MATLAB小技巧(31)kmeans聚类
前言
MATLAB进行图像处理相关的学习是非常友好的,可以从零开始,对基础的图像处理都已经有了封装好的许多可直接调用的函数,这个系列文章的话主要就是介绍一些大家在MATLAB中常用一些概念函数进行例程演示!
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是,预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
聚类是一个将数据集中在某些方面相似的数据成员进行分类组织的过程,聚类就是一种发现这种内在结构的技术,聚类技术经常被称为无监督学习。k均值聚类是最著名的划分聚类算法,由于简洁和效率使得他成为所有聚类算法中最广泛使用的。给定一个数据点集合和需要的聚类数目k,k由用户指定,k均值算法根据某个距离函数反复把数据分入k个聚类中。本仿真示例MATLAB版本为MATLAB2015b。
一. MATLAB仿真
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%功能:Kmeans聚类
%环境:Win7,Matlab2015b
%Modi: C.S
%时间:2022-06-28
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%% I. 清空环境变量
clear all
clc
tic
X = [2345 22.133 73.667 21.667 1645.7441
2330 21.6 79.333 21 1693.2693
2315 20.667 87.333 19.667 1754.3945
2300 20.333 91 19 1824.0728
2245 20.233 93 19 1886.6993
2230 20.067 93.333 19 1946.2612
2215 20.067 94 19 2012.9419
2200 19.933 93.667 18.667 2078.9727
2145 20.167 92.667 19.333 2144.7363
2130 23.333 75.333 23.333 2197.4436
2115 26.567 62.667 27.667 2202.8196
2100 27 59.667 27.667 2216.8677
2045 28.033 54 29.333 2235.9443
2030 29.133 47.667 30.333 2235.5813
2015 29.167 46.333 30 2213.2466
2000 29.133 46.667 30 2211.2786
1945 29.333 46.333 30.667 2184.4988
1930 29.5 45.667 30.667 2152.5903
1915 29.833 45 30.667 2149.1938
1900 30.067 44.333 31.333 2135.2549
1845 30.5 46 32.333 2159.0088
1830 31.033 45 33.333 2154.5742
1815 31.633 42 33.667 2149.6626
1800 31.967 40.333 33.333 2153.6826
1745 32.3 39.333 33 2177.1943
1730 32.567 38.333 33.667 2181.7134
1715 32.833 37.333 34.333 2175.1987
1700 33 35.667 33.667 2163.4102
1645 33.1 37 34.333 2148.2231
1630 33.333 36.333 33.667 2144.8501
1615 33.633 35.667 34.667 2120.0862
1600 33.9 35 35 2094.7168
1545 33.967 35.333 35.333 2078.2246
1530 33.733 35.667 34.667 2062.4155
1515 33.667 35.667 35.333 2081.3938
1500 33.867 35 35 2092.5576
1445 33.633 35 34.333 2053.0674
1430 33.267 35.667 34 2067.6699
1415 33.133 35 34.333 2066.2915
1400 33.3 35 34.667 2074.0708
1345 32.6 36.667 33.667 2078.8323
1330 32.267 36 32.333 2055.3105
1315 32.367 36.333 32.667 2069.3018
1300 32.733 34.333 33 2064.3274
1245 32.467 34.667 33 2062.2773
1230 32.3 35 32.667 2062.4373
1215 32.3 34.667 33 2058.9009
1200 32.067 34.667 32.333 2070.9666
1145 31.767 34.333 32 2068.8518
1130 31.367 36 32 2064.728
1115 31.033 36.333 31 2065.0349
