1 背景介绍
在这个端午节,利用Python爬取京东上的“粽子”数据,进行可视化分析。
通过这个case可以锻炼自己的数据爬取,数据清洗,以及数据可视化的能力。
2 爬虫过程
- 爬取网页:https://www.jd.com/
- 爬取过程:在搜索框输入“粽子”, 获取页面,并找到翻页的规律
- 页面解析:对页面的数据进行解析
- 爬取字段:分别有粽子的名称、价格、店铺等。
具体代码见下(可获取深层的信息):
import pandas as pd
import requests
from lxml import etree
import chardet
import time
import re
def get_CI(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; X64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'}
rqg = requests.get(url,headers=headers)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 价格
p_price = html.xpath('//div/div[@class="p-price"]/strong/i/text()')
# 名称
p_name = html.xpath('//div/div[@class="p-name p-name-type-2"]/a/em')
p_name = [str(p_name[i].xpath('string(.)')) for i in range(len(p_name))]
# 深层url
deep_ur1 = html.xpath('//div/div[@class="p-name p-name-type-2"]/a/@href')
deep_url = ["http:" + i for i in deep_ur1]
brands_list = []
kinds_list = []
for i in deep_url:
rqg = requests.get(i,headers=headers)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 品牌
brands = html.xpath('//div/div[@class="ETab"]//ul[@id="parameter-brand"]/li/@title')
brands_list.append(brands)
# 类别
kinds = re.findall('>类别:(.*?)</li>',rqg.text)
kinds_list.append(kinds)
data = pd.DataFrame({
'名称':p_name,'价格':p_price,'品牌':brands_list,'类别':kinds_list})
return(data)
# 该url可通过京东搜索获取
x = "https://search.jd.com/Search?keyword=%E7%B2%BD%E5%AD%90&qrst=1&wq=%E7%B2%BD%E5%AD%90&stock=1&page="
url_list = [x + str(i) for i in range(1,2,1)]
# 找到翻页的规律
res = pd.DataFrame(columns=['名称','价格','品牌','类别'])
for url in url_list:
res0 = get_CI(url)
res = pd.concat([res,res0])
time.sleep(3)
res.to_csv('aliang_2.csv',encoding='utf_8_sig')
3 数据清洗
先用pandas库,来读取数据,并对数据进行处理。见下:
import pandas as pd
df = pd.read_excel("粽子.xlsx",index_col=False)
df.head()

对“品牌”、“类别”的数据去掉中括号,见下:
df["品牌"] = df["品牌"].apply(lambda x: x[1:-1])
df["类别"] = df["类别"].apply(lambda x: x[1:-1])
df.head()

4 统计分析
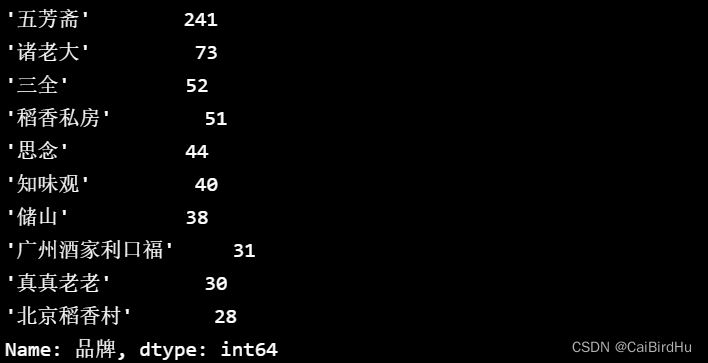
4.1 粽子品牌排名前10的店铺
df["品牌"].value_counts()[:10]
4.2 粽子口味排名前5的味道
def func1(x):
if x.find("甜") > 0:
return "甜粽子"
else:
return x
df["类别"] = df["类别"].apply(func1)
df["类别"].value_counts()[1:6]

4.3 粽子售卖价格区间划分
def price_range(x): #按照淘宝推荐划分价格区间
if x <= 50:
return '<50元'
elif x <= 100:
return '50-100元'
elif x <= 300:
return '100-300元'
elif x <= 500:
return '300-500元'
elif x <= 1000:
return '500-1000元'
else:
return '>1000元'
df["价格区间"] = df["价格"].apply(price_range)
df["价格区间"].value_counts()

