11:18:25,368 INFO conf.Configuration: resource-types.xml not found
2019-03-19 11:18:25,368 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2019-03-19 11:18:25,797 INFO impl.YarnClientImpl: Submitted application application_1552986653954_0001
2019-03-19 11:18:25,836 INFO mapreduce.Job: The url to track the job: http://h01:8088/proxy/application_1552986653954_0001/
2019-03-19 11:18:25,837 INFO mapreduce.Job: Running job: job_1552986653954_0001
2019-03-19 11:18:33,990 INFO mapreduce.Job: Job job_1552986653954_0001 running in uber mode : false
2019-03-19 11:18:33,991 INFO mapreduce.Job: map 0% reduce 0%
2019-03-19 11:18:39,067 INFO mapreduce.Job: map 100% reduce 0%
2019-03-19 11:18:45,106 INFO mapreduce.Job: map 100% reduce 100%
2019-03-19 11:18:46,124 INFO mapreduce.Job: Job job_1552986653954_0001 completed successfully
2019-03-19 11:18:46,227 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=46852
FILE: Number of bytes written=537641
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=150665
HDFS: Number of bytes written=35324
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3129
Total time spent by all reduces in occupied slots (ms)=3171
Total time spent by all map tasks (ms)=3129
Total time spent by all reduce tasks (ms)=3171
Total vcore-milliseconds taken by all map tasks=3129
Total vcore-milliseconds taken by all reduce tasks=3171
Total megabyte-milliseconds taken by all map tasks=3204096
Total megabyte-milliseconds taken by all reduce tasks=3247104
Map-Reduce Framework
Map input records=2814
Map output records=21904
Map output bytes=234035
Map output materialized bytes=46852
Input split bytes=96
Combine input records=21904
Combine output records=2981
Reduce input groups=2981
Reduce shuffle bytes=46852
Reduce input records=2981
Reduce output records=2981
Spilled Records=5962
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=111
CPU time spent (ms)=2340
Physical memory (bytes) snapshot=651853824
Virtual memory (bytes) snapshot=5483622400
Total committed heap usage (bytes)=1197998080
Peak Map Physical memory (bytes)=340348928
Peak Map Virtual memory (bytes)=2737307648
Peak Reduce Physical memory (bytes)=311504896
Peak Reduce Virtual memory (bytes)=2746314752
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=150569
File Output Format Counters
Bytes Written=35324
查看 HDFS 中的 /output 文件夹的内容
root@h01:/usr/local/hadoop/bin# ./hadoop fs -ls /output
Found 2 items
-rw-r--r-- 2 root supergroup 0 2019-03-19 11:18 /output/_SUCCESS
-rw-r--r-- 2 root supergroup 35324 2019-03-19 11:18 /output/part-r-00000
查看 part-r-00000 文件的内容
root@h01:/usr/local/hadoop/bin# ./hadoop fs -cat /output/part-r-00000
![]()
恭喜,Hadoop 部分完成了~