
目录
Ⅰ. 线索二叉树 - THREADED BINARY TREES
Ⅱ. The Heap Abstract Data Type
0x03 大根堆插入操作 - Insertion Into A Max Heap
0x04 大根堆删除操作 - Delete From A Max Heap
Ⅲ. 二叉搜索树 - BINARY SEARCH TREES
Ⅳ. 不相交集合的表示 - SET REPRESENTATION
0x01 合并与查找操作 - Union and Find Operations
Ⅰ. 线索二叉树 - THREADED BINARY TREES
0x00 线索(threads)
具有 个结点的二叉链表共有
个链域,其中
为空链域。
A.J.Perlis 与 C.Thornton 提出一种方法,用用原来的空链域存放指针,指向树中的其他结点。
这种指针就被称为 线索(threads),记 ptr 指向二叉链表中的一个结点,一下是建线索的规则:
① 如果 ptr->leftChild 为空,则存放指向中序遍历排列中该节点的前驱结点。该节点成为 ptr 的 中序前驱(inorder predecessor)。
② 如果 ptr->rightChild 为空,则存放指向中序遍历序列中该结点的后继节点。这个节点称为 ptr 的中序后继(inorder successor)。
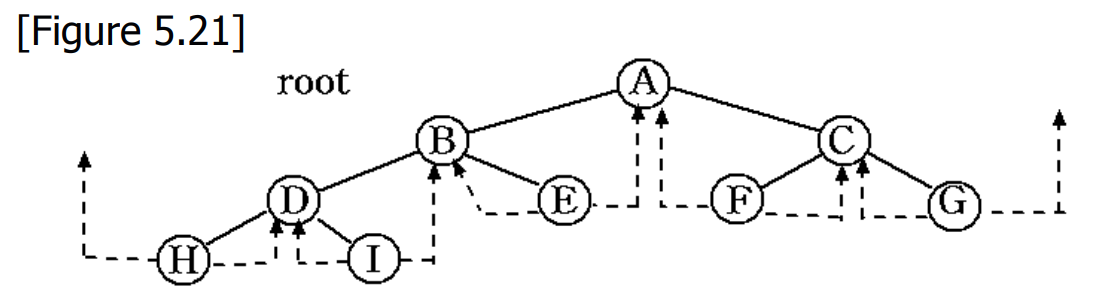
当我们在内存中表示树时,我们必须能够区分线程和普通指针。
这是通过在节点结构中添加两个额外的字段来实现的,即 left_thread 和 right_thread 。
typedef struct threaded_tree* threaded_pointer;
typedef struct threaded_tree {
short int left_thread;
threaded_pointer left_child;
char data;
threaded_pointer right_child;
short int right_thread;
};我们假设所有线程二叉树都有一个头结点。


线程二叉树的无序遍历 确定一个节点的无序继承者。
[Program 5.10] Finding the inorder successor of a node.
threaded_pointer insucc(threaded_pointer tree)
{
/* find the inorder successor of tree
in a threaded binary tree */
threaded_pointer temp;
temp = tree->right_child;
if (!tree->right_thread)
while (!temp->left_thread)
temp = temp->left_child;
return temp;
}为了进行中序遍历,我们反复调用 insucc
[Program 5.11] Inorder traversal of a threaded binary tree.
