1、先验算法概述
Apriori算法由R. Agrawal和R. Srikant在 1994 年给出,用于在数据集中查找关联规则的频繁项集。该算法的名称是 Apriori,因为它使用了频繁项集属性的先验知识。换句话说,我们可以说先验算法是一种关联规则学习,例如分析购买了产品 A 的人也购买了产品B。
我们举一个例子来更好地理解这个概念。比如比萨店的卖家将比萨、软饮料和面包棒组合在一起。他还为购买这些组合的客户提供折扣。你有没有想过他为什么要这样做?他认为购买披萨的顾客也会购买软饮料和面包棒。然而,通过制作组合,他让客户很容易购买并增加了他的销售业绩。
利用其知识,零售商可以为其产品制定交易,例如提供最佳规则折扣或根据客户一起购买的最佳关联规则的数量附加免费商品。无论哪种情况,客户最终都会花费更多来从这些交易中受益。其结果是,该企业提高了销售额,自然获得了高利润。
以上的例子是数据挖掘中关联规则的最佳例子。它有助于我们学习先验算法的概念。
2、先验算法原理
为了构建元素或项目之间的关联规则,该算法考虑了三个重要因素,即支持度、置信度和提升度。这些因素中的每一个都解释如下:
支持度,用来计算A的受欢迎程度。
Support(A) = (A的交易数量)/(交易总量)
置信度,可以计算购买物品 X 时购买物品 Y 的可能性的百分比。
Confidence(A->B) = Support(AUB) / Support(A)
提升度,确定最佳规则之间关联强度的指标。
Lift = Confidence(A->B)/Support(A)*Support(B)

3、一个简单实例
假设您在有4000个客户交易。然后我们计算两种产品的Support、Confidence 和 Lift,比如说 饼干和巧克力,因为客户经常一起购买这两种商品。
在 4000 笔交易中,其中400笔包含饼干,而其中600笔包含巧克力,这600笔交易中包括200笔包含饼干和巧克力的交易。
使用这些数据,我们将找出支持度、置信度和提升度。
支持度(饼干) = (饼干) / (总交易) = 400/4000 = 10%
置信度 = (饼干和巧克力) / (饼干) = 200/400 = 50%,这意味着 50% 的购买饼干的顾客也购买了巧克力。
提升度 = (置信度 (饼干和巧克力)/ (支持度(饼干) = 50/10 = 5
这意味着人们同时购买饼干和巧克力的概率是单独购买饼干的概率的五倍。如果提升度低于 1,则人们不太可能同时购买这两种物品。 值越大,组合一起被购买的几率越大。
4、使用python实现
我们使用超市的销售记录作为数据集,下面是下载地址。
链接:https://pan.baidu.com/s/112Hkf4EQ5igZEj3wcqrWdw
提取码:to95使用如下命令进行算法库安装
pip install apyori导入包
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd导入数据集
Data = pd.read_csv('Market_Basket_Optimisation.csv', header = None)转换为列表
# Intializing the list
transacts = []
# populating a list of transactions
for i in range(0, 7501):
transacts.append([str(Data.values[i,j]) for j in range(0, 20)])训练先验模型
from apyori import apriori
rule = apriori(transactions = transacts, min_support = 0.003, min_confidence = 0.2, min_lift = 3, min_length = 2, max_length = 2)可视化结果
output = list(rule) # returns a non-tabular output
# putting output into a pandas dataframe
def inspect(output):
lhs = [tuple(result[2][0][0])[0] for result in output]
rhs = [tuple(result[2][0][1])[0] for result in output]
support = [result[1] for result in output]
confidence = [result[2][0][2] for result in output]
lift = [result[2][0][3] for result in output]
return list(zip(lhs, rhs, support, confidence, lift))
output_DataFrame = pd.DataFrame(inspect(results), columns = ['Left_Hand_Side', 'Right_Hand_Side', 'Support', 'Confidence', 'Lift'])未排序结果
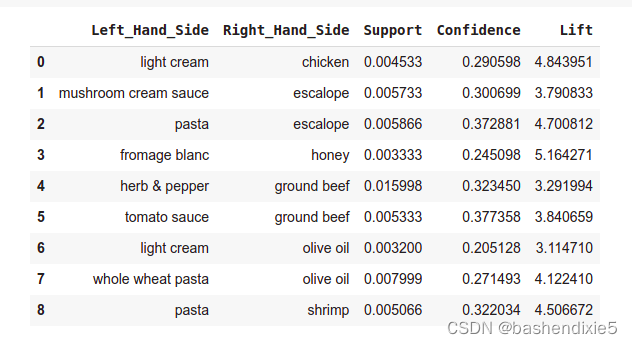
按 Lift 列降序排列的结果
output_DataFrame.nlargest(n = 10, columns = 'Lift')
5、缺点和优点
优点是易于理解、易于在大型数据集上实现
缺点是需要扫描整个数据集,对计算能力要求高,如果是大型数据集,计算会十分耗时。
6、提高先验效率的方法
许多方法可用于提高算法的效率。
1、基于哈希的技术:此方法使用称为哈希表的基于哈希的结构来生成 k 项集及其相应的计数。它使用哈希函数来生成表。
2、事务减少:这种方法减少了迭代中的事务扫描次数。不包含频繁项的事务被标记或删除。
3、分区:这种方法只需要两次数据库扫描来挖掘频繁项集。它说,对于任何可能在数据库中频繁出现的项集,它应该在数据库的至少一个分区中频繁出现。
4、抽样:该方法从数据库 D 中随机抽取一个样本 S,然后在 S 中搜索频繁项集。可能会丢失全局频繁项集。这可以通过降低 min_sup 来减少。
5、动态项集计数:这种技术可以在扫描数据库期间在数据库的任何标记的起点添加新的候选项集。
7、相关参考
一种改进的关联规则先验算法
https://arxiv.org/pdf/1403.3948.pdf![]() https://arxiv.org/pdf/1403.3948.pdf
https://arxiv.org/pdf/1403.3948.pdf