目录
1.线程概念
-
1.1进程和线程的关系
- 这里借用《程序员的自我修养》中的一段话来说明Linux的多线程
Windows对进程和线程的实现如同教科书一般标准, Windows 内核有明确的线程和进程的概念。在Windows API中,可以使用明确的API: CreateProcess 和CreateThread来创建进程和线程,并且有一系列的 API来操纵它们。但对于Linux来说,线程并不是一个通用的概念。
Linux对多线程的支持颇为贫乏,事实上,在Linux内核中并不存在真正意义上的线程的概念。Linux 将所有的执行实体(无论是线程还是进程)都称为任务(Task), 每一个任务概念上都类似于一个单线程的进程,具有内存空间、执行实体、文件资源等。不过,Linux下不同的任务之间可以选择共享内存空间,因而在实际意义上,共享了同一个内存空间的多个任务构成了一个进程,这些任务也就成了这个进程里的线程。
- 结论1 :线程是依附于进程才能存在的,如果没有 进程,则线程不会单独存在
- 结论2 :多线程的是为了提高整个程序的运行效率的
- 线程也被称之为执行流,因为在执行用户写的代码(程序员创建的线程被称之为“工作线程”)
-
1.2pid本质上是轻量级进程id,换句话说,就是线程ID
- 在task_ struct当中
- pid_ t pid; //轻量级进程id, 也被称之为线程id
- 不同的线程拥有不同的pid
- pid_ t tgid; //轻量级进程组id, 也被称之为进程id
- 一个进程当中的线程拥有相同的tgid
- 为什么进程概念的时候,说pid就是进程 id?
- 线程因为主线程的pid和tgid相等,而我们当时进程中只有一个主线程。所以我们的pid就等于tgid。所以将pid成为进程id也就是现在的tgid。
- 在task_ struct当中
-
1.3 linux内核是如何创建一个线程的呢?
- 其本质就是再在当前进程组中创建一个task_struct结构体,它拥有着和主线程不同的pid,指向同一块虚拟进程地址空间。