void tinorder(threaded_pointer tree)
{
/* traverse the threaded binary tree inorder */
threaded_pointer temp = tree;
for (; ; ) {
temp = insucc(temp);
if (temp == tree) break;
printf("%3c", temp->data);
}
}向线程二叉树插入一个节点,假设我们有一个节点,即 parent,它的右子树是空的。我们希望插入child 作为父节点的右子节点。

要做到这一点,我们必须:
① 将 parent-> right_thread 改为 FALSE
② 将 child->left_thread 和 child->right_thread 改为 TRUE
③ 将 child->left_child 改为指向 parent
④ 将 child->right_child 改为 parent->right_child
⑤ 将 parent->right_child 改为指向 child
对于 parent 具有非空右子树的情况:

处理这两种情况的 C 代码如下:
[Program 5.12] : Right insertion in a threaded binary tree
void insert_right(threaded_pointer parent, threaded_pointer child) {
/* insert child as the right child of parent in a threaded binary tree */
threaded_pointer temp;
child->right_child = parent->right_child;
child->right_thread = parent->right_thread;
child->left_child = parent;
child->left_thread = TRUE;
parent->right_child = child;
parent->right_thread = FALSE;
if (!child->right_thread) {
temp = insucc(child);
temp->left_child = child;
}
}Ⅱ. The Heap Abstract Data Type
0x00 大根堆定义
A max tree is a tree in which the key value in each node is no smaller than the key values in its children (if any). A max heap is a complete binary tree that is also a max tree.
大根树中每个结点的关键字都不小于孩子结点(如果有的话)的关键字。大根堆即是完全二叉树又是大根树。
A min tree is a tree in which the key value in each node is no larger than the key values in its children (if any). A min heap is a complete binary tree that is also a min tree.
小根数中每个结点的关键字都不大于孩子节点(如果有的话)的关键字。大根堆即是完全二叉树又是小根树。


值得注意的是,我们将堆表示为一个数组,尽管我们没有使用位置0。
从堆的定义可以看出:
① 最小树的根包含树中最小的键。
② 最大树的根包含树中的最大键。
对最大堆的基本操作:(1) 创建一个空堆 (2) 向堆中插入一个新元素 (3) 从堆中删除最大元素。

0x02 Priority Queues
堆,常用来实现优先级队列。优先级队列的删除操作以队列元素的优先级高低为准。
譬如总是删除优先级最高的元素,或总是删除优先级最低的元素。
优先级队列的插入操作不限制元素的优先级,任何时刻任何优先级的元素都可以入列。
实现优先级队列:堆被用来作为优先级队列的有效实现。

0x03 大根堆插入操作 - Insertion Into A Max Heap
