ELK 中的版本要统一!
1.1 安装jdk
# vim /etc/profile
export JAVA_HOME=/usr/local/jdk1.8.0_171 #jdk安装目录
export JRE_HOME=${
JAVA_HOME}/jre
export CLASSPATH=.:${
JAVA_HOME}/lib:${
JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${
JAVA_HOME}/bin:${
JRE_HOME}/bin
export PATH=$PATH:${
JAVA_PATH}
# source /etc/profile
1.2 安装logstash
每个节点都需要部署一个 logstash。
# 解压logstash
[root@] tar -xxvf logstash-6.6.0.tar.gz
[root@] cd logstash-6.6.0
# 如果jvm 的内存不够,可以开小一点
[root@] cd config
[root@] vim jvm.options
# 新建一个文件 my-logstatsh ,做日志采集, 内容如下
input {
file {
type => "log"
path => ["/apps/svr/server/*/log.file"] # 采集的日志
start_position => "end" # 从上一次的末尾读
ignore_older => 0
codec=> multiline {
# 这行配置是获取java错误堆栈
pattern => "^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}" # springboot 前面的时间,即需要获取两次时间中间
negate => true
auto_flush_interval => 5 # 每5秒中刷新一次,也就是收集错误,最多5秒钟
what => "previous"
}
}
beats {
port => 5044
}
}
output {
if [type] == "log" {
elasticsearch {
hosts => ["http://127.0.0.1:19200"]
index => "logstash-%{+YYYY.MM}" # 每个月建一个索引
#user => es
#password => es2018
}
}
}
[root@]# ../bin/logstash -f my-logstash.conf
1.3 安装 ElasticSearch
ES不能使用root来启动,必须使用普通用于来安装启动
1.服务器准备:centos7.4系统,Jdk1.8 cat /etc/redhat-release。Es6.x
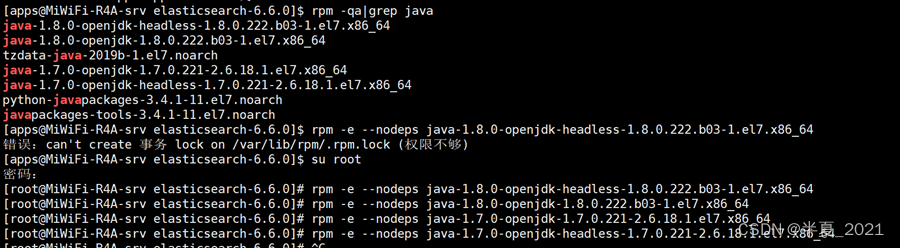
如果是自带的openjdk需要先卸载:
rpm -qa|grep java
rpm -e –nodeps *
2.ElasticSearch安装:本次课程采用的版本为6.6.0 https://elasticsearch.cn/download/
(1)地址:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.6.0.tar.gz
(2)解压: tar -zxvf elasticsearch-6.6.0.tar.gz
(3)修改系统配置:
(a)设置内核参数
vim /etc/sysctl.conf
添加如下内容:
fs.file-max=65536
vm.max_map_count=262144
sysctl -p # 刷新下配置
sysctl -a 查看是否生效
如果不成功的(启动es还是失败,不是所有人都碰得到,好像是在7.6碰到了):
rm -f /sbin/modprobe
ln -s /bin/true /sbin/modprobe
rm -f /sbin/sysctl
ln -s /bin/true /sbin/sysctl
(b)设置资源参数
vi /etc/security/limits.conf
# 添加一下内容:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
*不是写错误,是允许所有用户
(c)修改进程数
vi /etc/security/limits.d/20-nproc.conf
* soft nproc 4096
配置完成后 要关掉链接窗口,重新打开一个
不能用 root 用户启动
需要自己添加一个用户
先创建组, 再创建用户:
1)创建 elasticsearch 用户组
[root@localhost ~]# groupadd elasticsearch
2)创建用户 tlbaiqi 并设置密码
[root@localhost ~]# useradd apps
[root@localhost ~]# passwd apps
3)# 创建es文件夹,
并修改owner为baiqi用户
mkdir -p /usr/local/es
4)用户es 添加到 elasticsearch 用户组
[root@localhost ~]# usermod -G elasticsearch apps
[root@localhost ~]# chown -R apps /usr/local/es/elasticsearch-6.6.0
5)设置sudo权限
#为了让普通用户有更大的操作权限,我们一般都会给普通用户设置sudo权限,方便普通用户的操作
#三台机器使用root用户执行visudo命令然后为es用户添加权限
[root@localhost ~]# visudo
#在root ALL=(ALL) ALL 一行下面
#添加tlbaiqi用户 如下:
apps ALL=(ALL) ALL
#添加成功保存后切换到tlbaiqi用户操作
[root@localhost ~]# su apps
[tlbaiqi@localhost root]$
然后进入到 cofig 目录中
[apps@122] #/usr/local/elasticsearch-6.6.0/config
# 修改ES配置文件 elasticsearch.yml
cluster.name: my-es
node.name: 47.105.188.116 # 可以写自己本机的IP
network.host: 0.0.0.0 # 如果可以访问外网,则可以配置 0.0.0.0
http.port: 19200
transport.tcp.port: 19300
#discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300"]
#discovery.zen.minimum_master_nodes: 3
http.cors.enabled: true
http.cors.allow-origin: "*"
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
# 修改 jvm.options
cd /usr/local/es/elasticsearch-7.6.1/config
vim jvm.options
-Xms2g
-Xmx2g
# 按照自己的内存修改
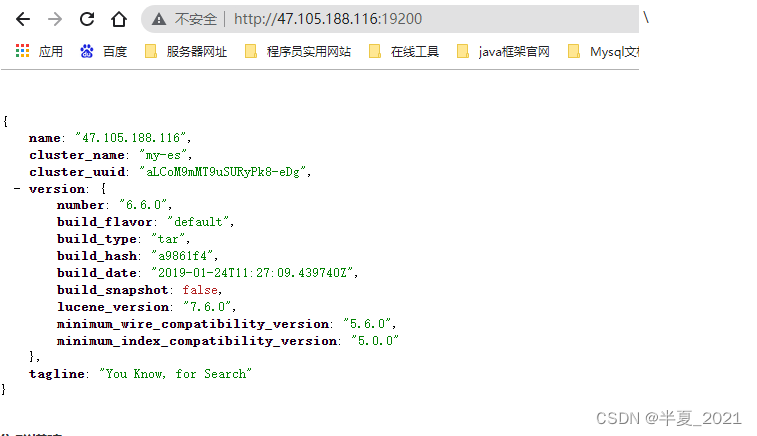
(5 ) 启动 es:./bin/elasticsearch 后台启动加 –d参数
(6) 打开浏览器访问 http://47.105.188.116:19200/?pretty 查看是否能够正常访问,看到以下界面表示启动 ok
集群搭建
怎样部署集群呢?
我们把两个点击分为 elasticsearch-node1 和 elasticsearch-node2 两个节点。
找到对应的配置文件: elasticsearch.yml
默认是 transport.tcp.port 的端口
# 配置所有用来组建集群的机器的IP地址
discovery.zen.ping.unicast.hosts: ["192.168.1.13:9300", "192.168.1.13:9301","192.168.1.13:9302"]
如果是copy进来的,则需要把data目录下的数据删除掉-
1)集群状态
如何快速了解集群的健康状态?
green:每个索引的 primary shard和 replica shard 都是active状态的
yellow:每个索引的 primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态
red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
集群什么情况下处于一个yellow状态
假设现在就一台linux服务器,就启动了一个es进程,相当于就只有一个node。现在es中有一个index,就是kibana自己内置建立的index。由于默认的配置是给每
个index分配1个primary shard和1个replica shard,而且primary shard和replica shard不能在同一台机器上(为了容错)。现在kibana自己建立的index是1个
