使用scrapy的日志有一大半的报错都是下面这个,错误原因很简单,记录一下找错的过程
Traceback (most recent call last):
File "/opt/miniconda/envs/app/lib/python3.8/site-packages/scrapy/utils/defer.py", line 55, in mustbe_deferred
result = f(*args, **kw)
File "/opt/miniconda/envs/app/lib/python3.8/site-packages/scrapy/core/spidermw.py", line 52, in _process_spider_input
return scrape_func(response, request, spider)
File "/opt/miniconda/envs/app/lib/python3.8/site-packages/scrapy/core/scraper.py", line 149, in call_spider
warn_on_generator_with_return_value(spider, callback)
File "/opt/miniconda/envs/app/lib/python3.8/site-packages/scrapy/utils/misc.py", line 246, in warn_on_generator_with_return_value
if is_generator_with_return_value(callable):
File "/opt/miniconda/envs/app/lib/python3.8/site-packages/scrapy/utils/misc.py", line 229, in is_generator_with_return_value
code = re.sub(r"^[\t ]+", "", inspect.getsource(callable))
File "/opt/miniconda/envs/app/lib/python3.8/inspect.py", line 985, in getsource
lines, lnum = getsourcelines(object)
File "/opt/miniconda/envs/app/lib/python3.8/inspect.py", line 967, in getsourcelines
lines, lnum = findsource(object)
File "/opt/miniconda/envs/app/lib/python3.8/inspect.py", line 798, in findsource
raise OSError('could not get source code')
OSError: could not get source code
看到报错很多人第一时间肯定是复制OSError: could not get source code到百度搜一下,搜出来的文章基本都是pyinstaller打包scrapy出现了这个错误,解决方法如下:
在spider代码里加上
import scrapy.utils.misc
import scrapy.core.scraper
def warn_on_generator_with_return_value_stub(spider, callable):
pass
scrapy.utils.misc.warn_on_generator_with_return_value = warn_on_generator_with_return_value_stub
scrapy.core.scraper.warn_on_generator_with_return_value = warn_on_generator_with_return_value_stub
但是我并没有使用pyinstaller,而且是在centos运行的scrapy,只能自己跟堆栈信息了。报错的调用栈也出现了warn_on_generator_with_return_value这个函数,所以我们从这个函数追一下他的使用,用vscode打开scrapy的源码(一般在python安装目录的Lib\site-packages\scrapy下)全局搜索一下warn_on_generator_with_return_value在哪个函数里被调用的
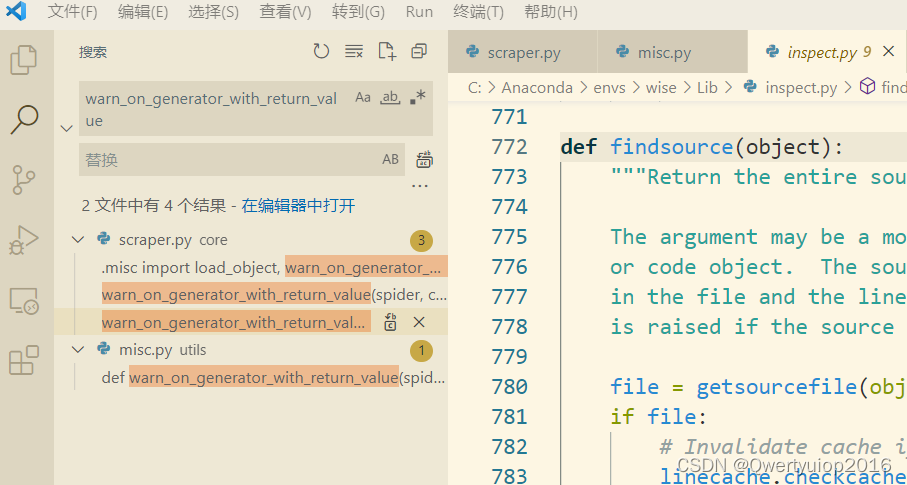
第二个文件misc.py里是定义函数的,暂时先不看,直接定位到scraper.py的地方
