目录
前言
我们将/etc/passwd文件拷贝到/data下做实验,以免影响系统
一、awk特点和应用场景
- 一门语言,类似于c语言
- 过滤、统计、计算
- 过滤统计日志
- 三个作者的名字缩写组成
二、awk执行
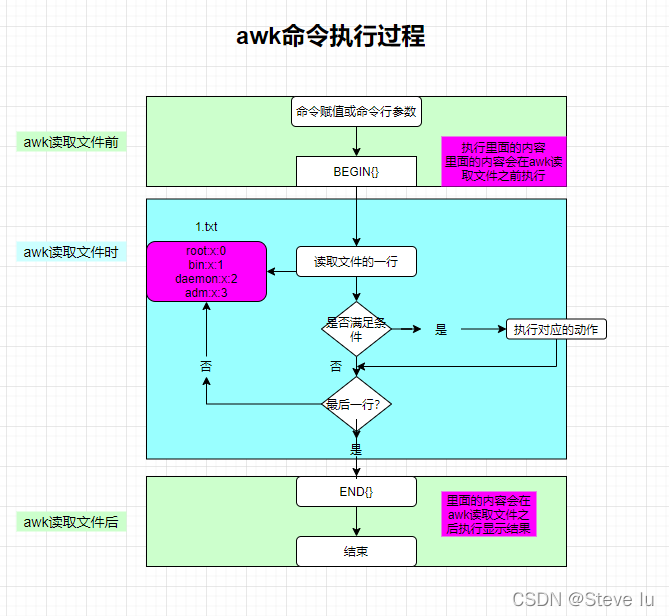
2.1 工作原理
- 逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令;
- sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个“字段”再进行处理;
- awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示;
- 在使用awk命令的过程中,可以使用逻辑操作符“&&”表示与、“||”表示或、“!”表示非,还可以进行简单的数学运算如+-*/%^,分别表示加减乘除取余和乘方
2.2 命令格式
awk 选项 '模式或条件{操作}' 文件1 文件2
awk -f 脚本文件 文件1 文件2 ...2.3 行与列
| 名词 | awk中的叫法 | 一些说明 |
| 行 | 记录record | 每一行默认通过回车分割的 |
| 列 | 字段,域 field | 每一列默认通过空格分割的 |
awk中默认的东西都是可以修改的
2.3.1 取行
| awk | |
| NR==1 | 取出某一行 |
| NR>=1&&NR<=5 | 取出1-5行范围 |
| $0 | 整行 |
| /old/ | 过滤 |
| /100/,/110/ | 100到110行 |
| 符号 | <> >= <= == != |
#取第一行
[root@localhost data]# awk 'NR==1' users.txt
1,zhangsan
#取1-3行,空格可加可不加
[root@localhost data]# awk 'NR>=1 && NR<=3' users.txt
1,zhangsan
2,lisi
3,wangwu
#非文本内容取行
[root@localhost data]# ll |awk 'NR==2'
-rw-r--r--. 1 root root 172 4月 12 09:45 1.tar.gz
[root@localhost data]# ll |awk 'NR==2{print $0}'
-rw-r--r--. 1 root root 172 4月 12 09:45 1.tar.gz


2.3.2 取列
- -F 指定分隔符, 指定每一列结束标记(默认是空格,连续的空格,tab键)
- $数字 取出某一列;注意:在awk中$内容就一个意思,表示取出某一列
- column -t 文本对齐
- $NF 表示最后一列
#取出ls -l 文件大小的那一列
[root@localhost data]# ll
总用量 44
