目录
一.单词搜索
1.对应letecode链接:
2.题目描述:

3.解题思路:
1.在二维字符网格中枚举每个单词的起点。
2.从该起点出发向四周搜索单词
word,并记录此时枚举到单词word的第index个位置 ( index从0开始)。3.在往四个方向递归搜索时先将当前位置的字符记录下来,并将当前位置置为0,往四个方向递归寻找递归完毕后将原来的字符恢复返回结果
4.直到枚举到单词
word的最后一个字母返回ture,否则返回false
4.递归终止条件:
1.当前位置已经越界了即(row,col)位置是非法位置。
2.当前位置的字符为0,说明之前已经被访问过了.
3.当前位置字符和我们要寻找的字符串中的字符不匹配.
4.匹配的字符串已经到了结尾位置说明匹配成功
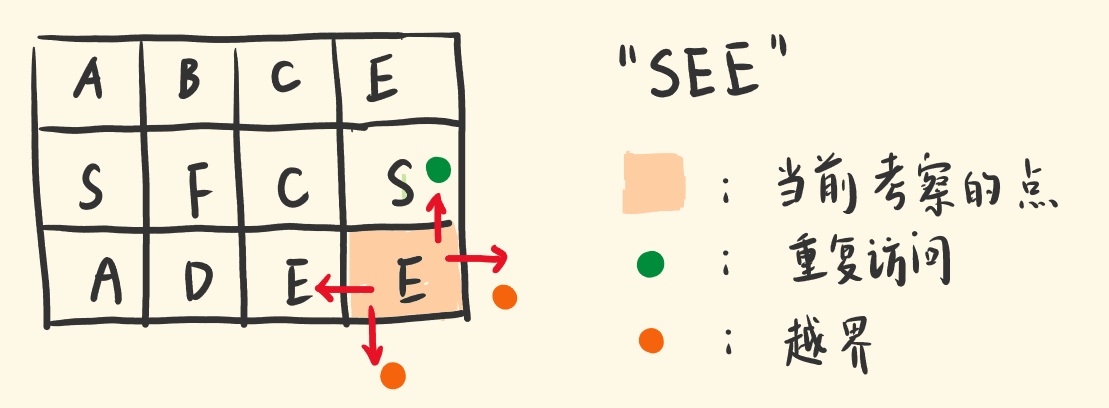
下面举一个下例子:
以"SEE"为例,首先要选起点:遍历矩阵,找到起点S。起点可能不止一个,基于其中一个S,看看能否找出剩下的"EE"路径。下一个字符E有四个可选点:当前点的上、下、左、右。逐个尝试每一种选择。基于当前选择,为下一个字符选点,又有四种选择。每到一个点做的事情是一样的。DFS 往下选点,构建路径。当发现某个选择不对,不用继续选下去了,结束当前递归,考察别的选择。
判断当前选择的点,本身是不是一个错的点。剩下的字符能否找到路径,交给递归子调用去做。如果当前点是错的,不用往下递归了,返回false。否则继续递归四个方向,为剩下的字符选点。那么,哪些情况说明这是一个错的点:当前的点,越出矩阵边界。当前的点,之前访问过,不满足「同一个单元格内的字母不允许被重复使用」。当前的点,不是目标点,比如你想找 E,却来到了 D。
保存访问过的位置的字符并将其置为0.下次再遇到直接就返回0.有的选点是错的,选它就构建不出目标路径,不能继续选。要撤销这个选择,去尝试别的选择。
如果第一个递归调用返回 false,就会执行||后的下一个递归调用这里暗含回溯:当前处在[row,col],选择[row+1,col]继续递归,返回false的话,会撤销[row+1,col]这个选择,回到[row,col],继续选择[row-1,col]递归。只要其中有一个递归调用返回 true,||后的递归就不会执行,即找到解就终止搜索,利用||的短路效应,把枝剪了。如果求出 ret为 false,说明基于当前点不能找到剩下的路径,所以当前递归要返回false,还要在borad矩阵中把当前点恢复原来的字符,让它后续能正常被访问。因为,基于当前路径,选当前点是不对的,但基于别的路径,走到这选它,有可能是对的。当我要找的字符来到了字符串的结尾时返回true。


4.对应代码:
class Solution { public: bool exist(vector<vector<char>>& board, string word) { for(int i=0;i<board.size();i++) { for(int j=0;j<board[0].size();j++) { if(dfs(board,i,j,word,0))//尝试以每个位置开始能不能搞定word { return true; } } } //没有一个位置可以匹配成功 return false; } bool dfs(vector<vector<char>>&arr,int row,int col,const string&str,int index) { if(index==str.size())//这个必须放到最前面已经到了字符串的结尾说明匹配成功 { return true; } if(row<0||col<0||row==arr.size()||col==arr[0].size()) { return false; } if(arr[row][col]!