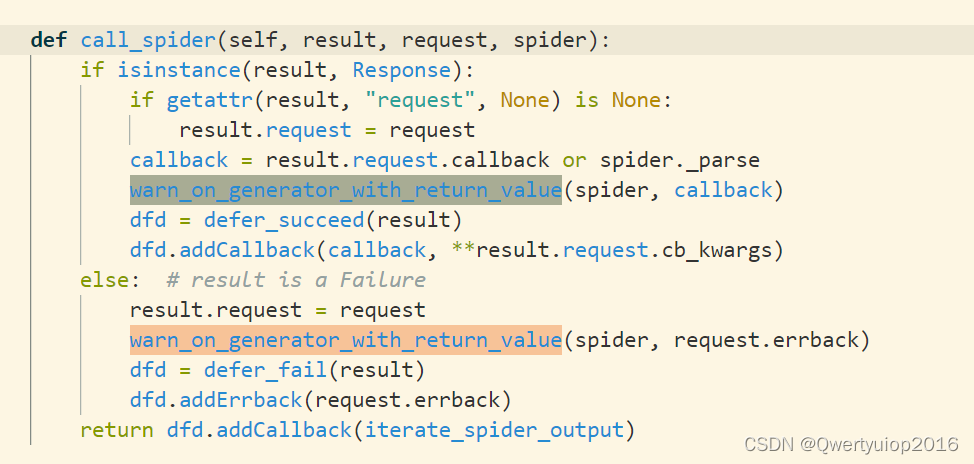
经过print调试发现,这个函数其实就是scrapy给Request添加回调函数用的,result就是个Response对象,而warn_on_generator_with_return_value是用来检查回调函数中是否包含错误的return
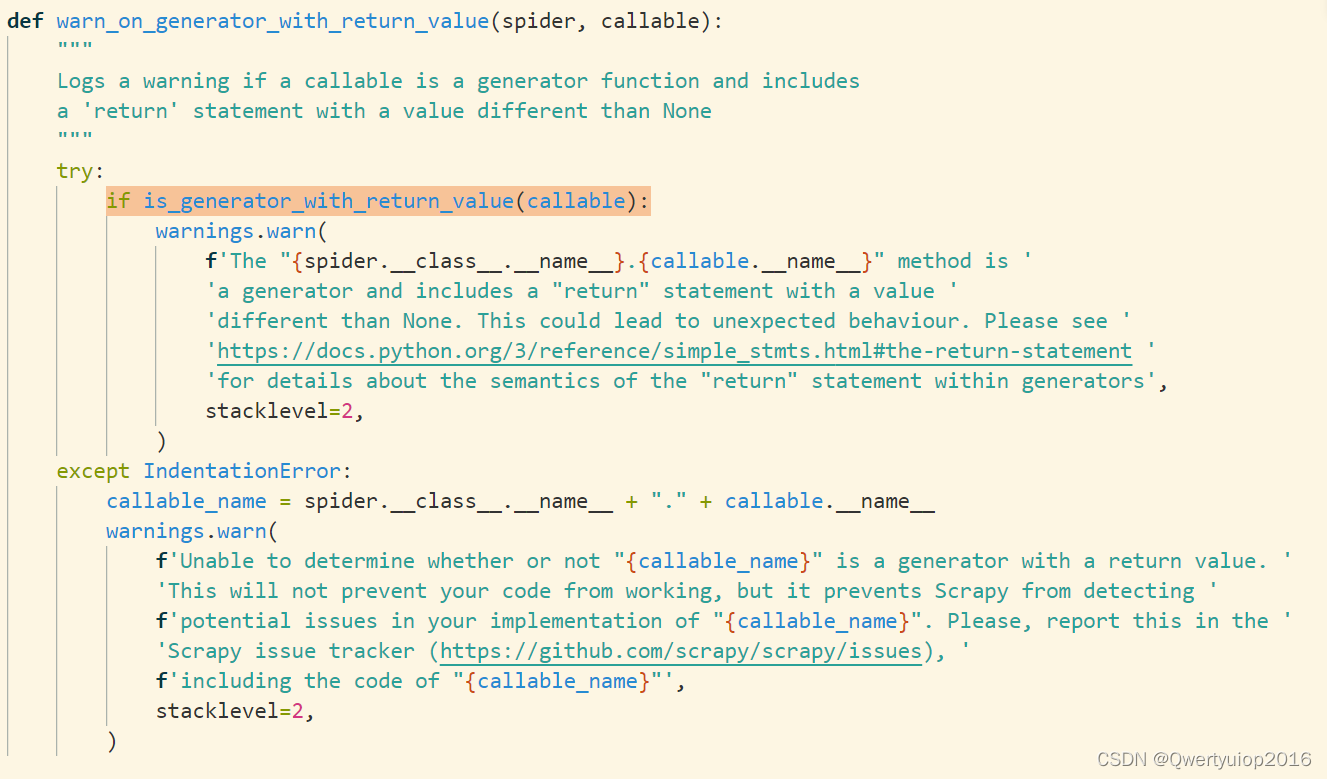
is_generator_with_return_value这个函数先不看,翻译一下下面警告的日志信息,大概意思是:
生成器函数不能return一个值,只能return None,因为这可能产生一些异常错误,详细请查看官网关于return关键字的解释: https://docs.python.org/3/reference/simple_stmts.html#the-return-statement
也就是说warn_on_generator_with_return_value这个函数只是用来检查你有没有在使用yield的同时,return了一个有效的值。所以这个函数在实际的运行中并没什么意义,只要你的代码按照规范来,就不用理它。上面的解决方法也是把它置空,让它不运行。
到这里还是没有解释为什么会抛出异常?继续看堆栈的错误信息,报错的实际代码是inspect.getsource(callable)这个函数,那么getsource在什么情况下会抛出OSError: could not get source code? 找不到文件或者没有权限操作这个文件,当然还有一种可能是Ulimit超过了限制,无法再打开文件,这个应该会伴随一个OSError: [Errno 24] Too many open files:的错误,关于这个问题解决方法请看:https://www.jianshu.com/p/47336fcd22da。在开启线程比较多的时候会遇到。
翻到日志报错的最开始那条,看到了 爬虫运行完成这条日志,恍然大悟。因为我在spider运行完成之后写了删除spider文件的逻辑,这就导致了还在运行的爬虫找不到自己的代码了
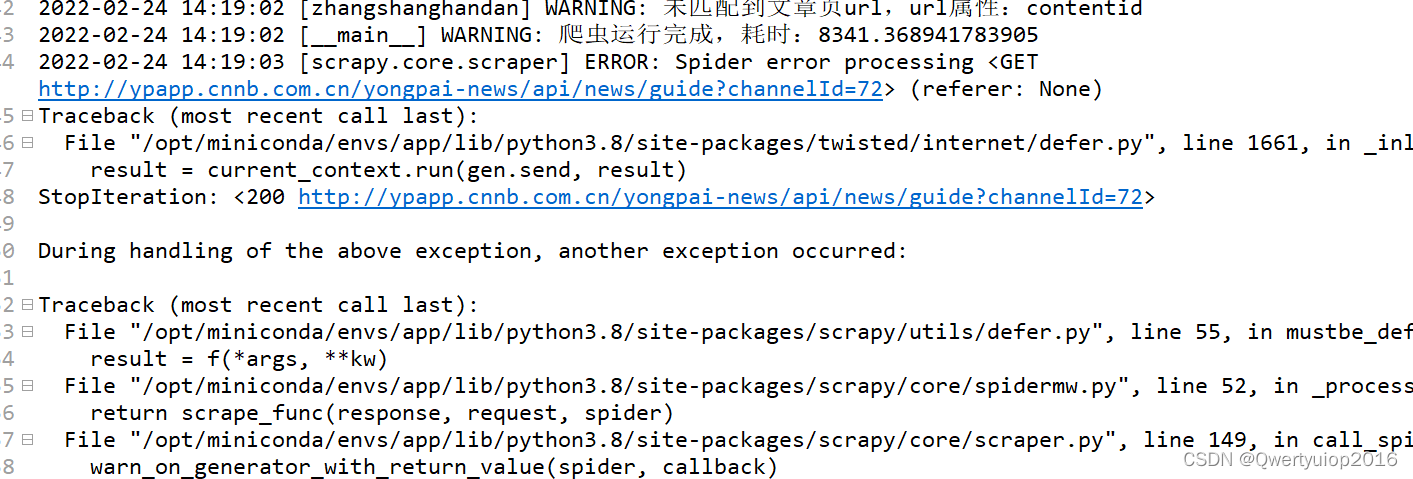
用多进程启动的scrapy,明明用了join等待,为什么直接就结束了,也是无语,又是一个新的坑。