-rw-r--r--. 1 root root 172 4月 12 09:45 1.tar.gz
-rw-r--r--. 1 root root 96 4月 20 15:16 config
-rw-r--r--. 1 root root 48 4月 12 09:45 host_ip
-rw-r--r--. 1 root root 70 4月 12 09:45 ip.txt
-rw-r--r--. 1 root root 81 4月 21 00:58 out1.txt
-rw-r--r--. 1 root root 79 4月 21 00:58 out2.txt
-rw-r--r--. 1 root root 2169 4月 19 14:59 passwd
-rw-r--r--. 1 root root 78 4月 21 00:53 script.sed
drwxr-xr-x. 8 root root 4096 4月 16 15:42 sh
drwxr-xr-x. 2 root root 240 4月 12 09:45 test
-rw-r--r--. 1 root root 54 4月 20 14:44 users.txt
-rw-r--r--. 1 root root 69 4月 15 12:38 丢包.txt
[root@localhost data]# ll |awk '{print $5}'
172
96
48
70
81
79
2169
78
4096
240
54
69
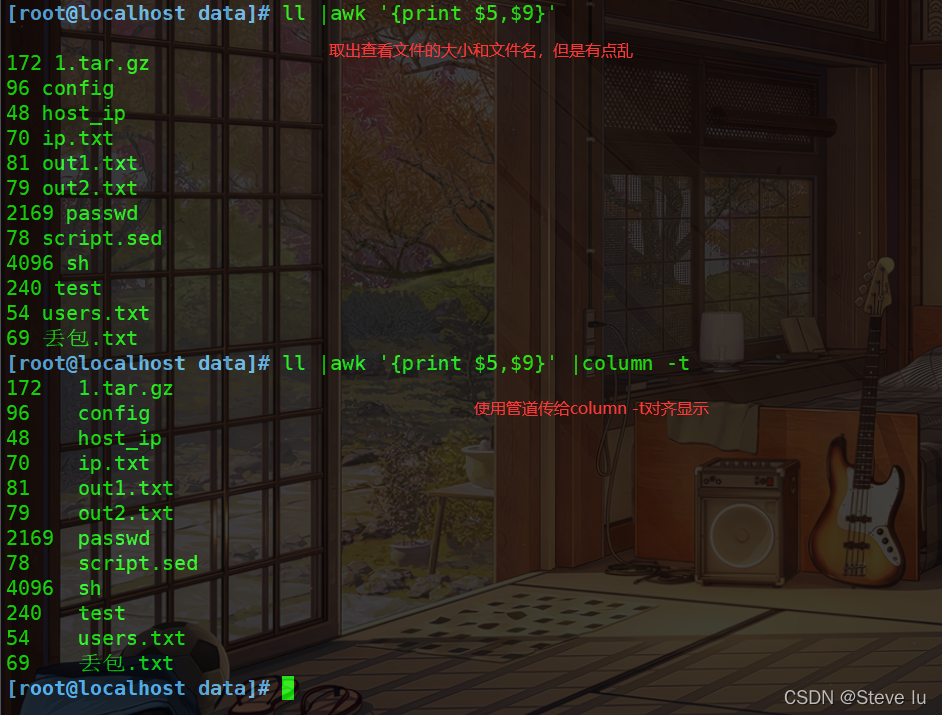
#查看大小和文件名,并对齐显示
[root@localhost data]# ll |awk '{print $5,$9}'
172 1.tar.gz
96 config
48 host_ip
70 ip.txt
81 out1.txt
79 out2.txt
2169 passwd
78 script.sed
4096 sh
240 test
54 users.txt
69 丢包.txt
[root@localhost data]# ll |awk '{print $5,$9}' |column -t
172 1.tar.gz
96 config
48 host_ip
70 ip.txt
81 out1.txt
79 out2.txt
2169 passwd
78 script.sed
4096 sh
240 test
54 users.txt
69 丢包.txt
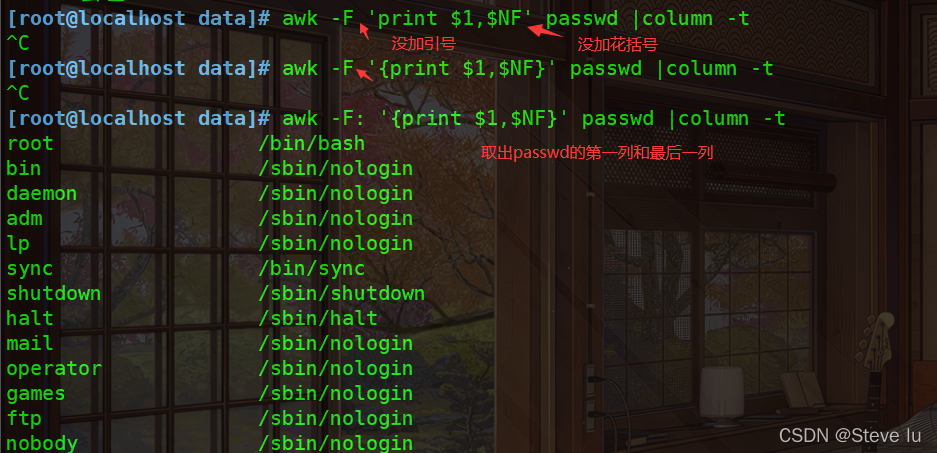
#取出passwd的第一列和最后一列
[root@localhost data]# awk -F: '{print $1,$NF}' passwd |column -t
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