- 其本质就是再在当前进程组中创建一个task_struct结构体,它拥有着和主线程不同的pid,指向同一块虚拟进程地址空间。
-
1.4线程的共享与独有
- 在进程虚拟地址空间的共享区当中,调用栈,寄存器, 线程ID, errno, 信号屏蔽字, 调度优先级独有
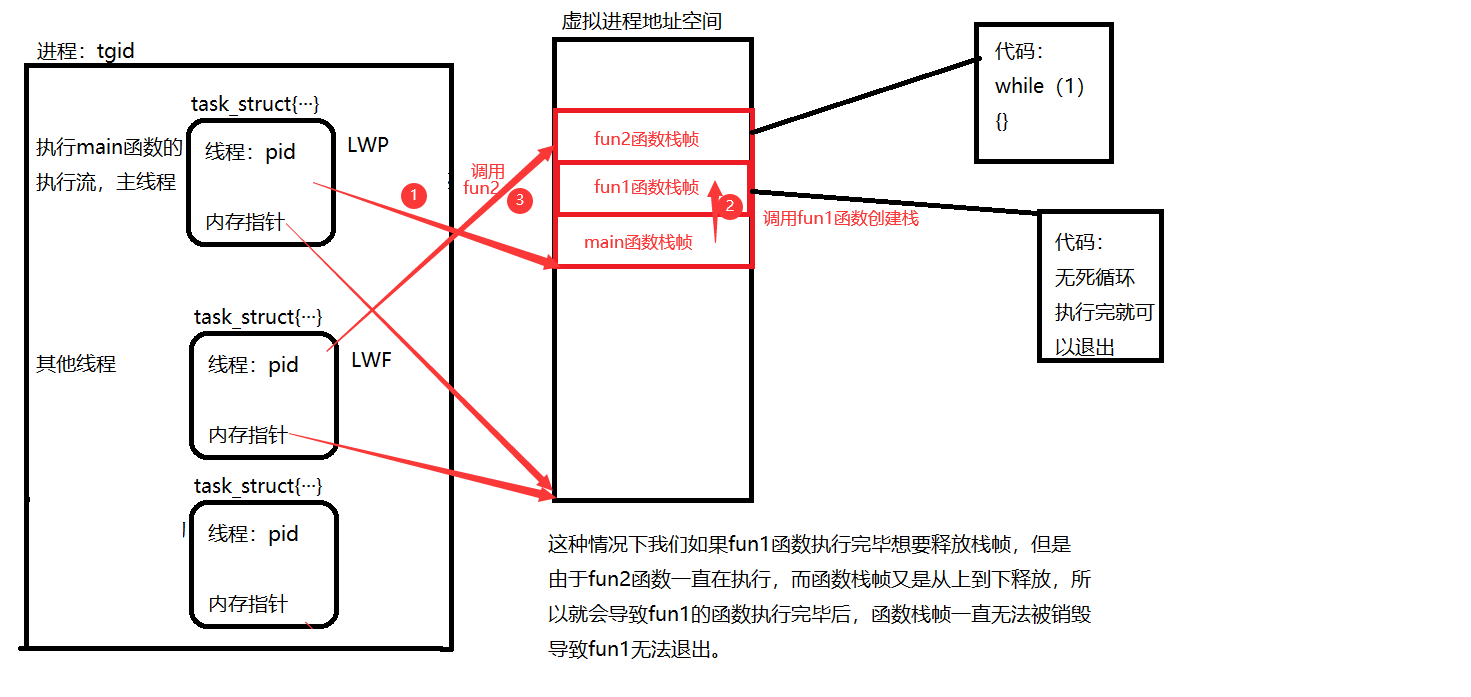
- 1.寄存器:当操作系统调度进程的时候一定是以task struct结构体调度而task struc结构体是以双向列表存储,而操作系统调度时是从就绪队列中调度已经就绪的进程,在这里也就是轻量级进程-线程,当调度时一定会有其他线程被切出,而它切出时寄存器中存储的就是当前要执行的指令,所以要用结构体中上下文信息保存。
- 2.线程id:这毋庸置疑,因为每个线程就是一个轻量级进程,所以它有自己的pid
- 3.errno:当线程在执行出错时会返回一个errno,这个errno属于当前自己的线程错误。
- 4.信号屏蔽字:阻塞位图
- 5.调度优先级:每个进程在执行时被调度的优先顺序。
- 共享:
- 文件描述符表,用户id, 用户组id, 信号处理方式(操作系统定义的信号处理方式), 当前进程的工作目录
- 在进程虚拟地址空间的共享区当中,调用栈,寄存器, 线程ID, errno, 信号屏蔽字, 调度优先级独有
-
1.5线程的优缺点:(重中之重)
- 1.优点:
- 1.多线程的程序,拥有多个执行流,合理使用(要保证结果运行结构正确,例如多个进程并发执行就可能会出现同时更改一块内存,从而出现运行结果错误), 可以提高程序的运行效率
- 2.多线程程序的线程切换比多进程程序快,付出的代价小 (因为这些线程指向同一个进程虚拟地址空间,有些可以共享的数据(全局变量)就能在线程切换的时候,不进行切换)可以充分发挥多核CPU并行(并行就是有多个每个CPU执行一个线程,各自执行各自的)的优势。
- 3.计算密集型的程序,可以进行拆分,让不同的线程执行计算不一 样的事情(比如我们要从1加到1亿我们可以让多个进程来各自计算其中一段加法,可以更快的得出结果。)
- 4.I/ 0密集型的程序,可以进行拆分, 让不同的线程执行不同的I/ 0操作,可以不用串型运行, 提高程序运行效率。(例如我们要从多个文件中读取内容,如果我们只有一个进程的话,那就只能从一个文件中读取之后,在从下一个文件中读取,这样的串行运行,但是当我们有多个进程,就可以让多个进程从多个文件中同时读取。)但也不是所有问题都可以拆分成多个进程去分开解决,比如引用《程序员的自我修养》中一句话,一个女人花十个月可以生出一个孩子,但是十个女人不能再一个月生出一个孩子。
- 2.缺点:
- 1.编写代码的难度更加高(当多个线程访问同一个程序的时候我们需要控制线程访问的先后顺序,要不然就可能出现问题)
- 2.代码的(稳定性)鲁棒性要求更加高,当多个线程在运行时,而CPU资源少的情况下一定是有一线程访问不到CPU资源的,那这时就一定要有线程被切换出来,将CPU资源让出来,这时一旦有线程霸占CPU资源占着不放的话,此时这个得不到CPU资源的线程就有可能崩溃,一旦它崩溃就会导致整个进程退出。
- 线程数量并不是越多越好,所以一个程序的线程数量一定是我们依照一个机器的配置(CPU数量)而经过测量来得出,创建多少个线程合适。

