数据结构
struct pg_pool_t{
enum {
TYPE_REPLICATED = 1, // 多副本
//TYPE_RAID4 = 2, // raid4 (never implemented)
TYPE_ERASURE = 3, // EC
};
uint64_t flags; //定义了多种flags,例如FLAG_FULL
__u8 type; //多副本或EC
__u8 size, min_size; //副本数和至少保证的副本数
__u8 crush_ruleset; ///< ruleset的id
__u8 object_hash; //映射hash算法
private:
__u32 pg_num, pgp_num; ///< number of pgs
};
class MOSDOp : public Message {
static const int HEAD_VERSION = 5;
static const int COMPAT_VERSION = 3;
private:
uint32_t client_inc; //client id
__u32 osdmap_epoch; //版本号
__u32 flags; //客户端请求带的flags,例如CEPH_OSD_FLAG_ACK
utime_t mtime; //客户端请求所带的mtime
object_t oid; //操作的对象
object_locator_t oloc; //对象的位置信息?
pg_t pgid; //对象所在的pgid
public:
vector<OSDOp> ops; //多个操作集合
……
}
struct OSDOp {
ceph_osd_op op;
sobject_t soid;
bufferlist indata,outdata;
int32_t rval;
};
struct ObjectState {
object_info_t oi;
bool exists;
};
struct ObjectContext {
ObjectState obs;//对象当前的状态
SnapSetContext *ssc;//快照上下文信息
Context *destructor_callback;//对象析构的时候快照相关资源释放
private:
Mutex lock;//内部使用锁
Public:
Cond cond;//内部控制读写等待,应该是private才对
int unstable_writes, readers, writers_waiting, readers_waiting;//正在写,等待写,正在读,等待读
Bool blocked;//copy操作的时候才会用到
ObjectContextRef blocked_by;//阻塞了本对象写操作的对象
set<ObjectContextRef> blocking;//本对象阻塞了其他对象写操作的集合
map<pair<uint64_t, entity_name_t>, WatchRef> watchers;//该对象设置的watcher的集合
struct RWState {
enum State {
RWNONE,
RWREAD,
RWWRITE,
RWEXCL,
};
State state;//上面3种状态
uint64_t count;//读请求或写请求的次数
list<OpRequestRef> waiters;//因为获取不到锁被挂起的请求
bool recovery_read_marker;//设置了这个状态后,不允许获取写锁
} rwstate;
};
struct OpContext {
OpRequestRef op;//请求信息
osd_reqid_t reqid;
vector<OSDOp> &ops;//本次req中的ops
const ObjectState *obs;//老的objectcontext的obs
const SnapSet *snapset;
ObjectState new_obs;//最终的对象状态
SnapSet new_snapset;
bool modify;//一般为false,ec或UNDIRTY相关操作会为true
bool user_modify;//默认false,写操作为true
uint64_t bytes_written, bytes_read;//本次操作读和写的字节数
utime_t mtime;
SnapContext snapc; // writer snap context
eversion_t at_version; // pg当前版本和osdmap当前版本
version_t user_at_version; // pg当前的user操作版本
......