operator /sbin/nologin
games /sbin/nologin
#将passwd的第一列和最后一列交换
[root@localhost data]# awk -F: -vOFS=: '{print $NF,$2,$3,$4,$5,$1}' passwd
/bin/bash:x:0:0:root:root
/sbin/nologin:x:1:1:bin:bin
/sbin/nologin:x:2:2:daemon:daemon
/sbin/nologin:x:3:4:adm:adm
/sbin/nologin:x:4:7:lp:lp
/bin/sync:x:5:0:sync:sync
/sbin/shutdown:x:6:0:shutdown:shutdown
/sbin/halt:x:7:0:halt:halt
/sbin/nologin:x:8:12:mail:mail
/sbin/nologin:x:11:0:operator:operator
/sbin/nologin:x:12:100:games:games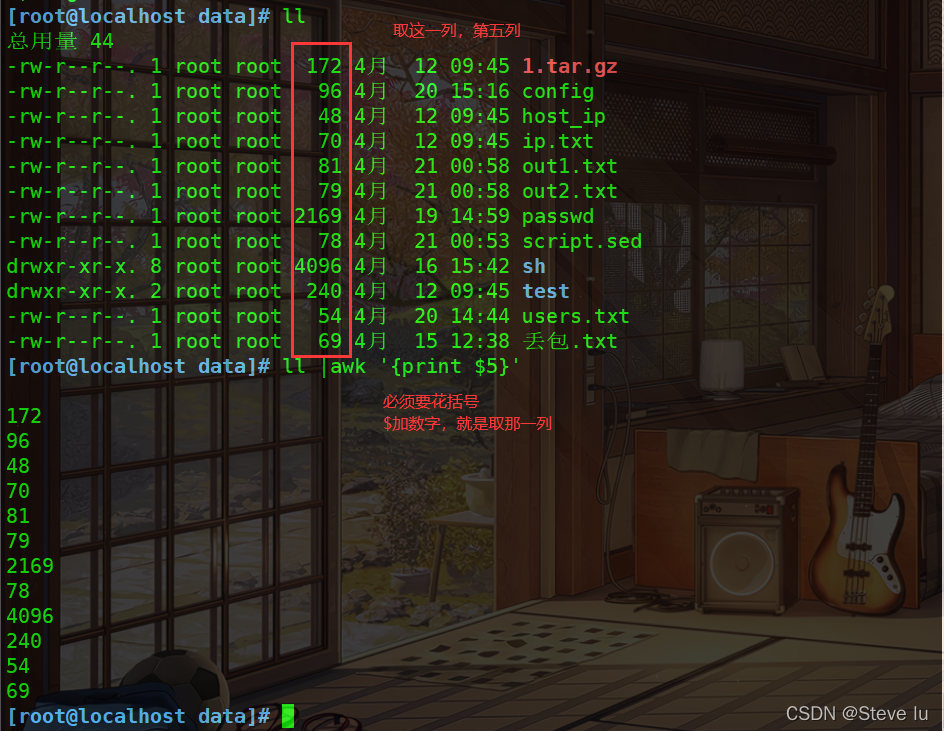


说错了,是第一列和最后一列交换,只需$1和$NF
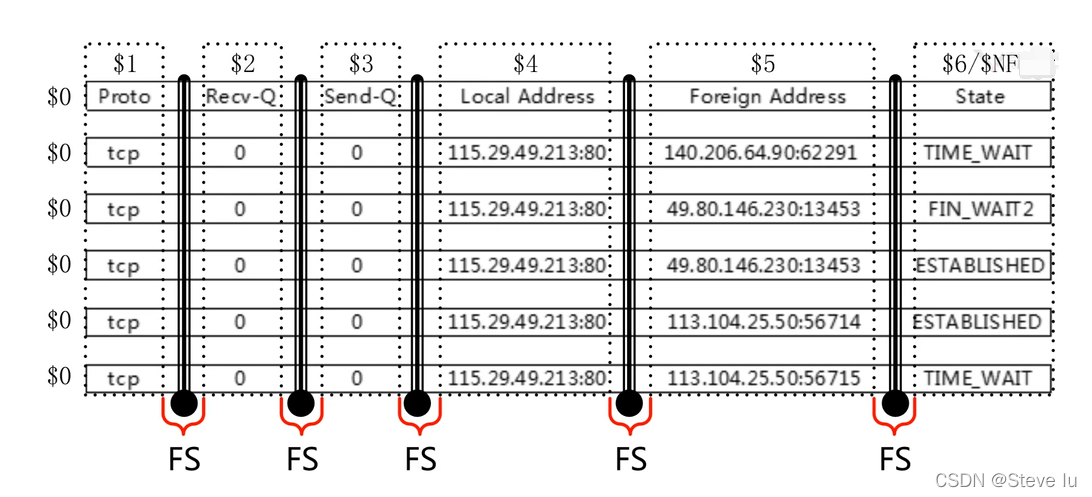
2.3.3 小结
- 行与列名称
- awk取行与取列
- 取出网卡IP地址(同时取行取列)
#取出IP地址
[root@localhost data]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.109.131 netmask 255.255.255.0 broadcast 192.168.109.255
inet6 fe80::45b4:7459:c87e:dc54 prefixlen 64 scopeid 0x20<link>
[root@localhost data]# ifconfig |awk 'NR==2' |awk -F"[ ]+" '{print $3}'
192.168.109.131
[root@localhost data]# ifconfig |awk -F"[ ]+" 'NR==2{print $3}'
192.168.109.131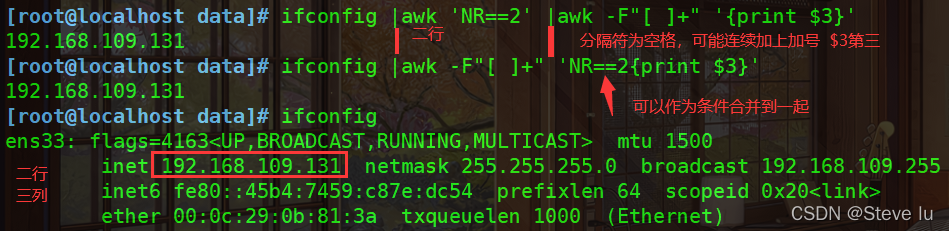
2.4 awk常见的内建变量(可直接使用)
| FS | 列分隔符,指定每行文本的字段分隔符,默认为空格或制表符,与-F作用相同 |
| OFS | 删除字段分隔符(awk显示每一列的时候,每一列之间通过什么分割,默认空格) |
| NF | 当前处理的行的字段的个数 |
| NR | 当前处理的行的行号(序数) |
| $0 | 当前处理的行的整行内容 |
| $n | 当前处理行的第n个字段(第n列) |
| FILENAME | 被处理的文件名 |
