数据可视化实验报告
1.项目背景
1.1项目概述
本项目拟对movie.csv数据进行可视化
1.2数据字段说明
id——序号
movieId——电影号
title——电影名
cover——图片网址
rate——评分
director——导演
composer——编剧
actor——演员
category——类型
district——地区
language——语言
showtime——上演时间
length——时长
2.提出问题
电影类型与平均评分之间有什么关系、2000年以来评分前十的电影是什么、2010-2015年电影类型产量前五有什么变化?
3.理解数据
3.1采集数据
数据来源:movie.csv
3.2导入数据
根据提出的问题,确定了对csv文件的数据获取。然后通过pandas操作读取csv文件和 usecols导入指定列的数据。
1.

2.

3.

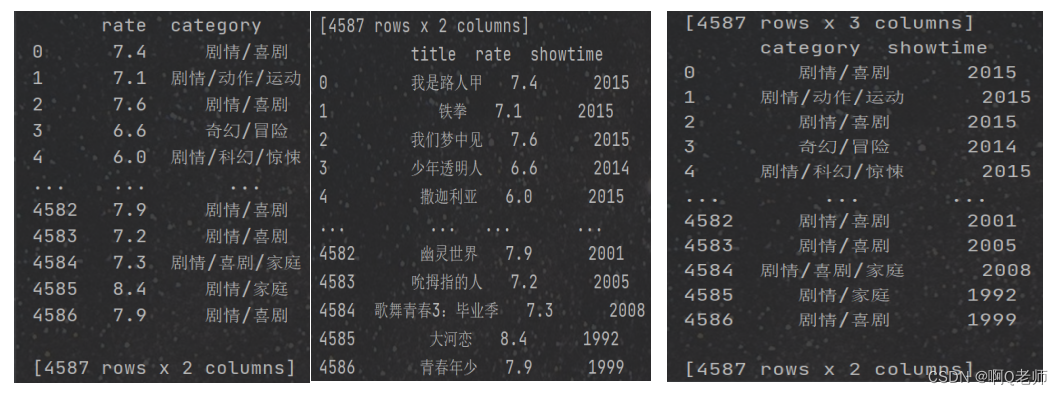
3.3查看数据集信息
如图1.2.3:
4.数据清洗
4.1数据预处理
4.1.1异常数据处理
由于category列数据存在部分为空值,先对其进行以“类型的数据缺失”填充处理。

4.2特征工程
4.2.1特征提取
1.电影类型与平均评分之间有什么关系?
由于category数据每一个单元格上可能存在多种类型,所以对其先按“/”拆分,并将结果转换成DataFrame;拆分后,再以列的形式进行输出;行列转换后,索引需要对其进行重置;最后,数据处理完毕,将new_category的列替换成category列。第二步,获取每种类型的平均评分,将其命名为Average_rate拼接在表中;获取每种电影类型的总次数,将其命名为Count_category拼接在表中;同时进行对类型列的数据去重和以平均评分进行从高到低排序。第三步,单独获取类型、平均评分、类型次数以列表的形式输出。
结果如图:

2.2000年以来评分前十的电影是什么?
首先对上演时间列进行大于2000年的条件筛选;再以评分从高到低进行排序,并且获取前十行数据;然后再生成‘rank’作为名次一列的数据;最后将数据以列表形式输出。
结果如图:

3.2010-2015年电影类型产量前五有什么变化?
首先进行按2010-2015遍历,然后按上演时间列的数据进行条件筛选,最后对类型列同第一题的方式进行处理。
结果如图:
5.数据可视化
5.1 电影类型与平均评分的关系
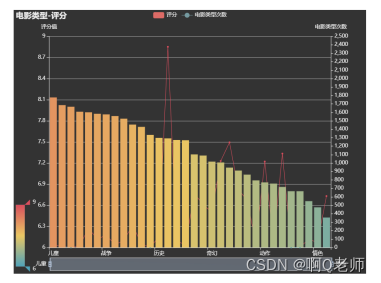
Bar-Mixed_bar_and_line图:
该图展示了电影的类型平均评分从左往右依次降低,而儿童类型的平均评分最高,恐怖类型最低;剧情次数最多,共2376次,荒诞、惊粟与悬念次数最低,只有1次。
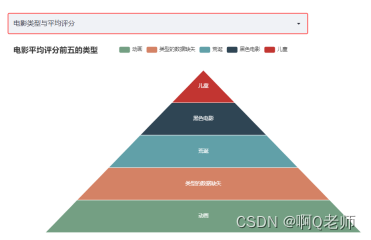
Funnel-Funnel_chart图:
该图通过上图的信息再简单提取出电影平均分前五的电影类型,分别为儿童、黑色电影、荒诞、类型的数据缺失(该类型是对空值的填充)、动画。
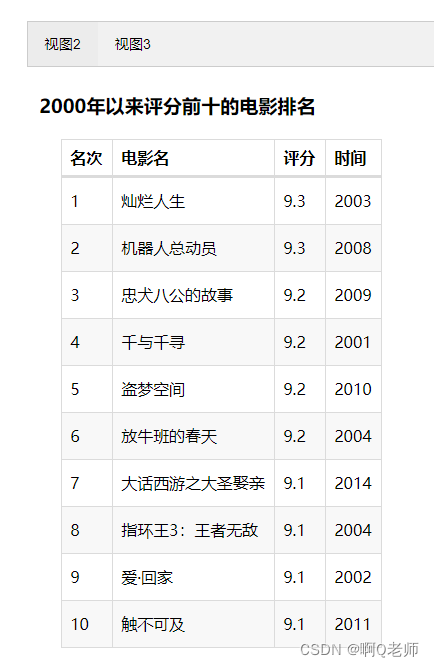
5.2 2000年以来评分前十的电影
Table-Table_base图:
该图展示了2000年以来评分前十的电影排名,其中最高电影评分为9.3,其电影名分别为灿烂人生、机器人总动员,上演时间分别为2003、2008。
5.3 2010-2015年电影类型产量变化
Timeline-Timeline_bar_reversal图:
该图展示了2010年至2015年的电影类型前五产量的动态变化,其中类型产量从上到下依次降低。