primary shard和1个replica shard。当前就一个node,所以只有1个primary shard被分配了和启动了,但是一个replica shard没有第二台机器去启动。
测试:启动第二个es进程,就会在es集群中有2个node,然后那1个replica shard就会自动分配过去,然后cluster status就会变成green状态。
2)不同节点介绍
主节点:node.master:true
数据节点: node.data: true
- 客户端节点
当主节点和数据节点配置都设置为false的时候,该节点只能处理路由请求,处理搜索,分发索引操作等,从本质上来说该客户节点表现为智能负载平衡器。
独立的客户端节点在一个比较大的集群中是非常有用的,他协调主节点和数据节点,客户端节点加入集群可以得到集群的状态,根据集群的状态可以直接路由请
求。
2.数据节点
数据节点主要是存储索引数据的节点,主要对文档进行增删改查操作,聚合操作等。数据节点对cpu,内存,io要求较高, 在优化的时候需要监控数据节点的
状态,当资源不够的时候,需要在集群中添加新的节点。
- 主节点
主资格节点的主要职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。稳定的主节点对集
群的健康是非常重要的,默认情况下任何一个集群中的节点都有可能被选为主节点,索引数据和搜索查询等操作会占用大量的cpu,内存,io资源,为了确保一个
集群的稳定,分离主节点和数据节点是一个比较好的选择。
在一个生产集群中我们可以对这些节点的职责进行划分,建议集群中设置3台以上的节点作为master节点,这些节点只负责成为主节点,维护整个集群的状态。再根据数据量设置一批data节点,这些节点只负责存储数据,后期提供建立索引和查询索引的服务,这样的话如果用户请求比较频繁,这些节点的压力也会比较大,所以在集群中建议再设置一批client节点(node.master: false node.data: false),这些节点只负责处理用户请求,实现请求转发,负载均衡等功能
1.4 Head插件的安装
安装node环境
-
下载 : wget https://nodejs.org/download/release/v8.13.0/node-v8.13.0-linux-x64.tar.gz
-
解压 : tar -zxvf node-v8.13.0-linux-x64.tar.gz
-
建立软连接
ln -s /usr/local/node-v8.13.0-linux-x64/bin/node /usr/bin/node ln -s /usr/local/node-v8.13.0-linux-x64/bin/npm /usr/bin/npm执行完后 运行 node -v 和 npm -v 分别就可以看到node 的版本为8.13.0 npm为6.4.1
安装head插件
- git clone git://github.com/mobz/elasticsearch-head.git
如果提示git找不到 则先安装git:yum install -y git
-
cd elasticsearch-head
-
修改npm 源
npm config set registry https://registry.npm.taobao.org 或者 npm install cnpm -g – registry=https://registry.npm.taobao.org
注意: //如果使用了 cnpm 那么就要 用 cnpm install(如果没有建立软连接还需要指定cnpm所在的位置: …/node-v8.13.0/bin/cnpm install )
4. npm install
5. npm run start
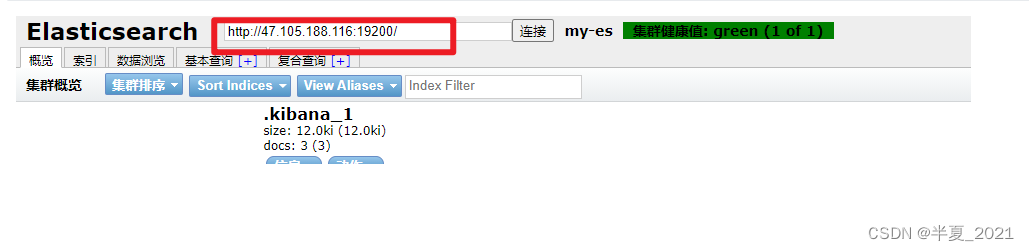
6. 访问: http://ip:9100/
7. 连接 elasticsearch
1.5 filebeat
- 解压
- 安装 tar -zxvf filebeat-6.6.0-linux-x86_64.tar.gz
- cd filebeat-6.6.0-linux-x86_64
- 启动 ./filebeat -e -c filebeat.yml
filebeat 自带的模块 modules 收集日志:
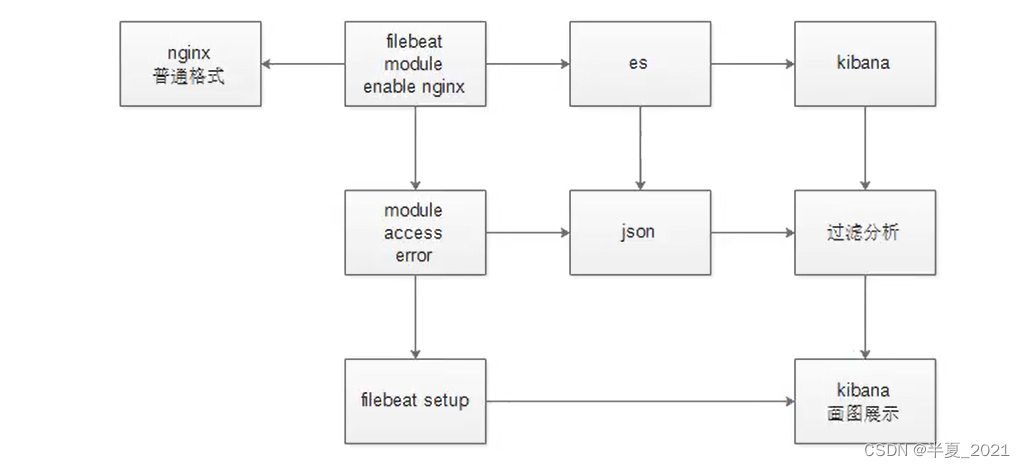
如果nginx日志领导不让改,也就说说,我们不能在 nginx 服务器上修改格式,那么怎么办呢?
