前几天在Github上看到一个用SN-GAN技术生成punk的项目,项目地址:https://github.com/teddykoker/cryptopunks-gan,跑了一遍感觉很有趣,所以就研究了一下生成对抗网络(GAN)的相关内容,详见下文:
一、GAN原理介绍
想要了解GAN,推荐首先阅读IanGoodfellow写的paper:“Generative Adversarial Networks”(PDF:https://arxiv.org/pdf/1406.2661.pdf),这篇paper算是这个领域的开山之作。
接下来以图片(NFT常见的表现形式)为例,解释一下GAN的基本原理。假设我们有两个网络,G(Generator)和D(Discriminator)。正如它的名字所暗示的那样,它们的功能分别是:
G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记作G(z)。
D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
最后博弈的结果是什么?在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
这样我们的目的就达成了:我们得到了一个生成式的模型G,它可以用来生成图片。
以上只是大致说了一下GAN的核心原理,如何用数学语言描述呢?这里直接摘录论文里的公式:
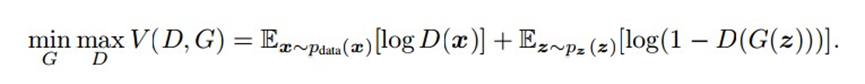
简单分析一下这个公式:
整个式子由两项构成。x表示真实图片,z表示输入G网络的噪声,而G(z)表示G网络生成的图片。
D(x)表示D网络判断真实图片是否真实的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。而D(G(z))是D网络判断G生成的图片的是否真实的概率。
G的目的:上面提到过,D(G(z))是D网络判断G生成的图片是否真实的概率,G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此我们看到式子的最前面的记号是min_G。
D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大(max_D)。
那么如何用随机梯度下降法训练D和G?论文中也给出了算法:

可以看到绿色框中是两步计算的具体算法,红色框内是两步的不同之处。第一步我们训练D,D是希望V(G, D)越大越好,所以是加上梯度(ascending)。第二步训练G时,V(G, D)越小越好,所以是减去梯度(descending)。整个训练过程交替进行。
二、 GAN的改进DCGAN原理介绍
深度学习中对图像处理应用最好的模型是CNN,那么将GAN和CNN结合最好的尝试就是DCGAN。
DCGAN的原理和GAN是一样的,这里就不在赘述。它只是把上述的G和D换成了两个卷积神经网络(CNN)。但不是直接换就可以了,DCGAN对卷积神经网络的结构做了一些改变,以提高样本的质量和收敛的速度,这些改变有:
取消所有pooling层。G网络中使用转置卷积(transposed convolutional layer)进行上采样,D网络中用加入stride的卷积代替pooling。
在D和G中均使用batchnormalization
去掉FC层,使网络变为全卷积网络
G网络中使用ReLU作为激活函数,最后一层使用tanh
D网络中使用LeakyReLU作为激活函数
DCGAN中的G网络示意:

三、 DCGAN实践
这一节咱们就用DCGAN做一个自动生成动漫人物头像的实践:
首先要获取用于数据训练的原始图片,之前punk的例子用的1817个punk的图片并存储于cryptopunks-gan/data/,这里咱们再用另一个例子:https://github.com/carpedm20/DCGAN-tensorflow。直接使用它的源码,在data文件夹中再新建一个anime文件夹,把图片直接放到这个文件夹里,运行时指定–datasetanime即可。这里的原数据使用从https://konachan.net/ 上爬取的动漫图片,截取头像后如下图所示:

之后运行程序进行训练:
以下分别是跑完第1、10、200个epoch的结果:



四、 conditional GAN
上面的程序可以生成无数随机组合的图片,但那只是完全的随机生成,你无法控制生成出的人物的属性。而使用conditional GAN,我们可以指定生成人物的属性,如发色、眼睛的颜色、发型,甚至是服装、装饰物,从而生成具有指定属性的图像。基本原理可以详见论文:https://arxiv.org/abs/1605.05396。
我们的目标实际上是通过“文字”生成“图像”。为此我们需要解决以下两个问题:
如何把文字描述表示成合适的向量。
如何利用这个描述向量生成合适的图片。
为达成以上目的,论文作者分别对D和G做了改进,即GAN-CLS和GAN-INT,这里就不展开将技术细节了,可以在论文里看详细的推导过程。
对于深度学习,样本数量越多,效果就会越好,所以这里的GAN-INT是对效果的提升有帮助的,实验中验证了这一点。
作者把上面的两种改进合在一起,就成了GAN-INT-CLS,也是这篇文章的最终方法。
放一张论文作者实验的图,他是做了花的生成,最上面一行是Ground Truth,下面依次是GAN,GAN-CLS,GAN-INT,GAN-INT-CLS:

五、 conditional GAN 实践
大家可以试一下这个使用了CGAN的网站:https://hiroshiba.github.io/girl_friend_factory/index.html
点击上方的“無限ガチャ”,开始生成,选择属性,先生成金发+碧眼(左),再生成黑发+碧眼(右),多次点击生成按钮可以生成多个:


网站还有很多功能,大家可以自己探索。
六、 进一步升级的实践
前面咱们举的例子输出的图片都不是特别真实,这里的要讲的实践做的更加完善,直接上
网站:https://make.girls.moe/#/
Github:https://github.com/makegirlsmoe
论文:https://makegirlsmoe.github.io/assets/pdf/technical_report.pdf
下图左侧为通过属性blonde hair, twin tails, blush, smile, ribbon, red eyes生成的人物,右侧是通过属性silver hair, long hair,blush, smile, open mouth, blue eyes生成的人物,都表现得非常自然,完全看不出是机器自动生成的:

进入网站:

点击生成:

这里会随机生成一个图片,我们选择属性,比如粉色长发,蓝眼睛:

其他属性也可以自行实践,这里就不多演示,最后你所有生成的图片会在历史中保存:

这里再谈一下支撑以上网站的论文中对GAN的改进之处:
改进一:更高质量的图像库之前使用的训练数据集大多数是使用爬虫从Danbooru或Safebooru这类网站爬下来的,这类网站的图片大多由用户自行上传,因此质量、画风参差不齐,同时还有不同的背景。这篇文章的数据来源于getchu,这本身是一个游戏网站,但是在网站上有大量的人物立绘,图像质量高,基本出于专业画师之手,同时背景统一。
除了图像外,为了训练cGAN,还需要图像的属性,如头发颜色、眼睛的颜色等。作者使用Illustration2Vec,一个预训练的CNN模型来产生这些标签。
改进二:GAN结构此外,作者采取了和原始的GAN不同的结构和训练方法。总的训练框架来自于DRAGAN(arxiv:https://arxiv.org/pdf/1705.07215.pdf),经过实验发现这种训练方法收敛更快并且能产生更稳定的结果。生成器G的结构类似于SRResNet(arxiv:https://arxiv.org/pdf/1609.04802.pdf):

判别器也要做一点改动,因为人物的属性相当于是一种多分类问题,所以要把最后的Softmax改成多个Sigmoid:

七、 总结
这里总结一下主要的资源:
生成punk Github:https://github.com/teddykoker/cryptopunks-gan
《深度学习框架PyTorch:入门与实践》没来得及整理这部分,很好的学习资源,讲解跟明确:Github:https://github.com/chenyuntc/pytorch-book
DCGAN测试源码:https://github.com/carpedm20/DCGAN-tensorflow
makegirls网站:https://make.girls.moe/#/
Girlfriend网站:https://hiroshiba.github.io/girl_friend_factory/index.html
这类技术可以在一定程度上代替插画师类的职业了,或者NFT的创作也可以用此来做某项目的plus(原理上只要有训练图库,就可以自动生成新的NFT)。更多使用方案还需要继续探索。