更多的字段内容可自行爬虫获取并分析。
4 数据可视化
通过数据可视化分析,可以将数据所包含的信息,更加完美滴呈现出来。
4.1 粽子商品名称词云图
import jieba
df["名称切分"] = df["名称"].apply(jieba.lcut)
with open("stop_words.txt",encoding="utf-8") as f:
stop = f.read()
stop = stop.split()
stop = ["粽"] + stop
df["名称切分"] = df["名称切分"].apply(lambda x:[i for i in x if i not in stop])
all_words = []
for i in df["名称切分"]:
for j in i:
all_words.extend(i)
word_count = pd.Series(all_words).value_counts()
word_count[:10]

from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
# 词云图
word1 = WordCloud(init_opts=opts.InitOpts(width='750px', height='350px'))
word1.add("", [*zip(w.index.tolist(), w.values.tolist())],
word_size_range=[20, 200],
shape=SymbolType.DIAMOND)
word1.set_global_opts(title_opts=opts.TitleOpts('粽子商品名称词云图'))
#word1.render("月饼商品名称词云图.html")
word1.render_notebook()

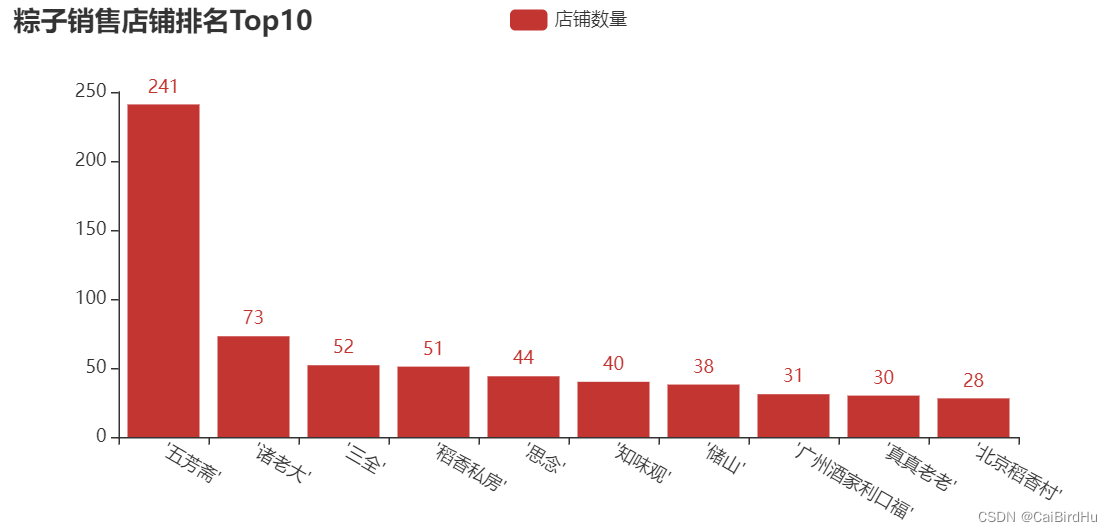
4.2 粽子销售店铺Top10柱形图
# 导入包
from pyecharts.charts import Bar
from pyecharts import options as opts
x = df["品牌"].value_counts()[:10]
# 绘制柱形图
bar1 = Bar(init_opts=opts.InitOpts(width='750px', height='350px'))
bar1.add_xaxis(x.index.tolist())
bar1.add_yaxis('店铺数量', x.values.tolist())