1100 30.767 36.667 30.667 2034.1639
1045 30.367 37 30.333 2027.9369
1030 30.1 37.333 30 2013.0757
1015 29.467 37.667 29 1979.8931
1000 28.967 40 28.667 1950.5785
945 28.533 40.667 28.333 1901.5054
930 28.233 39.333 28 1829.9697
915 27.467 42 27.667 1764.4973
900 27.267 42.333 27 1709.8811
845 26.7 45 27 1629.5698
830 26.533 44.667 26.667 1576.8669
815 26.3 44.667 25.667 1523.8842
800 25.833 46 25.667 1452.2449
745 25.267 49.333 24.667 1384.7441
730 24.6 51.333 24.333 1345.5134
715 24.1 56.667 23.333 1294.5331
700 23.5 62 23.667 1259.9128
645 23.133 62.333 22.667 1229.3931
630 22.767 62.667 22.333 1200.9705
615 22.4 64.333 22 1170.6023
600 22.033 64.667 21.667 1131.8568
545 21.867 63.333 21.333 1119.5798
530 21.567 62.333 20.667 1090.9631
515 21.633 62 20.667 1079.8999
500 21.767 60.667 20.667 1068.698
445 21.867 61.667 20.667 1060.152
430 22.033 61 21 1053.1154
415 22.433 59.333 21.667 1055.0146
400 22.7 58 22 1079.9813
345 22.733 57 22 1074.444
330 22.733 58.333 22.667 1084.1436
315 22.7 59.667 22.333 1094.5214
300 22.7 60 22.667 1102.3699
245 22.633 60.667 22.333 1121.6499
230 22.6 61.333 22.333 1131.3728
215 22.667 61.667 22 1145.8096
200 22.7 61 22 1163.0804
145 22.767 61.333 22.333 1183.9659];%导入数据
%调用Kmeans函数
%X N*P的数据矩阵
%Idx N*1的向量,存储的是每个点的聚类标号
%Ctrs K*P的矩阵,存储的是K个聚类质心位置
%SumD 1*K的和向量,存储的是类间所有点与该类质心点距离之和
%D N*K的矩阵,存储的是每个点与所有质心的距离;
%参考链接https://wenku.baidu.com/view/377afe18ff00bed5b9f31da6.html?re=view
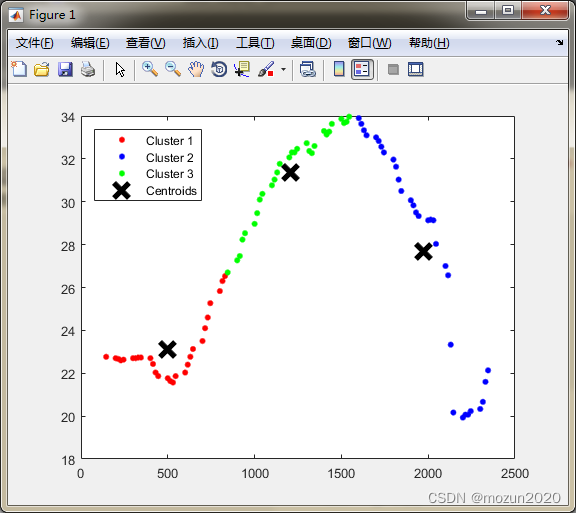
[Idx,Ctrs,SumD,D] = kmeans(X,3,'Replicates',5, 'dist','sqEuclidean');%聚的3类,可以改的
%画出聚类为1的点。X(Idx==1,1),为第一类的样本的第一个坐标;X(Idx==1,2)为第二类的样本的第二个坐标
plot(X(Idx==1,1),X(Idx==1,2),'r.','MarkerSize',14)
hold on
plot(X(Idx==2,1),X(Idx==2,2),'b.','MarkerSize',14)
hold on
plot(X(Idx==3,1),X(Idx==3,2),'g.','MarkerSize',14)
%绘出聚类中心点,kx表示是圆形
plot(Ctrs(:,1),Ctrs(:,2),'kx','MarkerSize',14,'LineWidth',4)
plot(Ctrs(:,1),Ctrs(:,2),'kx','MarkerSize',14,'LineWidth',4)
plot(Ctrs(:,1),Ctrs(:,2),'kx','MarkerSize',14,'LineWidth',4)
legend('Cluster 1','Cluster 2','Cluster 3','Centroids','Location','NW')
resultkmeans=[X,Idx];%原始数据与聚类结果的合并
%找出每个类原始数据样本所在位置
k1=find(Idx==1);
k2=find(Idx==2);
k3=find(Idx==3);
%每个模型所需数据
bp1 =resultkmeans(k1,:);
bp2=resultkmeans(k2,:);
bp3=resultkmeans(k3,:);
toc
二. 仿真结果
三. 小结
K均值是比较常见也是原理比较简单的聚类方法,在自己的专栏《视觉机器学习20讲》中也有相关示例,链接在文末。每天学一个MATLAB小知识,大家一起来学习进步阿!