=str[index]||arr[row][col]==0) { return false; } char tmp=arr[row][col];//提前保存下来 arr[row][col]=0;//标记下次遇到就不会重复访问 bool ret=dfs(arr,row+1,col,str,index+1)||dfs(arr,row-1,col,str,index+1) ||dfs(arr,row,col-1,str,index+1)||dfs(arr,row,col+1,str,index+1); arr[row][col]=tmp;//恢复 return ret;//返回结果 } };
二.单词搜索II
1.对应letecode链接:
2.题目描述:

3.解题思路:
方法一:利用上一题的递归函数加set去重,枚举单词表里面的每一个元素看是否能匹配出来但是可能重复收集到答案。所以我们需要定义一个set进行去重。
对应代码:
class Solution { public: vector<string> findWords(vector<vector<char>>& board, vector<string>& words) { vector<string>ans; set<string>HashSet;//进行去重 for(auto x:words) { for(int i=0;i<board.size();i++) { for(int j=0;j<board[0].size();j++) { if(dfs(board,i,j,x,0)&&!HashSet.count(x))//防止重复set的作用 { ans.push_back(x); HashSet.insert(x); } } } } return ans; } bool dfs(vector<vector<char>>&arr,int row,int col,const string&str,int index) { if(index==str.size())//这个必须放到最前面已经到了字符串的结尾说明匹配成功 { return true; } if(row<0||col<0||row==arr.size()||col==arr[0].size()) { return false; } if(arr[row][col]!=str[index]||arr[row][col]==0) { return false; } char tmp=arr[row][col];//提前保存下来 arr[row][col]=0;//标记下次遇到就不会重复访问 bool ret=dfs(arr,row+1,col,str,index+1)||dfs(arr,row-1,col,str,index+1) ||dfs(arr,row,col-1,str,index+1)||dfs(arr,row,col+1,str,index+1); arr[row][col]=tmp;//恢复 return ret;//返回结果 } };
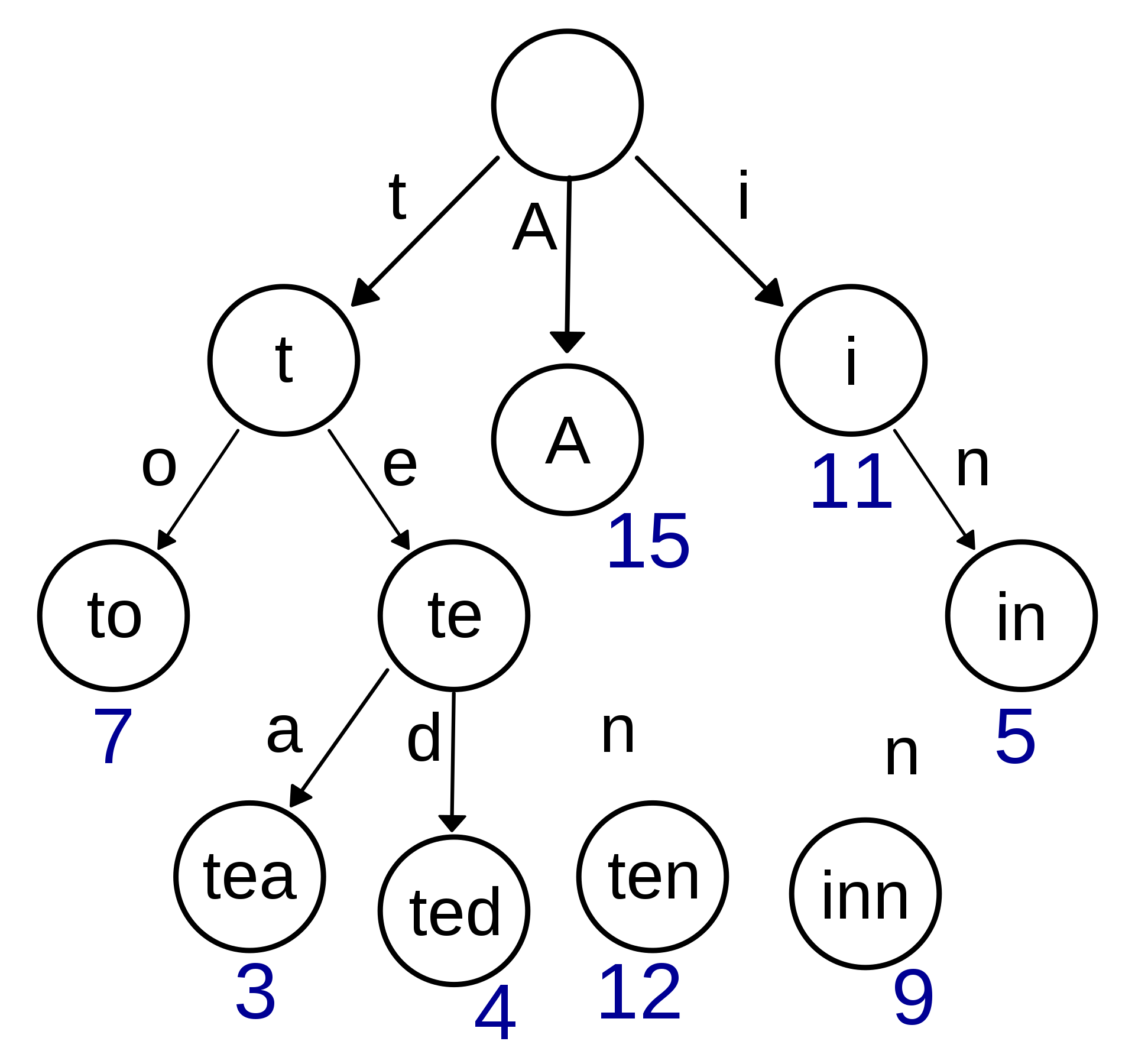
方法二:前缀树加回溯
上面那个代码由于这个递归没有做任何优化导致超时,下面可以通过前缀树进行优化。首先将我们需要查找的单词加入到前缀树当中:
再递归的过程中如果我们发现来到的当前位置没有通往下一级的路说明肯定找不到。具体请看
4.对应代码:
class Solution { public: vector<string>ans; struct TireNode { TireNode() { next.resize(26); end=0; pass=0; } void fillWord(const string&str,TireNode*cur) { cur->pass++;//通过的次数 for(int i=0;i<str.size();i++) { int index=str[i]-'a'; if(cur->next[index]==nullptr) { cur->next[index]=new TireNode; } cur=cur->next[index]; cur->pass++; } cur->end++;//单词的结尾 } ~TireNode() { for(auto x:next) { if(x) { delete x; } } } vector<TireNode*>next; int end; int pass; }; vector<string> findWords(vector<vector<char>>& board, vector<string>& words) { string path;//记录走过的路径 TireNode*root=new TireNode; for(auto &x:words) { root->fillWord(x,root); } for(int i=0;i<board.size();i++) { for(int j=0;j<board[0].size();j++) { process(board,i,j,path,root); } } return ans; } int process(vector<vector<char>>&board,int row,int col,string&path,TireNode*cur) { if(row<0||col<0||row==board.size()||col==board[0].size()||board[row][col]==0) { return 0; } char tmp=board[row][col];//暂时保存当前位置的字符 int index=tmp-'a';//看下一个字符是否存在是否有往下走的必要 if(cur->next[index]==nullptr||cur->pass==0) { return 0; } cur=cur->next[index]; //说明可以蹦上去 //cur->pass==0说明之前已经搜集过了 path+=tmp; int fix=0; //fix代表从(row,col)位置出发搞定了多少个字符串了 board[row][col]=0; if(cur->end>0)//说明已经搞定了 { ans.push_back(path); cur->end--;//结尾单词的数量减减 fix++;//搞定了一个单词 } fix+=process(board,row+1,col,path,cur); fix+=process(board,row-1,col,path,cur); fix+=process(board,row,col-1,path,cur); fix+=process(board,row,col+1,path,cur); path.pop_back();//撤销选择 board[row][col]=tmp;//恢复现场 cur->pass-=fix;//减去搞定的单词数下次再遇到就不会重复计算剪枝 return fix;//返回搞定了几个单词 } };
说明:
1.递归函数的返回值是从该位置递归搞定了多少个单词,方便剪枝。
2.如果没有走向下一级的路了直接返回0,越界也返回0.
3.当遇到字符串的结尾我们将路径加入到答案当中,并将当前节点字符串结尾的数量减减。
或者可以写出这样优化一点点:
struct TriedNode{ TriedNode(){ nexts.resize(26); pass=0; end=0; } vector<TriedNode*>nexts; int pass; int end; void fillWord(TriedNode*node,string &words){ node->pass++; int index=0; for(int i=0;i<words.size();i++){ index=words[i]-'a'; if(node->nexts[index]==nullptr){ node->nexts[index]=new TriedNode; } node=node->nexts[index]; node->pass++; } node->end++; } }; class Solution { public: vector<string> findWords(vector<vector<char>>& board, vector<string>& words) { vector<string>ans; set<string>HashSet;//不允许重复插入 TriedNode *root=new TriedNode; for(auto &x:words){ // auto it=HashSet.find(x); // if(it==HashSet.end()){ root->fillWord(root,x); // } } string path;//沿途走过的字符全部收集起来存到path里面去 for(int row=0;row<board.size();row++){ for(int col=0;col<board[0].size();col++){ //枚举每一个位置 process(board,row,col,path,root,ans); } } return ans; }//从row ,col走出了多少个答案 int process(vector<vector<char>>&board,int row,int col,string& path,TriedNode*root,vector<string>&ans){ char cha=board[row][col]; if(cha==0){//之前已经走过了 return 0; } int index=cha-'a'; if(root->nexts[index]==nullptr||root->nexts[index]->pass==0){ return 0; } //没有回头路且能登上去 root=root->nexts[index]; path+=cha; int fix=0;//从row,col位置出发后序一共搞定多少个答案 //当前我们来到row,col位置,如果决定不往后走了,是不是已经搞定某个字符串 if(root->end>0){ ans.push_back(path); root->end--; fix++; } //从左右上下四个方向尝试 board[row][col]=0; if(row>0){ fix+=process(board,row-1,col,path,root,ans); } if(row<board.size()-1){ fix+=process(board,row+1,col,path,root,ans); } if(col>0){ fix+=process(board,row,col-1,path,root,ans); } if(col<board[0].size()-1){ fix+=process(board,row,col+1,path,root,ans); } board[row][col]=cha; path.pop_back(); root->pass-=fix; return fix; } };