- 3.缺乏访问控制,多个线程同时访问一个空间,如果不加以控制,可能会导致程序产生二义性结果。
- 4.一个线程崩溃,会导致整个进程退出。
2.线程控制
-
2.1线程创建
- 2.1.1接口
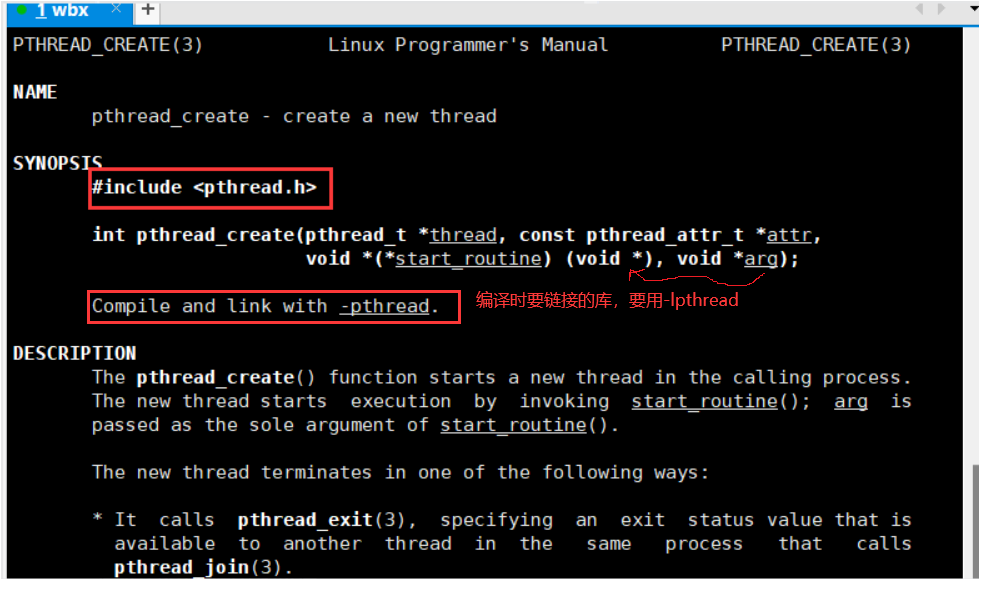
- int pthread_ create(pthread _t *thread, const pthread_ attr _t *attr ,void *(*start_ routine) (void *),void *arg) ;
- 参数:
- 1.thread :获取线程标识符(地址),本质 上就是线程独有空间的首地址
- 2.attr :线程的属性信息, 一 般填写NULL,采用默认的线程属性
- 属性信息当中比较关心的:
- 调用栈的大小
- 分离属性
- 调度策略:先来先服务,
- 分时策略,时间片轮转
- 调度优先级等等
- 3.start_ routine :函数指针, 线程执行的入口函数 (线程执行起来的时候,从该函数开始运行, 切记: 不是从main函数开始运行),当前线程执行时从这个函数开始执行。
- 4.arg:给线程入口函数传递参数;也就是说start_routine的参数就是它给传递的。
- 返回值:
- 成功==0
- 失败< 0
- 2.1.2演示代码:

- 在编译时要注意加上链接库选项:
- 我们运行发现并没有结构输出,这是因为创建出来一个的线程需要操作系统调度,这里我们在main函数中创建出来一个线程,这里有可能还没有调度我们创建出来的线程main函数就执行完毕返回了,而main函数返回也就意味着进程结束,而进程结束了,我们的线程也就不存在了。
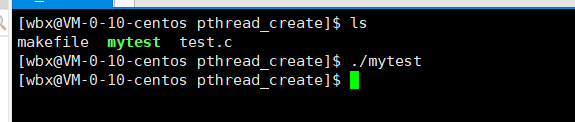
- 这里我们让main函数退出慢一点

- 我们再运行:发现工作线程这时执行了它的代码。

- 这里我们再往深了看,我们让创建出来的线程和main函数都不退出
- 运行起来我们看它的调用堆栈:

- 我们还可以用top查看进程的状态信息,在top -H选项就可以看到线程的状态信息

- 我们这里循环创建多个线程:并将每个线程区分开将for循环的值传递给线程让它打印出来

- 我们看结果,发现并不是像我们那样想的,打印出来0-4的数字,而是都打出来5,这时因为线程抢占式执行,可能将所有线程创建出来,然后才执行线程的代码,这时for循环已经结束,然后线程拿到的是for循环中局部变量i的地址,此时再去访问,因为最后退出时i是被加到了5,所以此时线程将i中的值打印了出来,这时十分危险的,因为i是一个局部变量,用完已经释放了,但此时还对它进行访问,就有可能导致错误。

- 解决上面的方式有两种一种是在main函数中创建一个变量,只要main函数存在,其他那个变量就存在。而main函数退出线程也就退出了,不存在非法访问。

- 还有就是我们在堆上开辟空间,在线程的结尾释放。

- 运行一下我们发现完美的解决了问题。
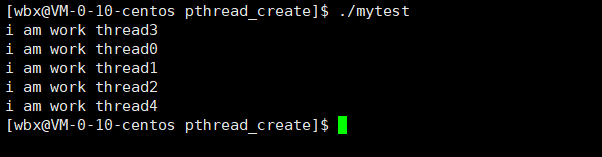
- 总结:不要给线程传递临时变量,因为传递临时变量当临时变量销毁时,线程拿到的是临时变量的地址,还可以访问那块被释放的空间,容易造成进程崩溃。
- 2.1.1接口
-
2.2线程终止
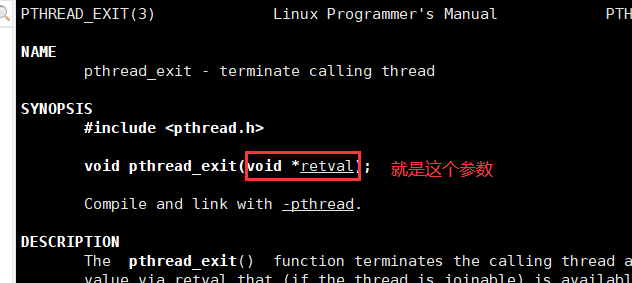
- 1.void pthread_ exit(void *retval) ;

- 1.1参数:
- retval :线程退出时, 传递给等待线程的退出信息。
- 1.2作用:
- 谁调用谁退出,主线程调用主线程终止,工作线程调用工作线程终止。
- 2.int pthread_cancel(pthread_ t thread) ;