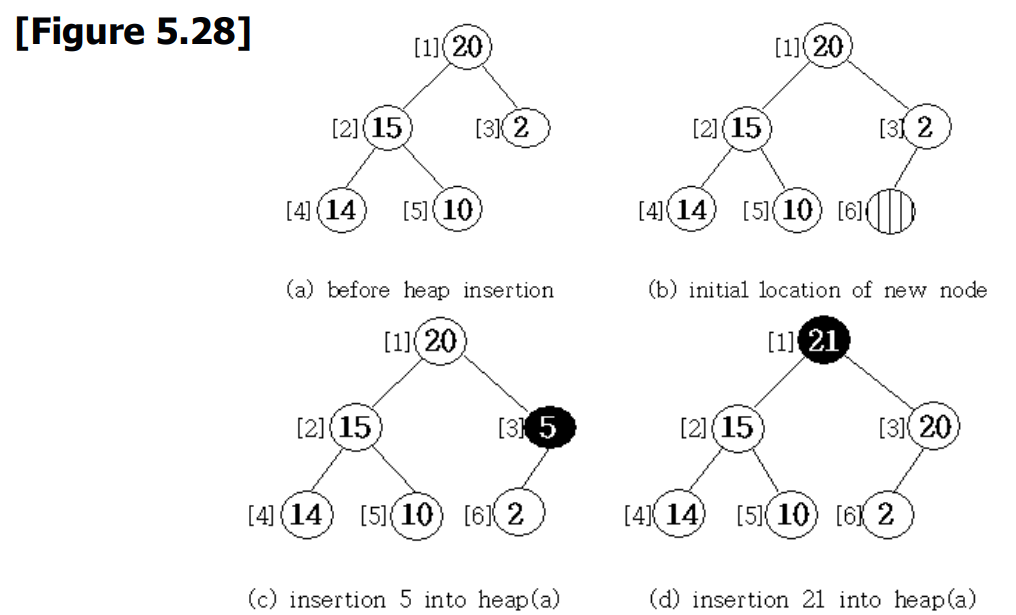
#define MAX_ELEMENTS 200 /*maximum heap size+1 */
#define HEAP_FULL(n) (n == MAX_ELEMENTS-1)
#define HEAP_EMPTY(n) (!n)
typedef struct {
int key;
/* other fields */
} element;
element heap[MAX_ELEMENTS];
int n = 0;
我们可以通过以下步骤在一个有 个元素的堆中插入一个新元素。
① 将元素放在新的节点(即第 个位置)
② 沿新节点到根的路径移动,如果当前节点的元素比其父节点的元素大,则将它们互换并重复。
[Program 5.13] Insertion into a max heap (大根堆插入操作)
void insert_max_heap(element item, int* n)
{
/* insert item into a max heap of current size *n */
int i;
if (HEAP_FULL(*n)) {
fprintf(stderr, "The heap is full. \n");
exit(1);
}
i = ++(*n);
while ((i != 1) && (item.key > heap[i / 2].key)) {
heap[i] = heap[i / 2];
i /= 2;
}
heap[i] = item;
}
对于 insert_max_heap 的分析:
该函数首先检查是否有一个完整的堆。 如果没有,则将 设置为新堆的大小(
)。
然后通过使用while循环确定项目在堆中的正确位置。
这个 while 循环被迭代了 次,因此时间复杂度为
。
0x04 大根堆删除操作 - Delete From A Max Heap
当我们从一个最大堆中删除一个元素时,我们总是从堆的根部取走它。
如果堆有 个元素,在删除根部的元素后,堆必须成为一个完整的二叉树,少一个节点,即(
)个元素。。
我们把元素放在根节点的位置 ,为了建立堆,我们向下移动堆,比较父节点和它的子节点,交换失序的元素,直到重新建立堆为止。
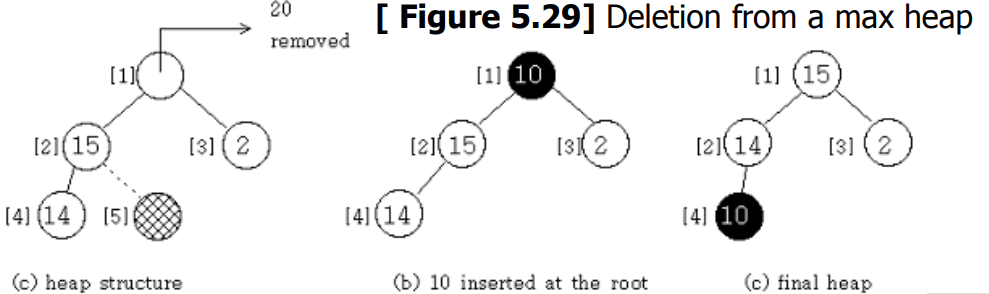
[Program 5.14] : Deletion from a max_heap - 大根堆删除操作
element delete_max_heap(int* n)
{
/* delete element with the highest key from the heap */
int parent, child;
element item, temp;
if (HEAP_EMPTY(*n)) {
fprintf(stderr, "The heap is empty");
exit(1);
}
/* save value of the element with the largest key */
item = heap[1];
/* use last element in heap to adjust heap */
temp = heap[(*n)--];
parent = 1; child = 2;
while (child <= *n) {
/* find the larger child of the current parent */
if ((child < *n) && (heap[child].key < heap[child + 1].key))
child++;
if (temp.key >= heap[child].key) break;
/* move to the next lower level */
heap[parent] = heap[child];
parent = child;
child *= 2;
}
heap[parent] = temp;
return item;
}对于 delete_max_heap 的分析:
函数 delete_max_heap 的操作是向下移动堆,比较和交换父节点和子节点,直到重新建立堆的定义。由于一个有 个元素的堆的高度为
![]() ,while 循环了
,while 循环了 次。因此时间复杂度为
.