bar1.set_global_opts(title_opts=opts.TitleOpts(title='粽子销售店铺排名Top10'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)))
bar1.render_notebook()
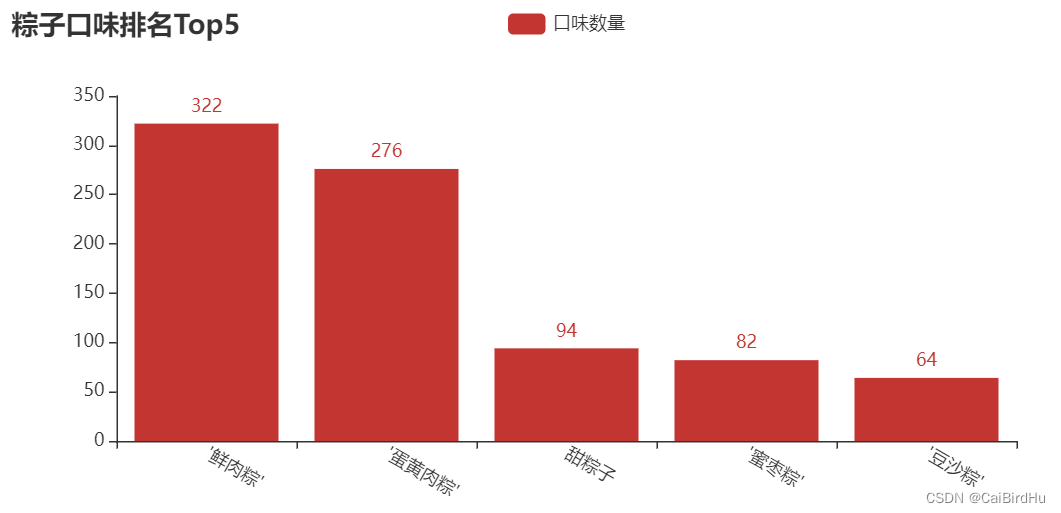
4.3 粽子口味排名Top5
# 导入包
from pyecharts.charts import Bar
from pyecharts import options as opts
y = df["类别"].value_counts()[1:6]
# 绘制柱形图
bar2 = Bar(init_opts=opts.InitOpts(width='750px', height='350px'))
bar2.add_xaxis(y.index.tolist())
bar2.add_yaxis('口味数量', y.values.tolist())
bar2.set_global_opts(title_opts=opts.TitleOpts(title='粽子口味排名Top5'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)))
bar2.render_notebook()
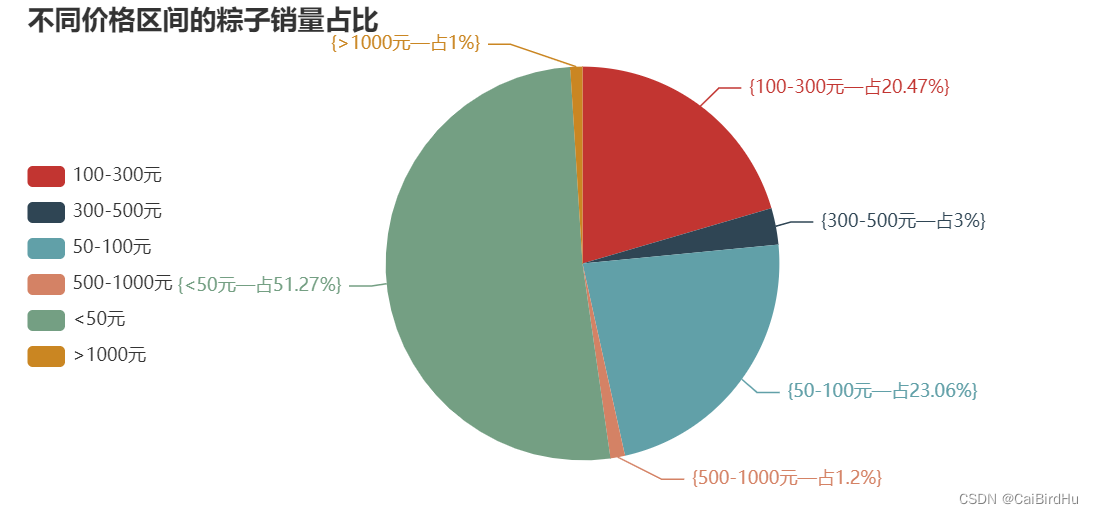
4.4 不同价格区间的粽子销量占比
from pyecharts.charts import Pie
z = df.groupby('价格区间')['品牌'].count()
data_pair = [list(z) for z in zip(z.index.tolist(), z.values.tolist())] # 这里面必须是列表
# 饼图
pie1 = Pie(init_opts=opts.InitOpts(width='750px', height='350px'))
# 内置富文本
pie1.add(
series_name="销量",
#radius=["35%", "55%"],
data_pair=data_pair,
label_opts=opts.LabelOpts(formatter='{
{b}—占{d}%}')
)
pie1.set_global_opts(legend_opts=opts.LegendOpts(pos_left="left", pos_top='30%', orient="vertical"),
title_opts=opts.TitleOpts(title='不同价格区间的粽子销量占比'))
#pie1.render("不同价格区间的月饼销量占比.html")
pie1.render_notebook()