| RS | 行分隔符,预设值是'\n' |
[root@localhost data]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
[root@localhost data]# RS=':'
#原本$PATH都在一行上,将RS默认行分隔符\n改为冒号后,就把这一行内容看成五行内容2.5 awk模式匹配
| 命令 | 选项 | 条件{动作} |
| awk | -F"[ ]+" | 'NR==2{print $3}' |
- 比较符号:>< >= <= == !=
- 正则
- 范围表达式
- 特殊条件:BEGIN和END
2.5.1 比较表达式-参考取行部分
2.5.2 正则
- //支持扩展正则
- 可以精确到某一列中是否包含该内容(sed和grep比较难实现)
- ~包含
- !~不包含
| 正则 | awk正则 |
| ^表示以……开头的行 | 某一列的开头 $3~/^root/ |
| $表示以……结尾的行 | 某一列的结尾 $3~/root$/ |
| ^$表示空行 | 某一列是空的,很少用 |
#第三列以2开头的行
[root@localhost data]# awk -F: '$3 ~/^2/' passwd
daemon:x:2:2:daemon:/sbin:/sbin/nologin
rpcuser:x:29:29:RPC Service User:/var/lib/nfs:/sbin/nologin
2.5.3 表示范围
- /哪里开始/,/哪里结束/ 常用
- NR==1,NR==5 从第一行开始到第五行结束 类似于sed -n '1,5p'
#显示指定时间(11:02:00到11:02:30)范围内容的IP地址
awk '/11:02:00/,/11:02:30/{print $1}' access.log2.5.4 特殊模式BEGIN{}和END{}
| 模式 | 含义 | 应用场景 |
| BEGIN{} | 里面的内容会在awk读取文件之前执行 | 1.统计、计算、不涉及读取文件 2.用来处理文件之前,添加个表头 3.定义awk变量(也可以用-v) |
| END{} | 里面的内容会在awk读取文件之后执行 | 1.awk进行统计,一般过程:先进行计算,最后END里面输出结果 2.awk使用数组,用来输出数组结果 |
- 常见统计方法:
| 统计方法 | 简写 | 应用场景 |
| i=i+1 | i++ | 计数 |
| sum=sum+??? | sum+=??? | 求和累加 |
| array[]=array[]+1 | array[]++ | 数组分类计数 |
#统计空行
[root@localhost data]# cat test1
[root@localhost data]# awk '/^$/{i++}END{print i}' test1
10
