撒花啦啦啦啦啦,虽然没太多时间搞懂课本,打算考前速成了。。。
目录
给出一个矩阵乘法的普通代码A,设法优化该代码,从而提高性能。
2、编写代码来测量x86机器上(非虚拟机)的Cache 层次结构和容量
2、测量分析出Cache 的层次结构、容量以及L1 Cache行有多少?
目的:
- 加强对Cache工作原理的理解;
- 体验程序中访存模式变化是如何影响cahce效率进而影响程序性能的过程;
- 学习在X86真实机器上通过调整程序访存模式来探测多级cache结构。
环境
X86真实机器
内容和步骤
1、分析Cache访存模式对系统性能的影响
-
给出一个矩阵乘法的普通代码A,设法优化该代码,从而提高性能。
代码A:
#include <sys/time.h>
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char *argv[])
{
float *a,*b,*c, temp;
long int i, j, k, size, m;
struct timeval time1,time2;
if(argc<2) {
printf("\n\tUsage:%s <Row of square matrix>\n",argv[0]);
exit(-1);
} //if
size = atoi(argv[1]);
m = size*size;
a = (float*)malloc(sizeof(float)*m);
b = (float*)malloc(sizeof(float)*m);
c = (float*)malloc(sizeof(float)*m);
for(i=0;i<size;i++) {
for(j=0;j<size;j++) {
a[i*size+j] = (float)(rand()%1000/100.0);
b[i*size+j] = (float)(rand()%1000/100.0);
}
}
gettimeofday(&time1,NULL);
for(i=0;i<size;i++) {
for(j=0;j<size;j++) {
c[i*size+j] = 0;
for (k=0;k<size;k++)
c[i*size+j] += a[i*size+k]*b[k*size+j];
}
}
gettimeofday(&time2,NULL);
time2.tv_sec-=time1.tv_sec;
time2.tv_usec-=time1.tv_usec;
if (time2.tv_usec<0L) {
time2.tv_usec+=1000000L;
time2.tv_sec-=1;
}
printf("Executiontime=%ld.%06ld seconds\n",time2.tv_sec,time2.tv_usec);
return(0);
}//main由于给定的代码适用于linux,而我的x86机器是windows系统,所以更换了部分库函数。
优化后A代码:
#include<Windows.h>//ms级别时间记录
#include <time.h>
#include "unistd.h"
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char* argv[])
{
float* a, * b, * c, temp;
long int i, j, k, size, m;
clock_t startTime, endTime;//秒级程序计时
if (argc < 2) {
printf("\n\tUsage:%s <Row of square matrix>\n", argv[0]);
exit(-1);
} //if
size = atoi(argv[1]);
m = size * size;
a = (float*)malloc(sizeof(float) * m);
b = (float*)malloc(sizeof(float) * m);
c = (float*)malloc(sizeof(float) * m);
for (i = 0; i < size; i++) {
for (j = 0; j < size; j++) {
a[i * size + j] = (float)(rand() % 1000 / 100.0);
b[j * size + i] = (float)(rand() % 1000 / 100.0);
}
}
startTime = clock();//计时开始
for (i = 0; i < size; i++) {
for (j = 0; j < size; j++) {
c[i * size + j] = 0;
for (k = 0; k < size; k++)
c[i * size + j] += a[i * size + k] * b[j * size + k];
}
}
endTime = clock();//计时结束
printf("Executiontime=%lf seconds\n",(double)(endTime - startTime) / CLOCKS_PER_SEC);
return 0;
}//main
- 改变矩阵大小,记录相关数据,并分析原因。(图1)


图表 1 优化前后的数据
2、编写代码来测量x86机器上(非虚拟机)的Cache 层次结构和容量
- 设计一个方案,用于测量x86机器上的Cache层次结构,并设计出相应的代码;
- 运行你的代码获得相应的测试数据;
- 根据测试数据来详细分析你所用的x86机器有几级Cache,各自容量是多大?
- 根据测试数据来详细分析L1 Cache行有多少?