Ⅲ. 二叉搜索树 - BINARY SEARCH TREES
0x00 介绍
虽然堆很适合于需要优先级队列的应用,但它并不适合于我们删除和搜索任意元素的应用。 二叉搜索树在操作、插入、删除和搜索任意元素方面的性能都很不错。
0x01 定义
二叉搜索树是一棵二叉树。它可能是空的。 如果它不是空的,它满足以下属性:
① 每个元素都有一个键,没有两个元素有相同的键,也就是说,键是唯一的。
② 非空的左子树中的键必须比根中的键小。
③ 非空的右子树中的键必须比根中的键大。
④ 左和右子树也是二叉搜索树
思考:如果我们按顺序遍历二叉搜索树,并按访问的顺序打印节点的数据,
那么打印的数据顺序是什么?
0x02 搜索一颗二叉搜索树
[Program 5.15] : Recursive search for a binary search tree
tree_pointer search(tree_pointer root, int key)
{
/* return a pointer to the node that contains key.
If there is no such node, return NULL. */
if (!root) return NULL;
if (key == root->data) return root;
if (key < root->data)
return search(root->left_child, key);
return search(root->right_child, key);
}[Program 5.16] Iterative search for a binary search tree
tree_pointer search2(tree_pointer tree, int key)
{
/* return a pointer to the node that contains key.
If there is no such node, return NULL. */
while (tree) {
if (key == tree->data) return tree;
if (key < tree->data)
tree = tree->left_child;
else
tree = tree->right_child;
}
return NULL;
}分析:设 是二叉搜索树的高度,那么 search 和 search2 的时间复杂性都是
。 然而,搜索有一个额外的堆栈空间要求,是
。
0x03 二叉搜索树的插入
要插入一个新的元素,键 。
首先,我们通过搜索树来验证该键是否与现有元素不同。
如果搜索不成功,我们就在搜索终止的地方插入该元素。
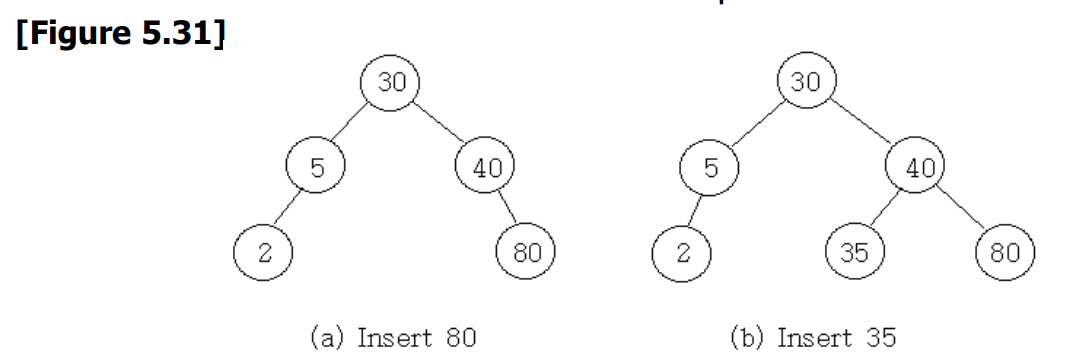
[Program 5.17] : Inserting an element into a binary search tree
void insert_node(tree_pointer* node, int num)
{
/* If num is in the tree pointed at by node do nothing;
otherwise add a new node with data = num */
tree_pointer ptr, temp = modified_search(*node, num);
if (temp || !(*node)) {
/* num is not in the tree */
ptr = (tree_pointer)malloc(sizeof(node));
if (IS_FULL(ptr)) {
fprintf(stderr, "The memory is full");
exit(1);
}
ptr->data = num;
ptr->left_child = ptr->right_child = NULL;
if (*node) /* insert as child of temp */
if (num < temp->data)
temp->left_child = ptr;
else temp->right_child = ptr;
else *node = ptr;
}
}modified_search 在二叉搜索树 *node 中搜索键 num。 如果树是空的,或者num被提出,它返回NULL。 否则,它返回一个指向搜索过程中遇到的树的最后一个节点的指针。
分析 insert_node:
设 为二叉搜索树的高度。 由于搜索需要
时间,算法的其余部分需要 Θ(1) 时间。 所以insert_node需要的总体时间是
.