[root@localhost data]# cat test1 |wc -l
10
#求1加到100的和
[root@localhost data]# seq 100 |awk '{sum=sum+$1}END{print sum}'
5050
[root@localhost data]#
###如果想看过程
seq 100 |awk '{sum=sum+$1;print sum}END{print sum}'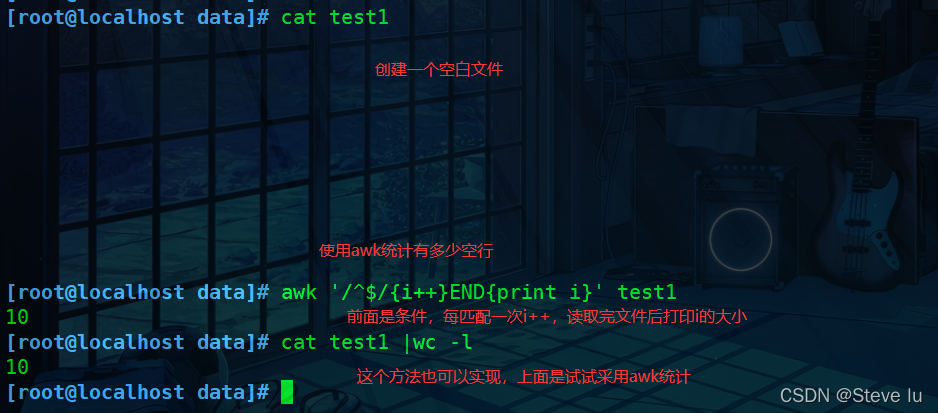

2.6 awk数组
- 统计日志:统计每个IP出现次数;统计每种状态码出现次数;统计系统中每个用户被攻击的次数;统计攻击者IP出现次数;
- 累加求和:统计每个IP消耗的流量;
| shell数组 | awk数组 | |
| 形式 | array[0]=0 array[1]=1 | array[0]=0 array[1]=1 |
| 使用 | echo ${array[0]} ${array[1]} | print array[0] array[1] |
| 批量输出数组内容 | for i in ${array[*]} do echo $i done |
for(i in array) print array[i] |
awk字母会被识别为变量,如果只是想使用字符串需要使用双引号引起来
#awk数组案例
[root@localhost data]# awk 'BEGIN{a[0]=123456;a[1]="stevelu";print a[0],a[1]}'
123456 stevelu
[root@localhost data]#
[root@localhost data]# awk 'BEGIN{a[0]=123456;a[1]="stevelu";for(i in a)print
123456
stevelu
[root@localhost data]# awk 'BEGIN{a[0]=123456;a[1]="stevelu";for(i in a)print i,a[i]}'
0 123456
1 stevelu

- 案例
[root@localhost data]# cat test1
htttp://www.stevelu.org/index.html
htttp://www.stevelu.org/1.html
htttp://www.stevelu.org/2.html
htttp://post.stevelu.org/index.html
htttp://post.stevelu.org/1.html
htttp://mp3.stevelu.org/index.html
#取域名
[root@localhost data]# awk -F"[/.]+" '{print $2}' test1
www
www
www
post
post
mp3
#统计各个域名出现的次数
