一、数据处理
1、数据增强
深度学习模型通常需要大量数据才能正确训练。 使用数据增强技术从现有数据中获取更多数据通常很有用。 主要的总结在下表中。 更准确地说,给定以下输入图像,以下是我们可以应用的技术:

2、批量标准化
它是超参数的一个步骤,用于规范化批
。 通过记下
,
我们想要对批次进行校正的均值和方差,如下所示:
它通常在完全连接/卷积层之后和非线性层之前完成,旨在允许更高的学习率并减少对初始化的依赖。
二、训练神经网络
1、定义
Epoch:在训练模型的上下文中,epoch 是一个术语,用于指代模型看到整个训练集以更新其权重的一次迭代。
小批量梯度下降:在训练阶段,由于计算复杂性或噪声问题,更新权重通常不是一次基于整个训练集或一个数据点。 相反,更新步骤是在小批量上完成的,其中一批中的数据点数量是我们可以调整的超参数。
损失函数:为了量化给定模型的执行情况,损失函数通常用于评估模型输出
正确预测实际输出
的程度。
交叉熵损失:在神经网络的二元分类上下文中,交叉熵损失是常用的,定义如下:
2、寻找最佳权重
反向传播:反向传播是一种通过考虑实际输出和期望输出来更新神经网络中权重的方法。 使用链式法则计算每个权重 的导数。
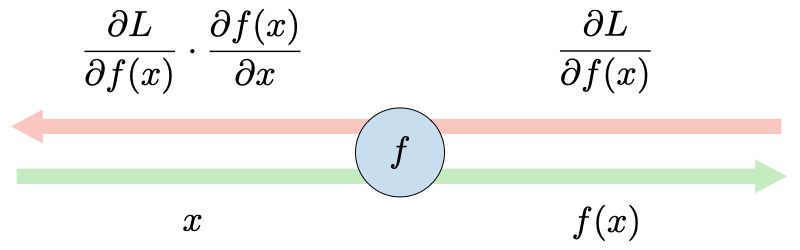
使用此方法,每个权重都使用以下规则更新:
更新权重:在神经网络中,权重更新如下:
步骤 1:获取一批训练数据并执行前向传播以计算损失。
步骤 2:反向传播损失以获得损失相对于每个权重的梯度。
第 3 步:使用梯度更新网络的权重。

