YOLO 系列相关视频和文章看了很多,在 AI 圈应该是响当当的模型,通常都是作为首选模型,特别是对于实时目标检测任务来说。不过看了多么多遍,要是问到细节,我是 confusing,想问自己真的懂了吗? 这也是我从新细读 YOLOv1 paper 后写这篇文章的动力,我们先从 YOLOv1 读起。
突然感觉自己到现在,虽然从事了 2 年左右以目标检测为主工作,可还是一个门外汉。最近在扣一些细节,一些看似基础或者学了没什么意义的知识、例如如何实现反向传播、如何实现自动求导。
YOLOv1
其实 YOLOv1 是在 2016 年提出,感觉距离今天好像已经好久远,不禁感慨今天技术发展如此之快。当然如果在今天,我们要做一个目标检测任务,一定不会选择这个古老模型。不过为了更好地学习当下流行 YOLOv4 和 YOLOv5,还是要提一提这个古老模型,毕竟 YOLO 系列是从 v1 到 v5 这样一路走过来,基本思想还是一脉相承的。
什么是 YOLOv1
YOLOv1 是用于目标检测的网络模型,下面有对什么是目标检测给予解释,这里说的目标检测通常是多目标检测。那么为什么作者起名为 YOLO 呢? YOLO 是 You Only Look Once 的缩写,也就是说模型只需要看一次,就能检测出目标来。为什么这样说呢? 这是因为在 YOLO 之前,用于目标检测的网络是 R-CNN 为主二阶段检测网络,检测分两步走,先图像生成一些候选框,然后在这些候选框基础上进行分类和边界框的回归。这个真是一个不错的名字,好记还有含义。
目标检测
可以在图像中检测出属于事先定义好要检测类别的物体,并且将其位置和大小用框来标注出来呈现给使用者。
相关网络