- 使用logstash 写匹配规则
- filebeat 自带了解析普通nginx日志的功能
modules 的使用
- 修改 filebeat.yml ,启动module
filebeat.config.modules:
path: ${
path.config}/modules.d/*.yml
reload.enabled: true
reload.period: 10s
output.elasticsearch:
hosts: ["127.0.0.1:19200"]
index: "tomcat-access-%{[beat.version]}-%{+yyyy.MM}"
2.查看开启的模块
# filebeat modules list
Enabled:
Disabled:
apache2
auditd
elasticsearch
haproxy
icinga
iis
kafka
kibana
logstash
mongodb
mysql
nginx
osquery
postgresql
redis
suricata
system
traefik
那么怎么知道有没有启动呢?
可以看到后面的文件名
激活nginx
./filebeat modules enable nginx
-
操作步骤
-
filebeat 配置文件添加模块路径
filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: true reload.period: 10s -
命令行输入激活模块
filebeat modules enable nginx- 修改nginx模块文件 /usr/local/filebeat-6.6.0-linux-x86_64/modules.d/nginx.yml
- module: nginx access: enabled: true var.paths:["/var/log/nginx/access.log] error: enabled: true var.paths:["/var/log/nginx/error.log"]-
修改nginx日志为普通格式
-
安装es2两个插件
# sudo bin/elasticsearch-plugin install ingest-user-agent # sudo bin/elasticsearch-plugin install ingest-geoip- 重启 elasticsearch
- 重启 filebeat
注意: 6.7 之后这两个插件默认集成到了 easticsearch ,不需要单独安装了!
filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: true reload.period: 10s setup.kibana: host: "localhost:5601" output.elasticsearch: hosts: ["http://localhost:19200"] indices: - index: "nginx-access-%{[beat.version]}-%{+yyyy.MM}" when.contains: fileset.name: "access" - index: "nginx-error-%{[beat.version]}-%{+yyyy.MM}" when.contains: fileset.names: "error" setup.template.name: "nginx" setup.template.pattern: "nginx-*" -
1.6 metricbeat
-
下载
-
解压
-
module : metricbeat也有很多module,需要收集哪个module的信息,即启动该module即可,命令与Filebeat类似
## 查module列表
./metricbeat modules list
## 启用module
./metricbeat modules enable 模块名
## 禁用module
./metricbeat modules disable 模块名
4.metricbeat.yml
metricbeat.config.modules:
path: ${
path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
index.codec: best_compression
setup.kibana:
host: "localhost:5601"
setup.dashboards.enabled: true # 开启自动创建仪表盘监控
output.elasticsearch:
hosts: ["localhost:19200"]
5.启动命令 ./metricbeat -e
1.7 安装 kibana
-
解压
-
修改配置
/usr/local/kibana-6.6.0-linux-x86_64/config/kibana.yml
server.port: 5601 # Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values. # The default is 'localhost', which usually means remote machines will not be able to connect. # To allow connections from remote users, set this parameter to a non-loopback address. server.host: "0.0.0.0" # 如果需要对外网访问,则需要配置为 0.0.0.0 elasticsearch.hosts: ["http://localhost:19200"]3.启动