结果及分析
1、分析Cache访存模式对系统性能的影响
表1、普通矩阵乘法与及优化后矩阵乘法之间的性能对比
| 矩阵大小 |
100 |
500 |
1000 |
1500 |
2000 |
2500 |
3000 |
| 一般算法执行时间 |
<0.001 |
0.738 |
6.293 |
20.869 |
39.705 |
110.45 |
175.955 |
| 优化算法执行时间 |
<0.001 |
0.723 |
5.667 |
15.585 |
34.1 |
66.497 |
113.628 |
| 加速比 speedup |
无 |
1.0207 |
1.1105 |
1.3390 |
1.1643 |
1.6610 |
1.5485 |
加速比定义:加速比=优化前系统耗时/优化后系统耗时;
所谓加速比,就是优化前的耗时与优化后耗时的比值。加速比越高,表明优化效果越明显。

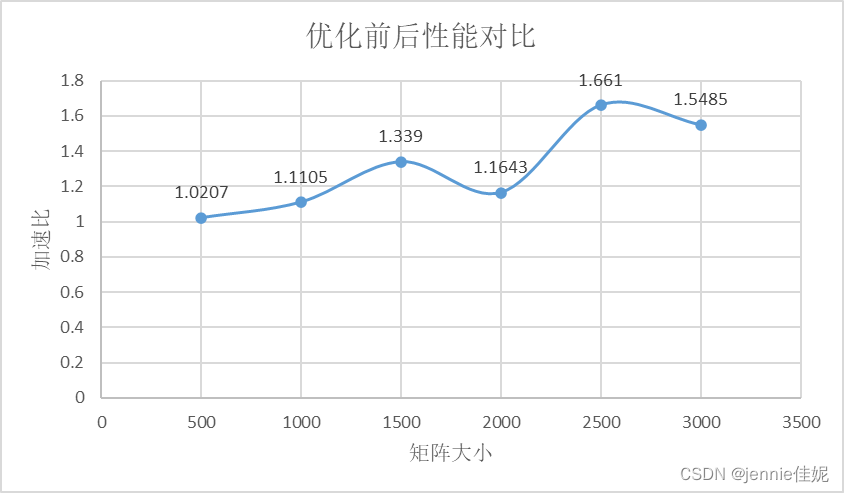
分析原因:经过代码阅读可发现改代码完成了矩阵相乘。b矩阵在被乘时会按列依次取数,这就无法很好利用Cache访存模式的优势(取出局部顺序存取数据备用)。所以我在存取b矩阵时就行列颠倒存取,这样矩阵相乘时就可以实现按行取数。
2、测量分析出Cache 的层次结构、容量以及L1 Cache行有多少?
-
实验原理
cache分为3层L1、L2、L3,对于每一个层级边界的数据存取会产生较大的速率变化,从而大概得出各层级的cache大小。
-
测量方案及代码
根据原理,我们可以写一个测量cache函数模块,参数传一个内存块大小(模拟的cache层级大小),用字符数组进行存储。通过随机产生访问位置存于位置数组,接着依次访问并读取总时间。因为每次读取时间很短,所以我们需要增大读取次数并记录总时间,这里我选择1亿次读取求和总时间。随着内存块的递增,会出现几次较大时间增加,即达到cache层级边界,从而大概估计出不同cache层级大小。
在测出cache第一级大小后,在此范围内确定cacheline,不同间隔取数,如果小于line耗时较短,大于耗时较大。
要注意不要用自带优化的开发环境,在这里我采用dev里的GNU C++11测试。
代码如下:
#include<bits/stdc++.h>
using namespace std;
using std::chrono::high_resolution_clock;
using std::chrono::duration;
using std::chrono::duration_cast;
random_device rd;//随机数生成
mt19937 gen(rd());
vector<int> sizes{ 8,16,32,64,128,256,384,512,768,1024,1536,2048,3072,4096,5120,6144,7168,8192,10240,12288,16384 };
char* cache1;
vector<int> line{ 1,2,4,8,16,32,64,96,128,192,256,512,1024,1536,2048 };
//测层级,参数为内存块大小(对应cache大小),存于字符数组,随机产生访问位置存于位置数组,若设置的内存块大小刚好是cache大小,cache层级边界时间会有较大改变
void test(int size) {
int n = size / sizeof(char); //获得字符数组大小
char* arr = new char[n]; //申请对应大小字符数组用于存储同等大小内存块
memset(arr, 1, sizeof(char) * n); //初始字符数组
uniform_int_distribution<> num(0, n - 1); //大规模随机数0~n-1
vector<int> pos; //位置数组
for (int i = 0; i < 100000000; i++)
{
pos.push_back(num(gen)); //随机产生位置并压入数组
}
int sum = 0; //由于取数
high_resolution_clock::time_point t1 = high_resolution_clock::now();
for (int i = 0; i < 100000000; i++) {
sum += arr[pos[i]]; //取数
}
high_resolution_clock::time_point t2 = high_resolution_clock::now();
duration<double> time_span = duration_cast<duration<double>>(t2 - t1);
double dt = time_span.count();
cout << "size=" << (size / 1024) << "KB,time=" << dt << "s" << endl;
