更快地训练神经网络是深度学习的重要因素之一。我们通常发现神经网络的这些困难在于其复杂的架构和使用的大量参数。随着数据量、网络和权重的增加,模型的训练时间也会增加,这对建模者和从业者来说都是不利的。在本文中,我们将讨论一些可以加快神经网络训练的技巧和窍门。下面列出了本文要讨论的要点。
1、多 GPU 训练
这个技巧纯粹是为了加速与模型性能无关的神经网络。这个技巧可能会变得昂贵,但它非常有效。一个 GPU 的实现也可以使神经网络的训练更快,但应用更多的 GPU 有更多的好处。如果有人无法在他们的系统中暗示 GPU,他们可以通过在线提供对 GPU 和 TPU 支持的 google collab notebooks 进行查看。
在训练中应用多个 GPU 将数据分布在不同的 GPU 中,这些 GPU 持有网络权重并使它们了解数据的 mini-batch 大小。例如,如果我们有 8192 个批量大小和 256 个 GPU,那么每个 GPU 将有一个大小为 32 的小批量,或者我们可以说 32 个样本来训练一个网络。这意味着网络的训练将变得更快。
2、学习率缩放
这是可以帮助我们提高训练神经网络速度的技巧之一。一般来说,大批量的神经网络训练代表了低验证准确度。在上一节中,我们已经看到应用多个 GPU 会分配批量大小以防止网络训练缓慢。
在 GPU 不可用的情况下,我们还可以执行的一件事是扩展学习率;这个技巧可以补偿小批量的平均效果。例如,当训练超过四个 GPU 时,我们可以将批量大小增加 4 倍。我们还可以将学习率乘以 4 来提高训练速度。
我们也可以说这种方法是学习率预热,它是一种简单的策略,可以以高学习率开始训练模型。一开始,我们可以以较低的学习率开始训练,并在热身阶段将其增加到预设值。较低的学习率可以通过前几个时期。然后学习率会像标准训练中通常发生的那样衰减。
当使用多个 GPU 对网络进行分布式训练时,这两个技巧都很有用。我们还可以发现,无论批量大小和我们使用的 GPU 数量如何,在学习率预热中,难以训练的模型都可以稳定下来。
3、循环学习率表
学习率计划可以有多种类型,其中之一是循环学习率计划,它有助于提高训练神经网络的速度。这主要通过在预定义的上限和下限下增加和减少循环中的学习率来起作用。在一些时间表中,我们发现上限随着训练过程的进展而降低。
一次循环学习率计划是循环学习率计划的一种变体,它在整个训练过程中只增加和减少一次学习率。我们也可以认为它类似于我们在上一节中讨论的学习率预热。这个技巧也可以应用于优化器的动量参数,但顺序相反。
4、混合训练
这是一个非常简单的技巧,也可以称为混合,主要适用于计算机视觉领域的网络。这个技巧的想法取自这篇论文。混合过程有助于避免过度拟合并降低模型在对抗性数据面前的敏感性。我们也可以将此过程视为一种数据增强技术,它对输入样本随机执行混合。继续深入,我们发现这个技巧收集了一对数据样本并生成新样本,同时计算输入和输出的加权平均值。
我们的一篇文章解释了混合过程使用的混合过程。例如,在图像分类任务中,该过程将通过混合输入中的图像和相同的混合参数来计算输出标签的加权平均值。
5、标签平滑
标签平滑是加速神经网络训练过程的通用技术。一个正常的分类数据集由 one-hot 编码的标签组成,其中真正的类具有 1 的值,而其他类具有 0 值。在这种情况下,softmax 函数永远不会输出 one-hot 编码向量。此过程主要在地面实况标签的分布和模型预测之间产生差距。
应用标签平滑可以减少真实标签分布与模型预测之间的差距。在标签平滑中,我们主要从真实标签中减去一些 epsilon,并将减法结果添加到其他标签中。通过执行此操作,模型可以防止过度拟合并作为正则化器工作。这里需要注意的一件事是,如果 epsilon 的值变得非常大,那么标签可能会变得过于扁平。
标签平滑的强值减少了标签信息的保留。标签平滑的效果也可以在神经网络的训练速度上看到,因为该模型从软目标中学习得更快,软目标是硬目标的加权平均值和标签上的均匀分布。该方法可用于各种建模过程,如图像分类、语言翻译和语音识别。
6、迁移学习
迁移学习可以解释为模型通过从其他模型转移权重而不是从头开始训练来开始训练的过程。这是增加模型训练的一种非常好的方法,它还可以帮助提高模型的性能,因为我们在该过程中使用的权重已经在某个地方进行了训练,并且可以减少大量的训练时间整个训练时间。我们的一篇文章解释了如何执行这种类型的学习。
7、混合精度训练
我们可以定义这种类型的训练,使模型同时学习 16 位和 32 位浮点数,这样模型可以更快地学习并减少模型的训练时间。让我们以一个简单的神经网络为例,其中模型需要从图像中检测对象。训练这样的模型意味着找到网络的边缘权重,以便能够从数据中执行目标检测。这些边权重可以以 32 位格式存储。
这种通用训练可能涉及前向和反向传播,因此如果点为 32 位,则需要数十亿次乘法。我们可以避免在训练过程中使用 32 位点来表示一个数字。在网络计算的反向传播梯度中,梯度可能非常低,在这种情况下,我们需要推送大量内存来表示数字。我们也可以膨胀这些梯度,这样我们就不需要大量的内存来表示这些数字。
我们还可以用 16 位来表示数字,可以节省模型的大量内存存储,训练程序可以比以前更快。这个过程可以解释为训练模型,而算术运算只有很少的位。在这种训练中唯一需要考虑的是准确性。发生这种情况是因为模型的准确性明显降低。
如上所述,我们可以使用混合精度训练来训练 16 位和 32 位模型,其中它以原始 32 位精度格式维护实际权重参数的主副本。我们可以将其用作训练后与模型一起使用的一组实际权重。
在训练之间,我们可以将 32 位精度转换为 16 位精度,并且可以使用更少的内存执行所有算术运算的前向传播,并且可以通过将其缩放到梯度的反向传播来计算损失以在一段时间后馈送也被放大了。
在反向传播中,我们计算 16 位梯度,最终梯度进入我们在模型中使用的实际权重集。上面给出的过程是一次迭代,这发生在多次迭代中。下图解释了我们讨论过的整个过程。
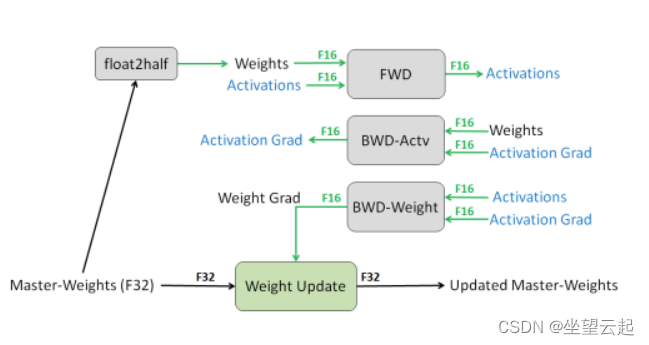
下面的论文描述了主要思想。
https://arxiv.org/pdf/1710.03740.pdf![]() https://arxiv.org/pdf/1710.03740.pdf 下面的链接给出了混合精度训练的示例。
https://arxiv.org/pdf/1710.03740.pdf 下面的链接给出了混合精度训练的示例。
https://www.tensorflow.org/guide/mixed_precision![]() https://www.tensorflow.org/guide/mixed_precision
https://www.tensorflow.org/guide/mixed_precision