[root@localhost data]# awk -F"[/.]+" '{a[$2]++}END{for(i in a)print i,a[i]}' test1
www 3
mp3 1
post 2
#逆序排列
[root@localhost data]# awk -F"[/.]+" '{a[$2]++}END{for(i in a)print i,a[i]}' test1|sort -rnk2
www 3
post 2
mp3 1
[root@localhost data]# 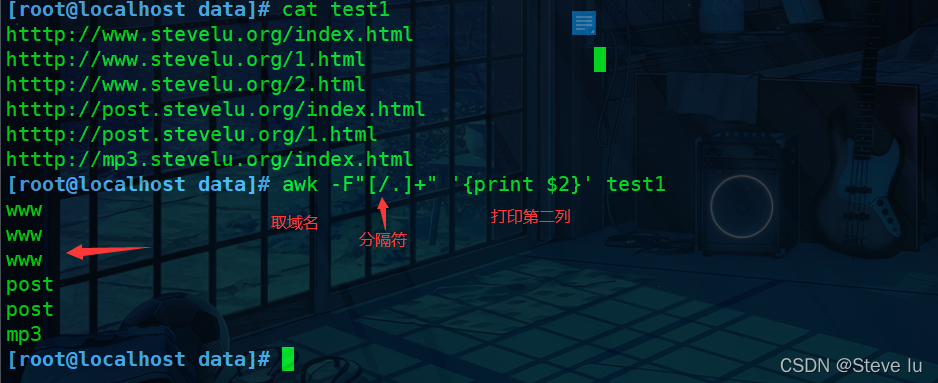


2.7 for循环
| shell编程c语言for循环 | awk for循环 | |
| for ((i=1;i<=10;i++)) do echo $i done |
for (i=1;i<=10;i++) print i |
awk for 循环用来循环每个字段 |
#100以内的求和(众多的方法之一)
[root@localhost data]# awk 'BEGIN{for(i=1;i<=100;i++)sum+=i;print sum}'
5050
[root@localhost data]# awk 'BEGIN{
for(i=1;i<=100;i++)
#do
sum+=i; #循环的主体
print sum #循环的结果
#done
}'
2.8 if判断
| shell if 判断 | awk if判断 | |
| if [ i -eq 0];then echo " " fi |
if(条件) print " " |
常用 |
| if [ i -eq 0];then echo " " esle echo " " fi |
if(条件) print " " else print " " |
#显示磁盘空间不足
[root@localhost data]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root 10G 4.9G 5.2G 49% /
devtmpfs 897M 0 897M 0% /dev
tmpfs 912M 0 912M 0% /dev/shm
tmpfs 912M 26M 887M 3% /run
tmpfs 912M 0 912M 0% /sys/fs/cgroup
/dev/sda1 1014M 179M 836M 18% /boot
tmpfs 183M 32K 183M 1% /run/user/0
/dev/sr0 4.3G 4.3G 0 100% /mnt
[root@localhost data]# df -h|awk -F"[ %]+" 'NR>1{if($5>70)print "disk not enou
disk not enough /dev/sr0
注意:awk使用多个条件的时候 第一个条件可以放在 '条件{动作}' 第二个条件 一般使用if判断