delete[]arr;
}
void cacheline(char* cache1, int line, int size)
{
int n = size / sizeof(char);
int sum = 0;
high_resolution_clock::time_point t1 = high_resolution_clock::now();
for (int j = 0; j < line; j++)
{
for (int i = 0; i < n; i += line)
{
sum += cache1[i];
}
}
high_resolution_clock::time_point t2 = high_resolution_clock::now();
duration<double> time_span = duration_cast<duration<double>>(t2 - t1);
double dt = time_span.count();
cout << "length=" << line << "B time=" << dt << endl;
}
int main() {
for (auto s : sizes)
{
test(s * 1024);
}
cache1 = new char[100000000 * 10 / sizeof(char)];
memset(cache1, 1, 100000000 * 10); //初始字符数组
for (auto l : line)
{
cacheline(cache1, l, 100000000);
}
return 0;
}
- 测试结果(图2)


图表 2 cache 层级 cacheline测试
| size/KB |
time |
| 8 |
0.220814 |
| 16 |
0.219681 |
| 32 |
0.235284 |
| 64 |
0.21997 |
| 128 |
0.23217 |
| 256 |
0.219658 |
| 384 |
0.219657 |
| 512 |
0.251327 |
| 768 |
0.259962 |
| 1024 |
0.251333 |
| 1536 |
0.266458 |
| 2048 |
0.266981 |
| 3072 |
0.298386 |
| 4096 |
0.659617 |
| 5120 |
1.09868 |
| 6144 |
1.27285 |
| 7168 |
1.35011 |
| 8192 |
1.38039 |
| 10240 |
1.39738 |
| 12288 |
1.4313 |
| size/KB |
time/s |
| 1 |
0.188937 |
| 2 |
0.188345 |
| 4 |
0.191741 |
| 8 |
0.184663 |
| 16 |
0.203503 |
| 32 |
0.22008 |
| 64 |
0.314155 |
| 96 |
0.392433 |
| 128 |
0.392126 |
| 196 |
0.424075 |
| 256 |
0.439131 |
| 512 |
0.565762 |
| 1024 |
0.737552 |
| 1536 |
0.74834 |
| 2048 |
0.774764 |


-
分析过程
由数据和图片可以看出,384KB-512KB首次出现较大时间增加,所以估计第一级cache大小在384KB-512KB;3072KB-4096KB再次出现较大时间增加,所以估计第二级cache大小在3072KB-4096KB;在8192KB之后时间趋于不变,就应该是超过第三级cache的区域,所以估计第三级cache在8192KB左右。
cacheline测试里,发现在间隔超过32B长度取数时时间增加较大,所以估计cacheline为32B。
-
验证实验结果
我运用任务管理器和CPU-Z工具进行查看,发现cache的3级大小分别为512KB、4MB、8MB,与实验结果一致。
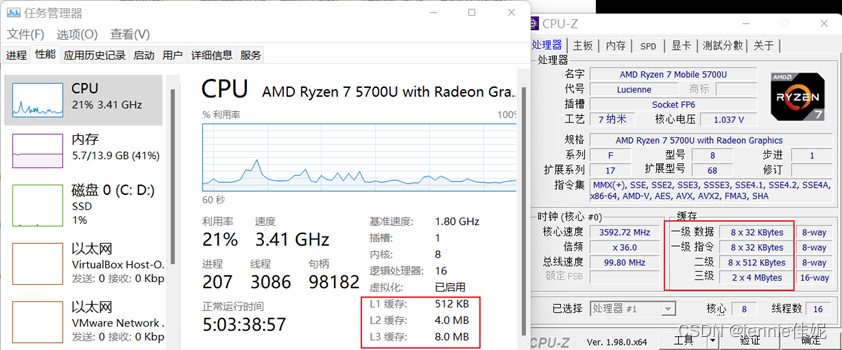
Figure 1 cache层级大小
结论与心得体会
实验中遇到的相关问题:
main()函数参数(int argc,char *argv[])
argc为参数个数,argv[0]为运行目录路径和程序名,agrv[1]==argc,其他依次为参数值。命令行运行程序时后面跟上参数值可实现传参。
在本次实验中,我尝试运用cache的知识进行代码优化,同时尝试编程实现真实x86机器cache的测量,加深了我对cache运行原理的理解。我意识到在代码编写时要尽量考虑cache的优化,按行优先存储可以相应的提高性能。
同时为了实现测量x86机器上(非虚拟机)的Cache 层次结构和容量,我先申请不同的内存块依次测试他们大数据存取时的耗时,从而推测出不同层级cache的大致大小。在进一步通过间隔取数推测出cacheline的大致大小。