- 2.1作用:
- 退出某个线程
- 2.2参数:
- thread:被终止的线程的标识符
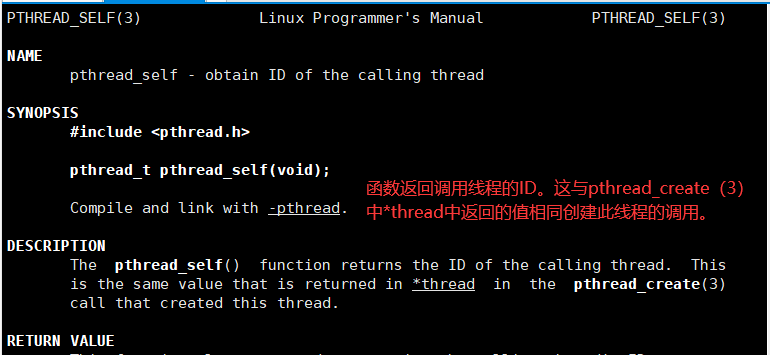
- 3.pthread_t pthread_self(void);(返回调用此函数的线程id)
- 代码演示:
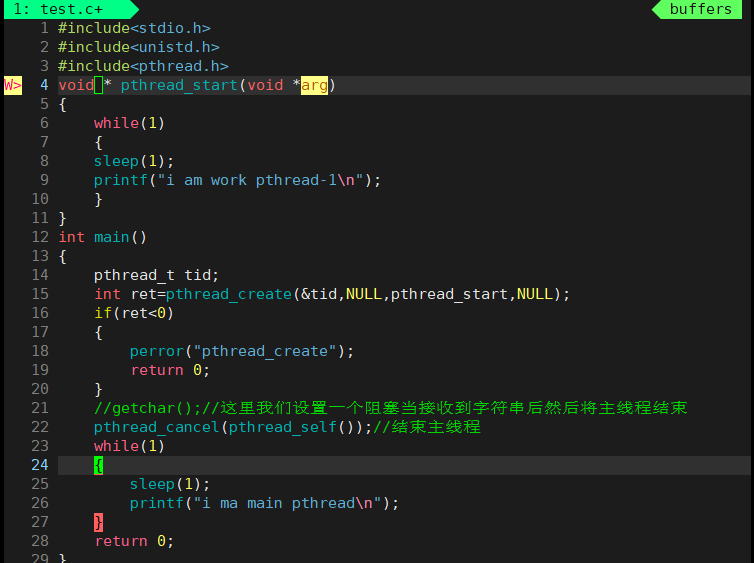
- 这里我们创建一个线程,然后在main函数中终止这个线程,为了防止是进程结束,而导致线程也结束我们在main函数中加一个死循环。

- 我们可以看到这里线程并不会立即终止,而是执行一下线程中的命令然后再终止。
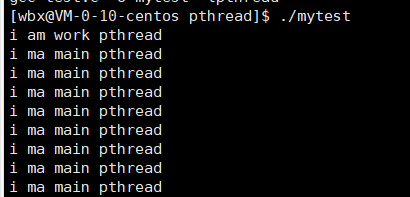
- 接下来我们将main线程结束,而不结束工作线程我们看有什么现象
- 我们设置阻塞的原因是因为要先查看进程id。
- 让代码跑起来