三、参数调优
1、权重初始化
Xavier initialization:Xavier 初始化不是以纯粹随机的方式初始化权重,而是能够使初始权重考虑到体系结构独有的特征。
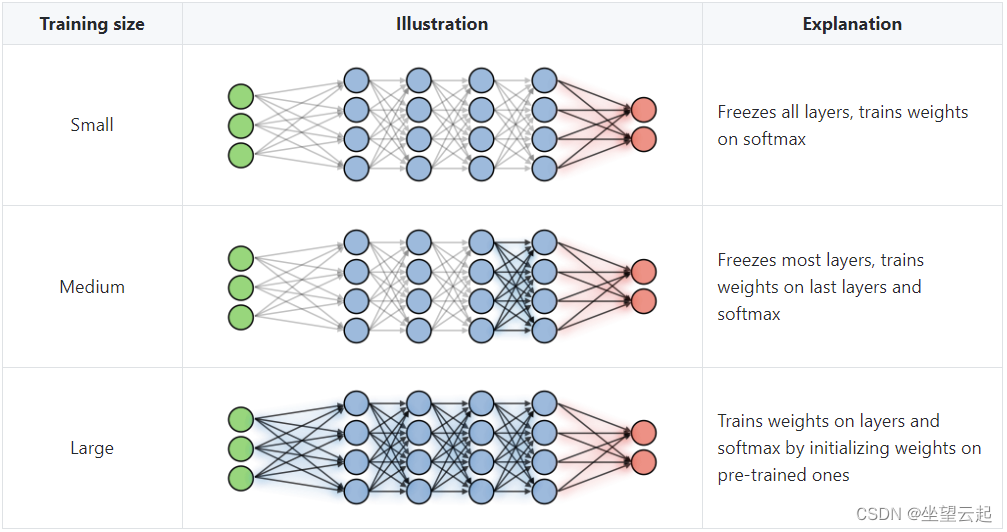
迁移学习:训练深度学习模型需要大量数据,更重要的是需要大量时间。 在需要数天/数周训练的庞大数据集上利用预训练的权重并将其用于我们的用例通常很有用。 根据我们手头有多少数据,以下是利用它的不同方法:
2、优化收敛
学习率:学习率,通常记为 或有时为
,表示权重更新的速度。 它可以固定或自适应地改变。 目前实践中比较好的方法叫做 Adam,这是一种适应学习率的方法。
自适应学习率:训练模型时让学习率变化,可以减少训练时间,提高数值最优解。 虽然 Adam 优化器是最常用的技术,但其他技术也很有用。 它们总结在下表中:
| Method | Explanation | Update of w | Update of b |
| Momentum | Dampens oscillations Improvement to SGD 2 parameters to tune |
||
| RMSprop | Root Mean Square propagation Speeds up learning algorithm by controlling oscillations |
||
| Adam | Adaptive Moment estimation Most popular method 4 parameters to tune |
四、正则化
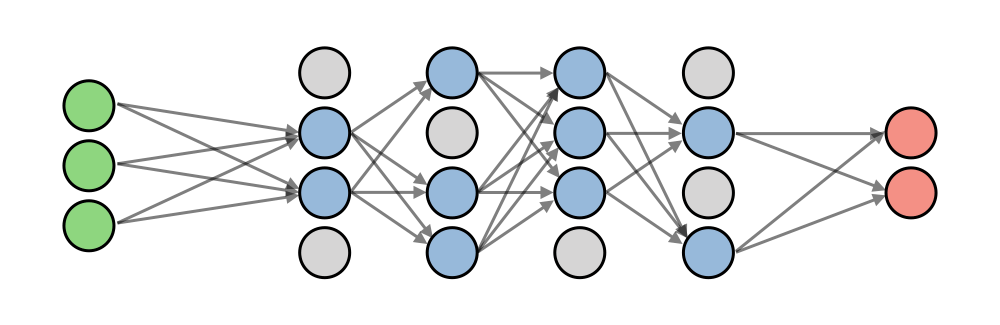
Dropout:Dropout 是神经网络中使用的一种技术,通过丢弃概率的神经元来防止过度拟合训练数据。 它迫使模型避免过度依赖特定的特征集。
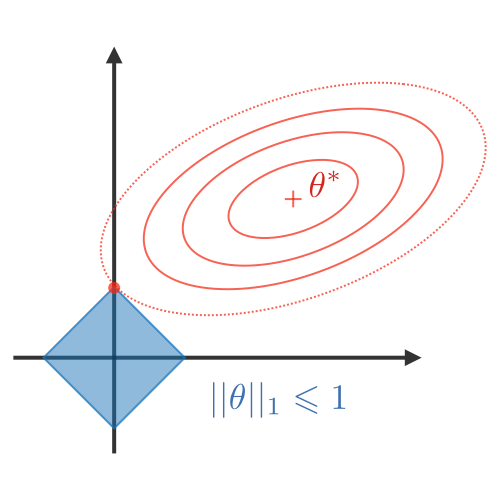
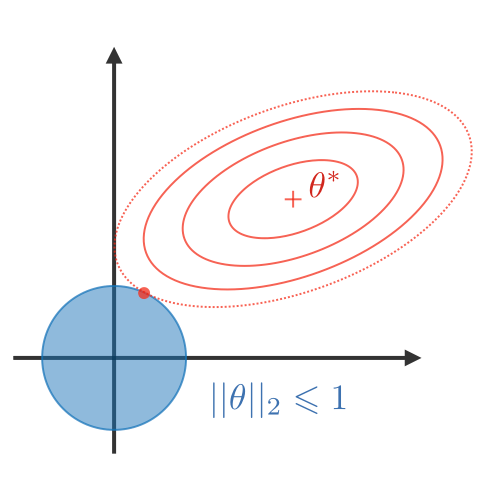
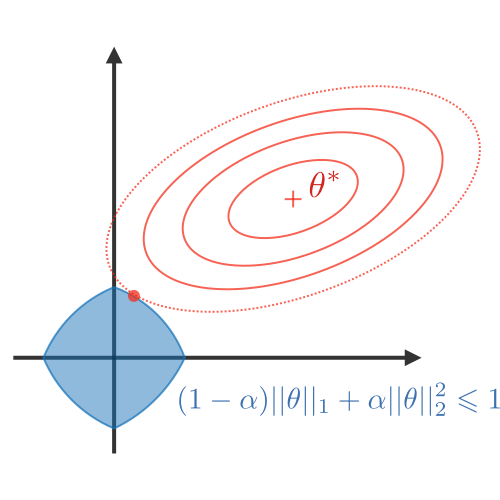
权重正则化:为了确保权重不会太大并且模型不会过度拟合训练集,通常对模型权重执行正则化技术。 主要的总结如下表:
| LASSO | Ridge | Elastic Net |
| • Shrinks coefficients to 0 • Good for variable selection |
Makes coefficients smaller | Tradeoff between variable selection and small coefficients |
|
|
|
|
提前停止:一旦验证损失达到平稳或开始增加,这种正则化技术就会停止训练过程。

五、较好的实践
Overfitting small batch:在调试模型时,进行快速测试以查看模型本身的架构是否存在任何重大问题通常很有用。 特别是,为了确保模型可以正确训练,在网络内部传递一个 mini-batch 以查看它是否可以过拟合。 如果不能,则意味着模型要么太复杂,要么不够复杂,甚至无法在小批量上过拟合,更不用说正常大小的训练集了。
Gradient checking:梯度检查是在执行神经网络的反向传播过程中使用的一种方法。 它将分析梯度的值与给定点的数值梯度进行比较,并起到正确性检查的作用。
| Type | Numerical gradient | Analytical gradient |
| Formula | ||
| Comments | • Expensive; loss has to be computed two times per dimension • Used to verify correctness of analytical implementation • Trade-off in choosing $h$ not too small (numerical instability) nor too large (poor gradient approximation) |
• 'Exact' result • Direct computation • Used in the final implementation |