};
概要分析
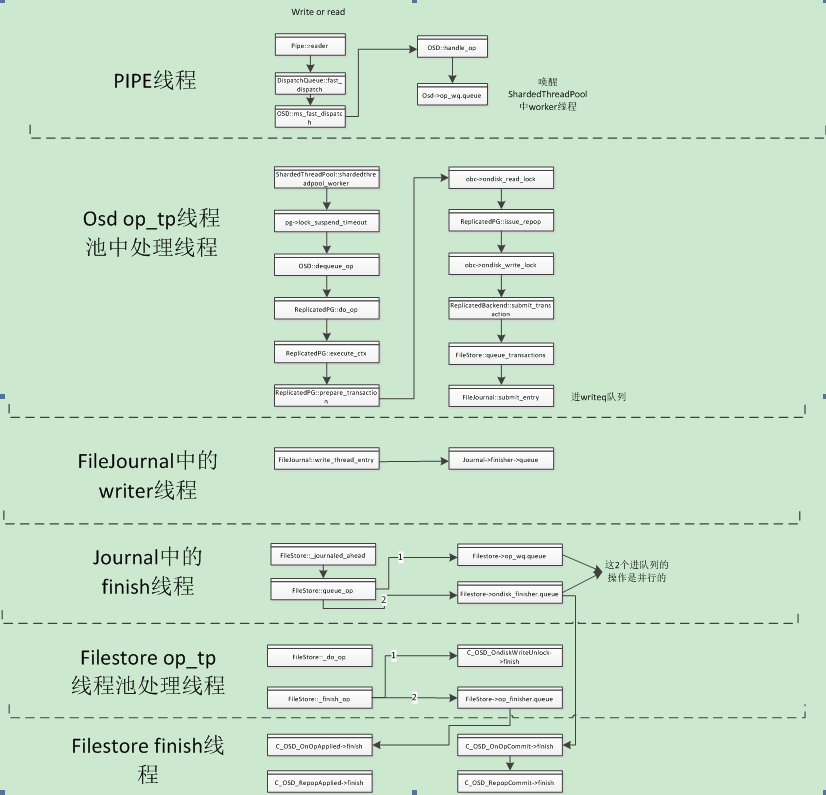
1.请求通过网络层pipe的reader线程接收到client请求,将请求发送到osd的op_wq队列
2.Osd的op_tp线程池中线程会从op_wq队列中获取请求,并进一步解析请求,如果是读请求,则直接在该线程获取数据,并返回给client。如果是写请求,则根据请求的op打包事务,发送到日志队列writeq。
3.日志线程会从writeq中获取写日志请求,完成后交给日志的finish线程处理。
4.日志的finish线程会将请求丢给filestore的op_wq队列。
5.Filestore的op_tp线程池将数据落盘
6.再通过filestore的finish线程将请求返回,进行回调处理
关键函数
OSD::handle_op
使用场景:1.处理客户端的op请求,在pipe的reader线程中被调用
细节分析:1.message的检查,包括和客户端的连接状态、文件名是否过长、黑名单、写场景下osd是否full状态、单次写入数据量是否过大。
2.OSDService::should_share_map判断是否要通知客户端更新osdmap。
3.根据请求的pgid获取pg信息,并调用OSD::enqueue_op进入osd的op_wq队列
ReplicatedPG::do_op
使用场景:1.处理客户端的op请求,在osd的op_tp线程池中被调用
细节分析:1.对应pg存在于各种非active,当前操作需要放到不同的队列中等待。
2.对于dup操作,通过reqid来查询请求,判断当前请求是否是dup操作。如果是dup操作,并且已经完成,则直接返回成功。
3.根据oid获取objectcontext,从pg缓存中获取objectcontext,如果缓存中不存在,则重新创建一个,保存在缓存中。
4.根据请求op,objectcontext创建opcontext。
5.调用get_rw_locks加锁,该锁主要保证操作在多副本间的一致性。在remove_repop函数的release_op_ctx_locks函数中释放。该锁是不阻塞线程的,请求会被暂存在objectcontext中,后续会重新处理。
6.调用execute_ctx。
ReplicatedPG::execute_ctx
使用场景:1.处理客户端的op请求,在osd的op_tp线程池中被调用
细节分析:1.PgLog版本+1,并保存在opcontext,标记为当前op的pgLog版本号,以及记录请求的mtime。由于整个线程的逻辑处理都在pg_lock中进行,所以保证了整个版本号递增的原子性。
2.如果是读操作会调用ondisk_read_lock获取读锁。该锁保证了对象在主osd节点操作的原子性,由于write请求是先写journal再异步写disk,所以这里如果该对象还未异步刷到disk是不会释放写锁,则本次读会被挂住。该锁是阻塞线程的。
3.调用prepare_transaction。该函数用于处理各种op操作,写操作则打包成事务,读操作则直接从磁盘上读取,创建写、删等操作的pg_log_entry。
4.创建返回给客户端的消息实例MOSDOpReply。并设置返回值。
5.调用calc_trim_to计算需要trim的版本号。min_last_complete_ondisk表示同步到所有osd的pglog的版本号,因此这个版本之后的pglog都是不能够被trim的。pg_log实例中的index_log(pg_log_entry_t),保留了未trim的pg_log_entry_t的信息,并且所有的entry都是有序存放在index_log中。Pg_log只保存osd_min_pg_log_entries多日志,当index_log中size大于这个值时,需要开始trim,并计算出需要trim的条数num_to_trim,通过遍历index_log,trim掉num_to_trim即可,当然如果其中某一个pg_log_entry_t大于min_last_complete_ondisk则不能trim了。这个时候pg的entry可能大于osd_min_pg_log_entries。