0x04 二叉搜索树的删除
删除一个叶子节点。
将其父级的相应子字段设置为NULL并释放该节点。
删除有单个子节点的非叶节点:erase 该节点,然后将单个子节点放在被 erase 节点的位置上。
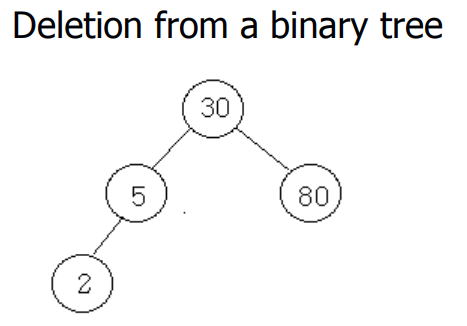
删除有两个子节点的非叶节点:用其左子树中最大的元素或其右子树中最小的元素替换该节点。 然后从子树中删除这个被替换的元素。
注意,子树中最大和最小的元素总是在零度或一度的节点中。
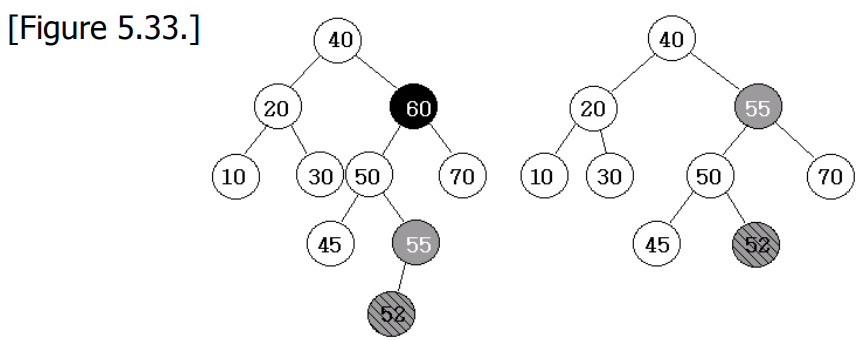
不难看出,删除可以在 时间内进行,其中
是二叉搜索树的高度。
0x05 二叉搜索树的高度
然而,当随机插入和删除时,二叉搜索树的高度平均为 。
最坏情况下高度为 的搜索树被称为平衡搜索树。
Ⅳ. 不相交集合的表示 - SET REPRESENTATION
0x00 引子
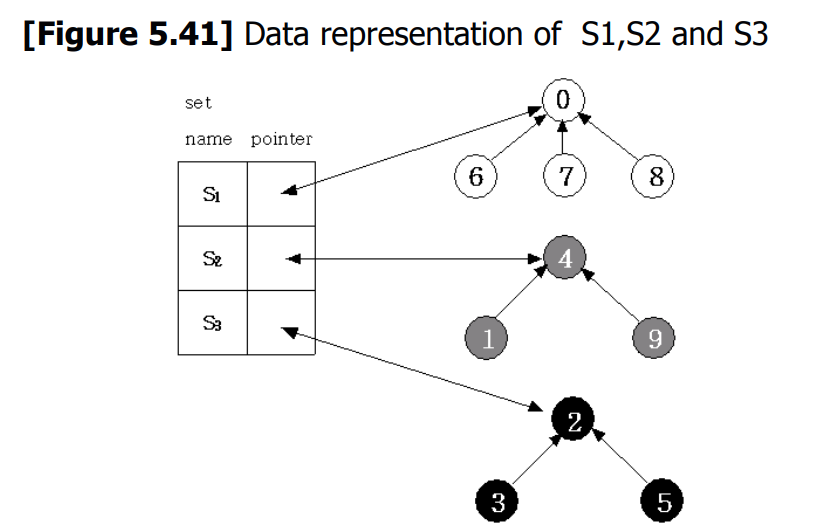
我们研究树在集合表示中的使用。 为了简单起见,我们假设集合的元素是数字 。 我们同时还假设被表示的集合是成对且不相交的。
下图展示的是一个可能的表示方法:

请注意,对于每一个集合来说,节点都是从子集到父集的链接。
对这些集合进行的操作如下:
① 不相交集合的合并。如果我们希望得到两个不相交的集合 和
的合并,用
代替
和
。 ② Find(i). 找到包含元素
的集合
0x01 合并与查找操作 - Union and Find Operations
假设我们希望得到 和
的合并。 我们只需让其中一棵树成为另一棵树的子树。
可以用下图中的任何一种表现形式:
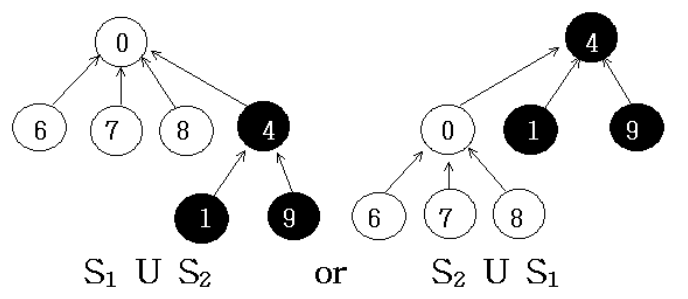