R-CNN、Fast R-CNN、Faster R-CNN 以及 Mask R-CNN 这些经典 R-CNN 系列,以及同样的一阶段网络 SSD RetinaDet
端到端网络
个人感觉 YOLO 就是实现一个端到端网络,也就是标题中 Unified 和 look once,这为什么作者要强调只看一次,这就是相对当时流行 R-CNN 系列来说的。YOLO 是将目标检测问题转换为回归问题,我们从目标函数来看,不难看出这是一个回归问题。

- 首先将图像缩放到
448×448 大小
- 然后经过卷积神经网络
- 在输出之前做 NMS 也就是非极大值抑制处理
以速度取胜
YOLO 系列自从其出现那一天,给大家印象就是快,要不同时期其他模型明显的快,正因如此,通常都会用于实时检测。那么我们就来看一下 YOLOv1 横空出世时,让人惊叹指标 45 fps 比当时 RCNN 系列要快了将近 15 倍。

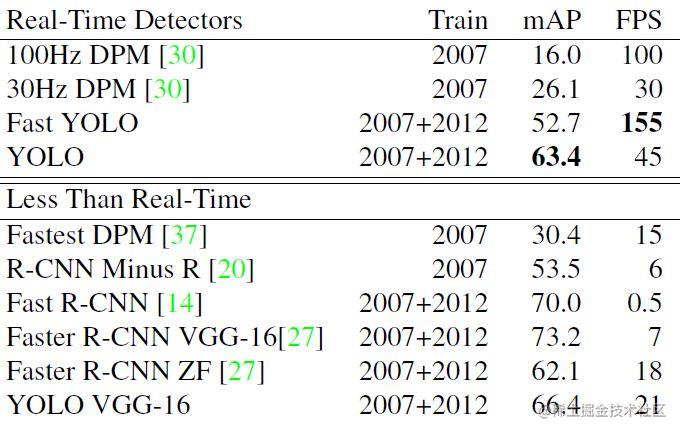
我们从实时检测角度来看,YOLO 可以达到 45 FPS 已经超过实时要求的 30 FPS,而响应的 YOLO VGG-16 最快才只有 21 FPS,如果和 Faster R-CNN ZF[27] 相比,无论从速度还是效果上要远远好于 Faster R-CNN。
YOLOv1 基本思想
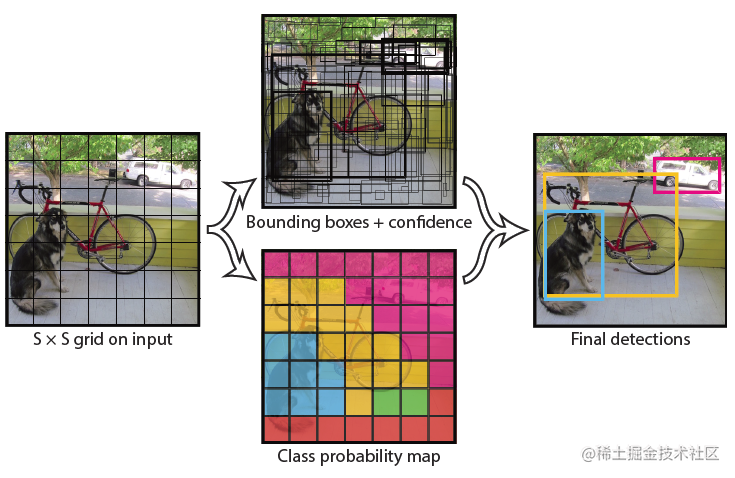
网络架构
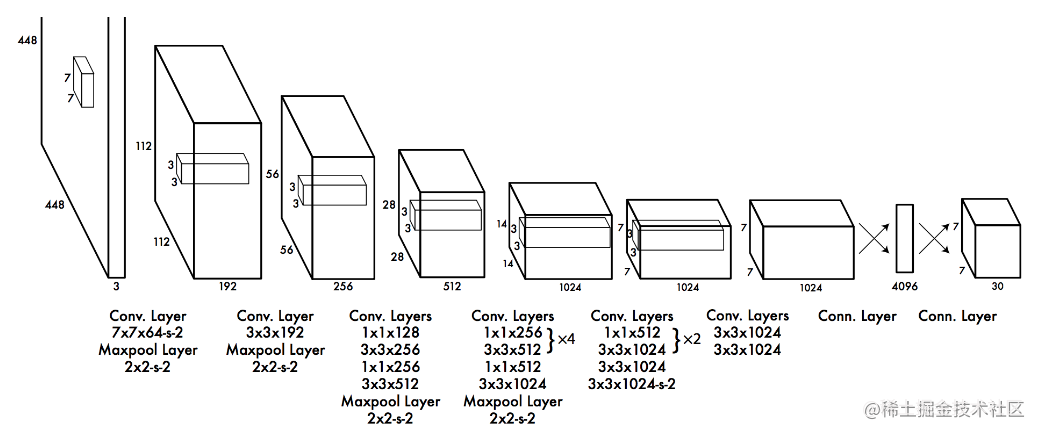
YOLOv1 是在 448x448 ImageNet 上做预训练网络,24 层卷积、最后经过全连接后 reshape 7 x 7 x 30 输出,到现在我还是很好好奇,将输出特征图经过全连接后,如何 reshape 一个持有位置信息和类别信息的 7 x 7 x 30 这个疑惑可能到自己实现一个 YOLOv1 网络时候才能明白。