6.调用issue_repop。负责将事务发送给各个副本,同时将事务发送给日志处理线程。
7.调用eval_repop。该函数主要负责all_commit(所有副本和本地存储日志完成返回)和all_applied(所有副本和本地存储磁盘返回)的处理,将请求返回给客户端,在这里调用感觉意义不大。
ReplicatedPG::issue_repop
使用场景:1.处理客户端的op请求,在osd的op_tp线程池中被调用
细节分析:1.更新peer_info中各个shard的pginfo的版本信息。
2.对objectcontext加ondisk_lock。对于写操作必须要保证数据写到disk的pagecache中才会释放该锁。
3.创建3个回调。这里要先理解commit和applied的含义,commit是指写完日志返回的情况,applied是指写完disk的pagecache返回的场景。而slave osd的完成写请求返回,在主osd的处理是会先调用commit再调用applied,所以对于副本osd返回的请求其实是applied和commit同时完成。on_all_commit表示所有副本的commit操作都完成了后使用的回调,on_all_applied表示所有副本的applied都完成后使用的回调。onapplied_sync表示本地存储某对象写到disk的pagecache后使用的回调。
4.调用submit_transaction函数
ReplicatedBackend::submit_transaction
使用场景:1.处理客户端的op请求,在osd的op_tp线程池中被调用
细节分析:1.创建InProgressOp实例,并插入到in_progress_ops缓存中。该实例主要用于控制该op的多副本之间的完成情况。waiting_for_commit和waiting_for_applied的set集合初始状态为所有osd对应的pg_shard_t值,当有副本返回则对应的pg_shard_t则会从set集合中删除。当set为空,则调用对应的回调。
2.issue_op负责将数据打包到MSG_OSD_REPOP消息请求中,发送到各个副本上。
3.log_operation负责把本次操作的pglog_entry和pg_info都保存在事务中。计算并保存要trim的pglog_entry到PGLog的trimmed中去。同时把要删除的pglog也打包到事务中去
4.注册3个回调context到op_t。其中C_OSD_OnOpApplied和C_DeleteTransaction是在filestore层数据写入到pagecache中后,通过filestore中的finish线程调用。C_OSD_OnOpApplied用于调用C_OSD_RepopApplied->eval_repop,在eval_repop 的all_applied场景释放相关资源。
总结
从整个osd的数据读写流程来思考数据的并发性和顺序性。可以参考
http://www.sysnote.org/2016/08/29/ceph-io-sequence/
场景一:不同pg的对象操作。相互独立的pg不存在顺序性,且整个流程上看都是可以并发操作的。
场景二:同一个pg的不同对象操作。由于在osd的op_tp线程池处理过程会加pg锁,所以在进入journal队列前是串行的,但这一段逻辑没有io操作,锁的时延并不高。在filestore层会加一个osr->apply_lock.Lock(),这个osr也是一个pg一个实例,所以在filestore层对象读写操作也是串行的,由于写操作都要对应更新pglog_entry,估计是为了保证pglog的一致性。不过好在写完journal,请求已经返回client。
场景三:同一个对象的读写操作。由于在osd的op_tp线程池处理会对objectcontext加disk_lock,所以如果写操作没有在filestore层完成pagecache的写入,是不会释放写锁,从而读操作会阻塞在加读锁上面。
场景四:同一个对象的写写操作。其实和场景二是一样的,filestore层和osd层都有类似的pg锁,来保证同一个pg内的操作是串行化的,在journal层本身就是串行化。