CPU三级缓存机制
由于CPU的速度远远大于内存速度,为了提高CPU的使用效率,设计者在CPU与内存之间添加CPU Cache以提高CPU的计算效率 & 吞吐率,CPU缓存分为三层:L1,L2,L3。级别越小越接近CPU, 所以速度也更快, 同时也代表着容量越小。CPU获取数据回依次从L1,L2,L3中查找,如果都找不到则会直接向内存查找。

在Linux里使用 getconf -a | grep CACHE 查看CPU Cache容量,目前主流的CPU Cache的Cache Line大小都是64Bytes。

ICACHE(Instruction Cache):指令高速缓冲处理器,存储微处理器的指令;
DCACHE(Data Cache):数据高速缓冲处理器
这里附上CPU架构图,摘自何登成的CPU Cache And Memory Ordering
缓存行
CPU缓存系统中是以缓存行(cache line)为单位存储的。一个缓存行可以存储多个变量(存满当前缓存行的字节数。当CPU需要访问一个变量时,如果Cache未命中,直接从内存中获取该变量所在的缓存行,并加载到L1中。
MESI协议
在MESI协议中,每个Cache line有4个状态,可用2个bit表示,分别是:
M(Modified):这行数据有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中;
E(Exclusive):这行数据有效,数据和内存中的数据一致,数据只存在于本Cache中;
S(Shared):这行数据有效,数据和内存中的数据一致,数据存在于很多Cache中;
I(Invalid):这行数据无效。
如下图所示,core 1 & core2 都加载内存地址为 00000 -- 00040 X=3 Y=4 的一个缓存行,状态均为S,当Core 2修改Y=5,因为该缓存行存在于多个Cache,故Core 2中状态=Modified,Core1中状态=Invalid,此时Core1若读取X,也需要从内存中重新加载该缓存行。可以看出,该缓存行中任意一个变量的修改,都会导致该缓存行失效,造成重新从内存中读取。这里引入“伪共享”:在多线程情况下,如果需要修改“共享同一个缓存行的变量”,就会无意中影响彼此的性能。

在多线程情景下,线程1修改X,线程2修改Y,根据MESI,执行顺序为:
-
Thread1 update X = 10,修改Status=M,通知其他Cache 修改Status=I;
-
Thread2 更新 Y时,发现Status = I,告之Thread1把脏数据X=10写入内存中,Status = I;
-
Thread2读取Cache Line,并置Status=E,修改Y=5;修改完毕后,Status=M;
多个线程操作在同一Cache Line上的不同数据,相互竞争同一Cache Line,导致线程彼此牵制影响,变成了串行程序,降低了并发性。
“伪共享”解决方法
Java 7的缓存填充
public class Data{
public long p1,p2,p3,p4,p5,p6,p7;//防止与前一个对象产生伪共享
public long X;
public long p1,p2,p3,p4,p5,p6,p7;//防止不相关变量伪共享;
public long Y;
public long p1,p2,p3,p4,p5,p6,p7;//防止与下一个对象产生伪共享
}
duration = 5,193,686,355 ns//withh padding
duration = 36,718,572,233 ns//no padding在内存中形成的缓存行如下图所示,X Y 被隔离在了不同的缓存行,多线程更新X时,仅仅会触发X所在Cache Line 2失效,对Cache Line 3没有影响。
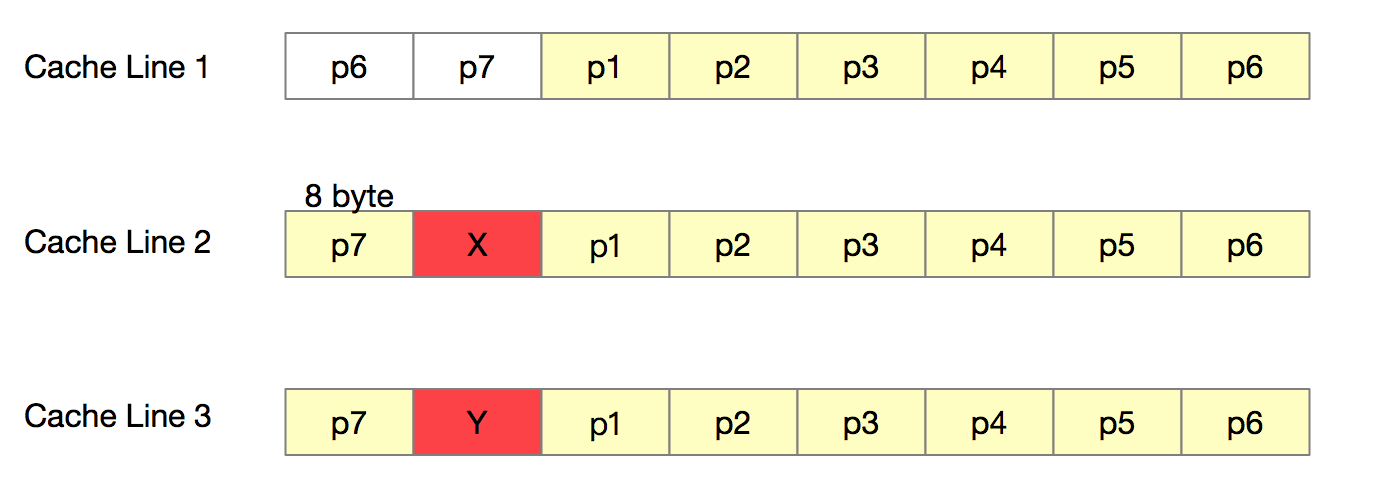
缓存填充在Disruptor的RingBuffer有使用。

Java8的缓存填充
Java8中已经提供了官方的解决方案,Java8中新增了一个注解:@sun.misc.Contended。加上这个注解的类会自动补齐缓存行,需要注意的是此注解默认是无效的,需要在jvm启动时设置-XX:-RestrictContended才会生效。
public class Data{
@sun.misc.Contended
public long X;
@sun.misc.Contended
public long Y;
}
代码引用:https://www.atatech.org/articles/64272
package com;
import sun.misc.Contended;
/**
* Created by xiude on 2018/2/11.
*/
public final class FalseSharing implements Runnable {
private final static int NUM_THREADS = 4; // change
private final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
private static VolatileLong[] longs = new VolatileLong[NUM_THREADS];
static {
for (int i = 0; i < longs.length; i++) {
longs[i] = new VolatileLong();
}
}
public FalseSharing(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
final long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() - start));
}
private static void runTest() throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = i;
}
}
public final static class VolatileLong {
@Contended
public volatile long value = 0L;
//public long p1, p2, p3, p4, p5, p6;
}
}
duration = 5,546,751,378 ns
使用缓存行的场景
缓存行非64字节宽的处理器。如P6系列&奔腾,它们的L1 L2是32byte
共享变量不会被频繁写:使用追加字节的方式导致处理器要读取更多的数据到缓存中,占空间+读取追加字节耗费更多时间,如果共享变量不被频繁写,被锁住的机会也小,没必要使用缓存行。
PS:如何查看一个对象的大小
JOL 工具http://central.maven.org/maven2/org/openjdk/jol/jol-cli/
public class Main {
public long p1,p2,p3,p4,p5,p6;
public volatile long id = 0L;
}执行命令:java -XX:-UseCompressedOops -jar jol-cli-0.9-full.jar internals -cp . Main

参考:http://blog.csdn.net/qq_27680317/article/details/78486220