为了实现集合的合并操作,我们只需将其中一个根的父域设置为另一个根。
下图展示了命名这些集合的方式:
为了简化对 union 和 find 算法的讨论,我们将忽略集合的名称,而用代表它们的树的根来识别集合。 由于树中的节点被编号为 0 到 n-1 ,我们可以用节点的编号作为一个索引。

注意,根节点的父节点为 -1
我们可以实现find(i),方法是从 开始跟踪指数,直到父的指数为负数为止。
[Program 5.18] : Initial attempt at union-find functions.
int find(int i)
{
for (; parent[i] >= 0; i = parent[i])
;
return i;
}
void union1(int i, int j)
{
parent[i] = j;
}分析 union1 和 find1:
让我们处理以下的 union-find 操作序列:

这个序列产生了下图的蜕化树: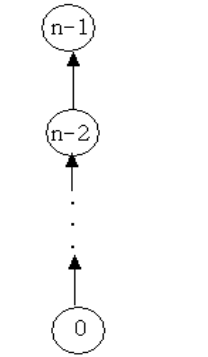
由于 的时间是恒定的,所有的
个联合可以在时间
内处理完毕。
对于每个发现,如果该元素处于第i层,那么找到其根部所需的时间是 。
因此,处理 个发现所需的总时间为:
通过避免退化树的创建,我们可以获得更有效的 union 和 find 的操作实现。
0x02 定义
的加权规则。如果树
中的节点数少于树j中的节点数,则使
成为
的父节点;否则使
成为
的父节点。

为了实现加权规则,我们需要知道每棵树上有多少个节点。 也就是说,我们需要在每棵树的根部维护一个计数字段。 我们可以将根部的父字段中的计数保持为一个负数。
[Program 5.19] : Union operation incorporating the weighting rule.