- 获取当前进程id

- 我们输入字符
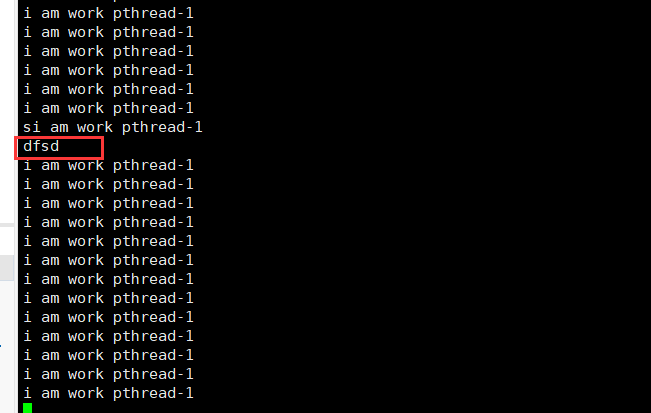
- 此时主线程退出我们输入top -H -p [进程id]可以看到此时主线程变成了僵尸状态
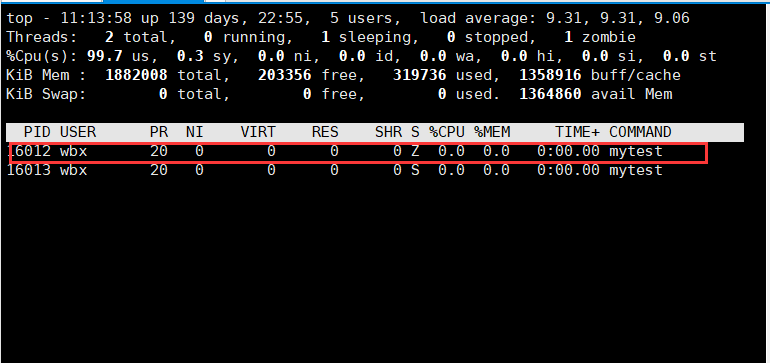
- 用ps aux|grep 查看状态也变成了Zl+状态

- 我们将while循环注释掉,让线程退出下一句就是return 0

- 我们来看结果可以发现这次进程直接退出了,主线程也不是僵尸状态了,这时因为当我们执行pthread_cancle函数时,结束一个线程时,他会执行下一行命令,这时我们将主线程退出了,它在退出前执行了return 0,就会使得整个进程结束,那么此时工作线程也就退出了。

- 我们这里再直接让主线程退出,然后工作线程等待30s之后退出,我们观察再工作线程退出后,主线程的状态。

- 我们让程序跑起来
- 这时主线程是僵尸状态
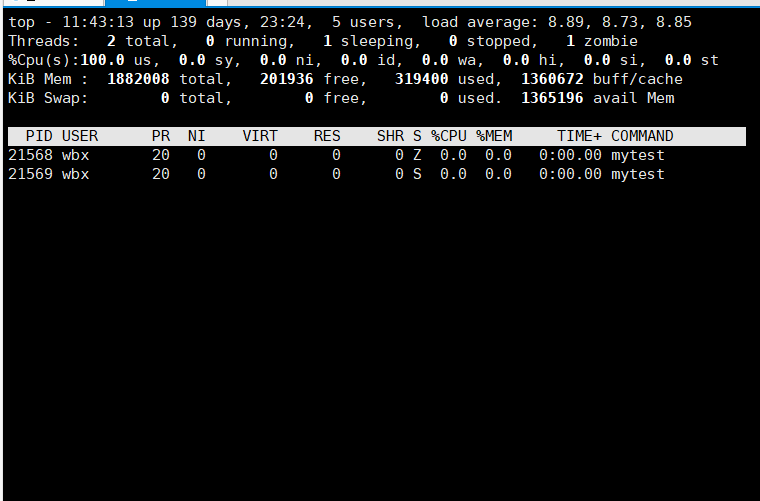
- 过了一会当工作线程退出时,主线程也随之退出

- 我们发现进程已经不存在了,退出了。
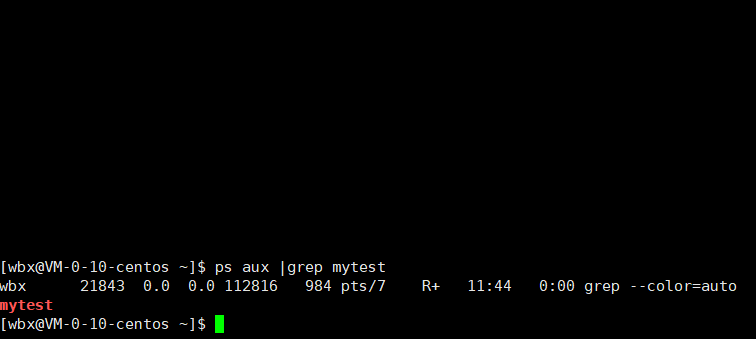
- 当我们让主线程退出而工作线程不退出时
- 这时我们查看调用栈,我们发现是无法看到进程的调用栈信息的。

