
01 简介
SeaTunnel 原名Waterdrop,自2021年10月12日改名为SeaTunnel。
SeaTunnel是一个非常易于使用的超高性能分布式数据集成平台,支持海量数据的实时同步。它每天可以稳定高效地同步数百亿数据,已在近100家公司的生产中使用。
02 特点
-
易于使用,配置灵活,低代码开发
-
实时流媒体
-
离线多源数据分析
-
高性能、海量数据处理能力
-
模块化和插入式机构,易于扩展
-
支持通过SQL进行数据处理和聚合
-
支持Spark结构化流媒体
-
支持Spark 2.x
这里我们踩了一个坑,因为我们测试的spark环境已经升级到了3.x版本,而目前SeaTunnel只支持2.x,所以要重新部署一个2.x的spark。

03 工作流程
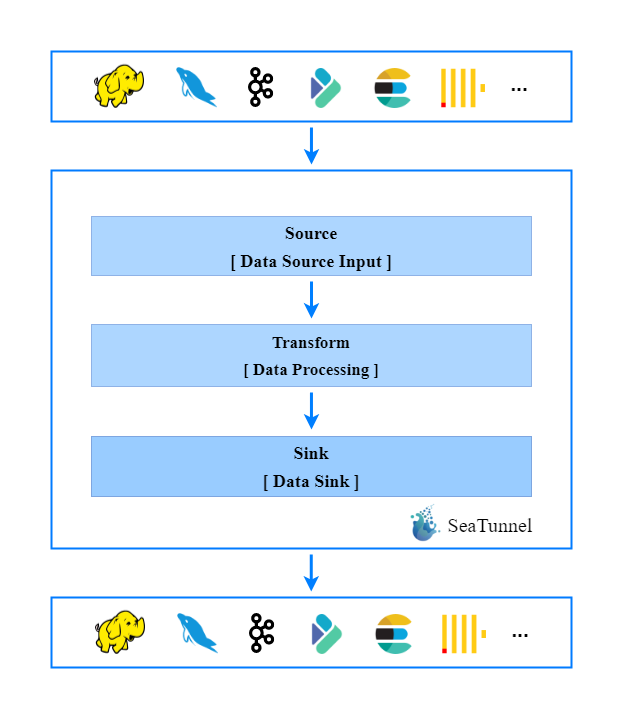
04 安装
安装文档
链接:https://seatunnel.incubator.apache.org/docs/2.1.0/spark/installation
-
环境准备:安装jdk和spark
-
config/seatunnel-env.sh
-
下载安装包
-
解压后编辑 config/seatunnel-env.sh
-
指定必要的环境配置,例如SPARK_HOME(SPARK下载和解压缩后的目录)
测试jdbc-to-jdbc
- 创建新的 config/spark.batch .jdbc.to.jdbc.conf 文件
`env {
# seatunnel defined streaming batch duration in seconds
[spark.app.name](http://spark.app.name) = "SeaTunnel"
spark.executor.instances = 1
spark.executor.cores = 1
spark.executor.memory = "1g"
}
source {
jdbc {
driver = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://0.0.0.0:3306/database?useUnicode=true&characterEncoding=utf8&useSSL=false"
table = "table_name"
result\_table\_name = "result\_table\_name"
user = "root"
password = "password"
}
}
transform {
# split data by specific delimiter
# you can also use other filter plugins, such as sql
# sql {
# sql = "select * from accesslog where request_time > 1000"
# }
# If you would like to get more information about how to configure seatunnel and see full list of filter plugins,
# please go to [https://seatunnel.apache.org/docs/spark/configuration/transform-plugins/Sql](https://seatunnel.apache.org/docs/spark/configuration/transform-plugins/Sql)
}
sink {
# choose stdout output plugin to output data to console
# Console {}
jdbc {
# 这里配置driver参数,否则数据交换不成功
driver = "com.mysql.jdbc.Driver",
saveMode = "update",
url = "jdbc:mysql://ip:3306/database?useUnicode=true&characterEncoding=utf8&useSSL=false",
user = "userName",
password = "***********",
dbTable = "tableName",
customUpdateStmt = "INSERT INTO table (column1, column2, created, modified, yn) values(?, ?, now(), now(), 1) ON DUPLICATE KEY UPDATE column1 = IFNULL(VALUES (column1), column1), column2 = IFNULL(VALUES (column2), column2)"
}
}`
- 启动命令
`./bin/start-seatunnel-spark.sh --master 'yarn' --deploy-mode client --config ./config/spark.batch.jdbc.to.jdbc.conf`
- 踩坑:之前运行时报[driver] as non-empty ,定位发现sink配置里需要设置driver参数
`ERROR Seatunnel:121 - Plugin[org.apache.seatunnel.spark.sink.Jdbc] contains invalid config, error: please specify [driver] as non-empty`

测试jdbc-to-hive
- 创建新的 config/spark.batch .jdbc.to.hive.conf 文件
`env {
# seatunnel defined streaming batch duration in seconds
[spark.app.name](http://spark.app.name) = "SeaTunnel"
spark.executor.instances = 1
spark.executor.cores = 1
spark.executor.memory = "1g"
# 因为sink用到hive源,所以必须进行以下配置
spark.sql.catalogImplementation = "hive"
}
source {
jdbc {
driver = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://0.0.0.0:3306/database?useUnicode=true&characterEncoding=utf8&useSSL=false"
table = "table_name"
result\_table\_name = "result\_table\_name"
user = "root"
password = "password"
}
}
transform {
# split data by specific delimiter
# you can also use other filter plugins, such as sql
# sql {
# sql = "select * from accesslog where request_time > 1000"
# }
# If you would like to get more information about how to configure seatunnel and see full list of filter plugins,
# please go to [https://seatunnel.apache.org/docs/spark/configuration/transform-plugins/Sql](https://seatunnel.apache.org/docs/spark/configuration/transform-plugins/Sql)
}
sink {
Hive {
sql = "insert overwrite table seatunnel.test1 partition(province) select name,age,province from result\_table\_name"
}
}`
- 运行命令
- `./bin/start-seatunnel-spark.sh --master 'yarn' --deploy-mode client --config ./config/spark.batch.jdbc.to.jdbc.conf`
踩坑:一开始运行时报错,定位发现conf文件里没有设置spark.sql.catalogImplementation = “hive”
- 报错内容:
`...... ERROR Seatunnel:191 - Exception StackTrace:org.apache.spark.sql.AnalysisException: Table or view not found: ...... Caused by: org.apache.spark.sql.catalyst.analysis.NoSuchDatabaseException: Database 'seatunnel' not found; ......`
更多踩坑经验,请关注后续更新。
{{o.name}}
{{m.name}}