# ./bin/kibana # nohup ./bin/kibana & #后台启动- 访问
http://47.105.188.116:5601/
如何在nginx 中访问kibana 并进行密码访问:
在nginx 下的conf /domains 添加 my.kibana.com 文件,内容如下:
upstream my.kibana.com{ server 172.26.236.53:15601 weight=10 max_fails=2 fail_timeout=30s; } server{ listen 80; server_name my.kibana.com; access_log /apps/svr/nginx/logs/my.kibana.com/my.kibana.com_access.log main; error_log /apps/svr/nginx/logs/my.kibana.com/my.kibana.com_error.log warn; location / { auth_basic "login"; auth_basic_user_file /apps/svr/nginx/conf/htpasswd;#密码生成地址:http://www.matools.com/htpasswd autoindex on; proxy_next_upstream http_500 http_502 http_503 http_504 error timeout invalid_header; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_pass http://my.kibana.com; } }这个文件就是一串加密的密码: 密码生成地址:http://www.matools.com/htpasswd
启动nginx
1.8 安装IK分词器
安装IK分词器。以下为具体安装步骤:
-
下载 Elasticsearch IK 分词器,一定要和elasticsearch 同一个版本
https://github.com/medcl/elasticsearch-analysis-ik/releases
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.6.0/elasticsearch-analysis-ik-6.6.0.zip
-
切换普通用户,并在es的安装目录下 /plugins创建ik
mkdir -p /usr/local/elasticsearch-6.6.0/plugins/ik -
将下面的ik分词器上传并解压到该目录
cd /usr/local/elasticsearch-6.6.0/plugins/ik unzip elasticsearch‐analysis‐ik‐7.6.1.zip -
重启Elasticsearch
测试分词器
1.单子分词器
POST _analyze
{
"analyzer": "standard",
"text":"我爱你中国"
}
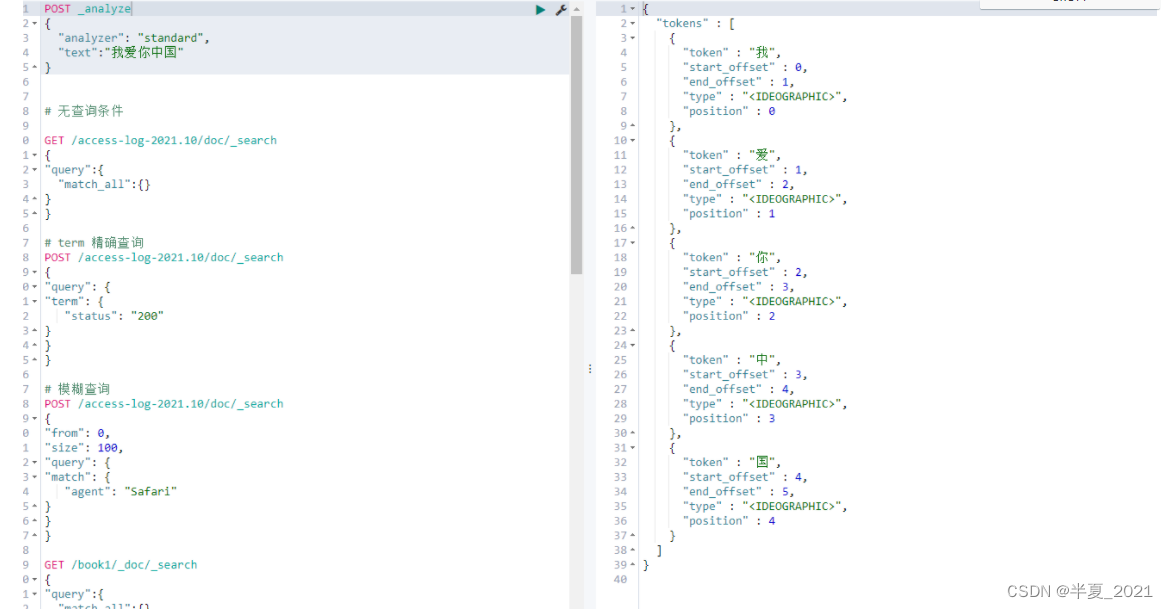
2.最粗粒度的差分 ik_smart
POST _analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}
#ik_smart:会做最粗粒度的拆分
结果:
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
}
]
}
3.将文本做最细粒度的拆分 ik_max_word
POST _analyze
{
"analyzer":"ik_max_word",
"text":"我爱你中国"
}
结果:
{
"tokens" : [
{
"token" : "我爱你",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "爱你",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中国",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
指定IK分词器作为默认的分词器
ES的默认分词设置是standard,这个在中文分词时就比较尴尬了,会单字拆分,比如我搜索关键词“清华大学”,这时候会按“清”,“华”,“大”,“学”去分词,然后搜
出来的都是些“清清的河水”,“中华儿女”,“地大物博”,“学而不思则罔”之类的莫名其妙的结果,这里我们就想把这个分词方式修改一下,于是呢,就想到了ik分词
器,有两种ik_smart和ik_max_word。
ik_smart会将“清华大学”整个分为一个词,而ik_max_word会将“清华大学”分为“清华大学”,“清华”和“大学”,按需选其中之一就可以了。
修改默认分词方法(这里修改school_index索引的默认分词为:ik_max_word):
PUT /school_index
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}