- 总结:
- 1.当我们执行pthread_cancle函数时,结束一个线程时,他会执行pthread_cancle函数下一行命令,然后再结束线程。
- 2.当主线程退出后,工作线程如果一种执行主线程就会处于僵尸状态,而当工作线程执行完毕之后退出,整个进程也随之结束。
- 1.void pthread_ exit(void *retval) ;
-
2.3线程等待
- 1.线程被创建出来的默认属性是joinable属性,退出的时候,依赖其他线程来回收资源(主要是退出线程使用到的共享区当中的空间)
- 2.接口:
- int pthread_ join(pthread_ t thread, void **retval);
- 参数:
- thread:线程的标识符(就是要等待的线程的线程标识符)
- retval:退出线程的退出信息
- 第一种:线程入口函数代码执行完毕, 线程退出的,就是 入口函数的返回值

- 第二种: pthread_ exit退出的,就是pthread_exit的参数
- 第三种: pthread_ cancel退出的,就是 一个宏: PTHREAD_ CANCELED。
- 演示代码:
- 我们这里让工作线程等待30s退出,然后在主线程中等待工作线程退出

- 我们执行代码,查看当前进程的调用栈,发现主线程并没有退出,而是调用pthread_join一直阻塞等待工作进程退出,而当工作线程退出后,调用栈销毁。

-
2.4线程分离
- 设置线程的分离属性,一旦线程设置 了分离属性,则线程退出的时候,不需要任何人回收资源。 操作系统可以进行回收。
- 接口:
- int pthread_ detach (pthread_t thread) ;

- thread:设置线程分离的线程的标识符
- 演示代码:
- 我们这里让工作线程退出,然后不回收它的退出状态信息
- 可以看到它运行完直接退出了,也没有变成僵尸状态。

- 我们将工作线程设为分离状态,然后观察

- 让代码跑起来,发现工作线程也在运行
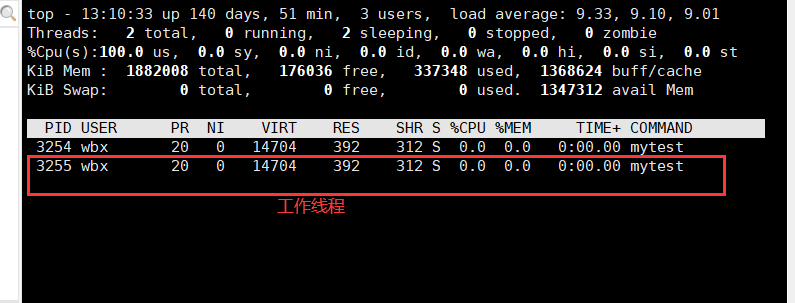
- 但是当工作线程退出后并没有变成僵尸状态,而是直接退出

- 我查看调用栈:
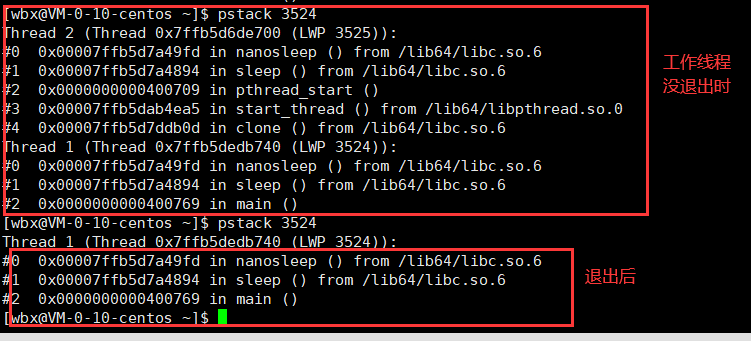
- 结论:无论工作其他线程等待不等待工作线程退出回收它的退出状态信息,工作线程都不会变为僵尸状态
看到这里如果觉得有用就点个赞吧!!!