void union2(int i, int j)
{
/* parent[i] = -count[i] and parent[j] = -count[j] */
int temp = parent[i] + parent[j];
if (parent[i] > parent[j]) {
parent[i] = j; /* make j the new root */
parent[j] = temp;
}
else {
parent[j] = i; /* make i the new root */
parent[i] = temp;
}
}引理:令 是一棵有
个节点的树,作为
的结果而创建,那么
的深度为:
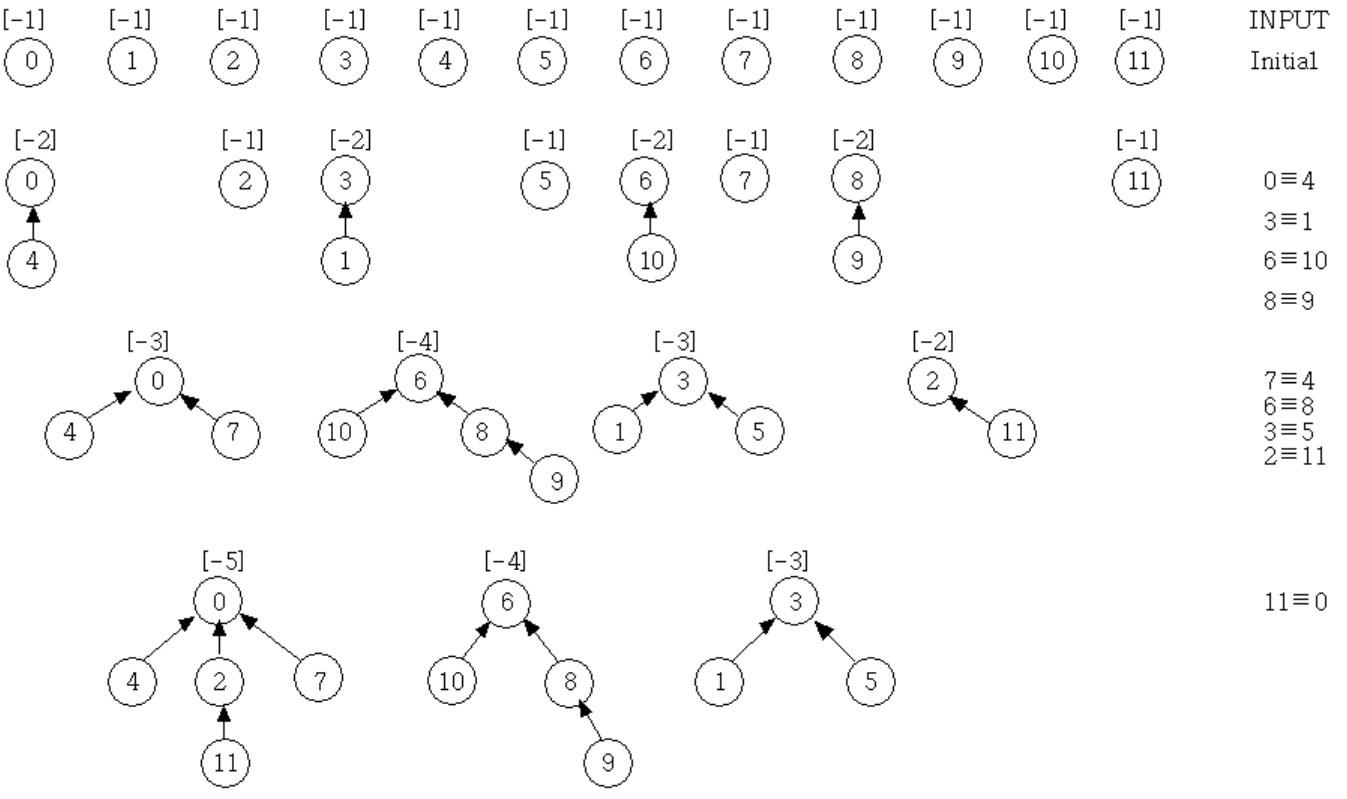
Example 5.1 : 从初始配置开始考虑 union2 在以下联合序列上的行为
union(0, 1) union(2, 3) union(4, 5) union(6, 7) union(0, 2) union(4, 6) union(0, 4)

从这个例子可以明显看出,在一般情况下,如果树有 个节点,深度可以是
作为引理 5.4 的结果,处理一个 元素树中的查找的时间是
如果我们处理 个并集和
个查找操作的混合序列,则时间变为
。
0x03 等价类 - Equivalence Classes
[Figure 5.44] Trees for equivalence example
参考资料
Fundamentals of Data Structures in C