YOLOv1 输出
网络最终输出结果形状如下,也就是
S×S×(B(1+4)+C) 这样形状,
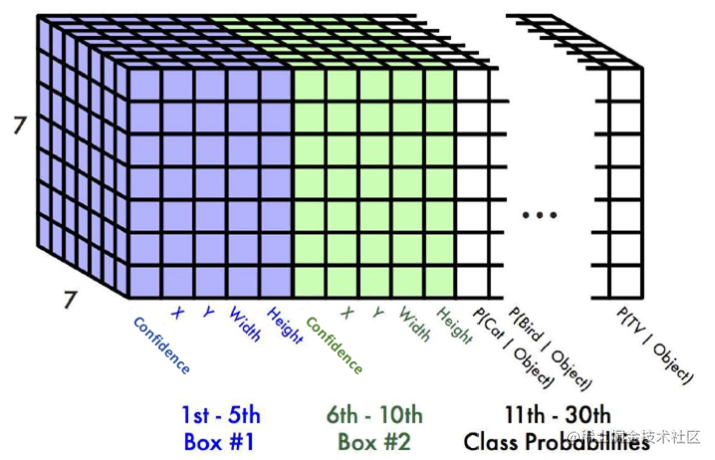
- 先来介绍其中 S 、B 和 C 的含义,S 表示将图像划分网格数量,在论文中作者用的是 7 ,B 是每一个网格提取 bbox 边界框的数量,在论文中给出的是 2,也就是每个网格会预测出 bbox 不过最后我们只会选择一个,也就是 IoU 比较的来计算回归损失等,C 表示类别,如果 COCO 就是 80 类别,要是 VOC 就是 20 个类别。
- 对于置信度进行解释一下,置信度可以表示 P(object) 也就是 bbox 包含目标的概率,在训练过程还会乘以
IoUpredtruth 也就是在是目标情况下,还希望考虑到 IoU 的值。
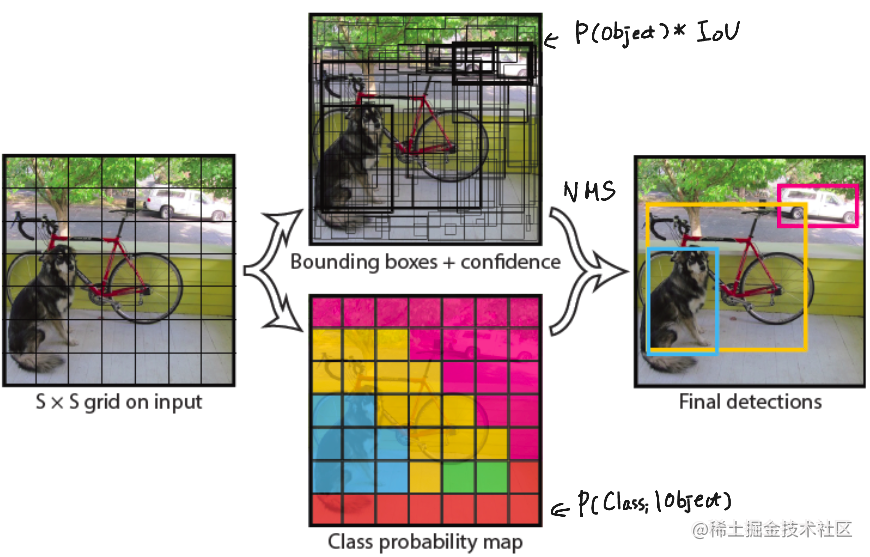
如何将预测宽高结果转换为图像上值
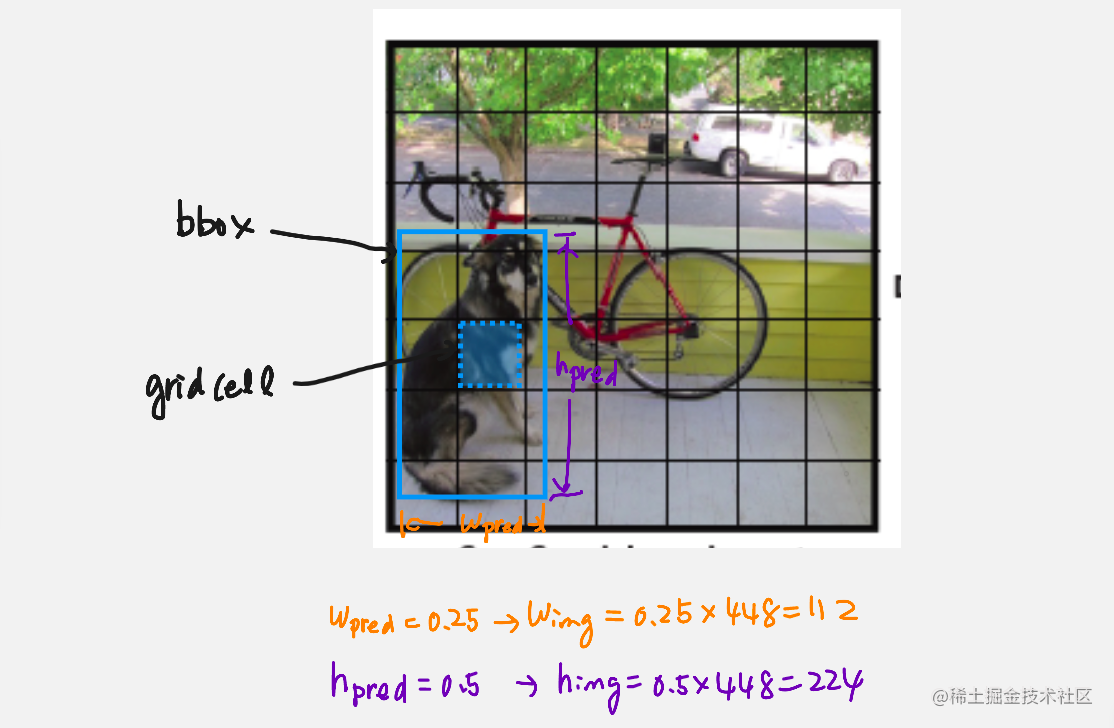
训练
损失函数
设计一个损失函数,也就是给模型设立了一个目标,这个目标用于衡量模型输出是否让我们满意,那么模型主要输出的是 (类别概率分布、置信度(就是网格中可能存在目标的概率)、边界框位置和大小信息(x,y,w,h) 那么模型主要做几件事才能有效地进行目标识别,分别是
- 首先每个网格都给出一个概率就是找到目标可能存(objectness score)
λcoordi=0∑S2j=0∑B1ijobj[(xi−x^i)2+(yi−y^i)2]+λcoordi=0∑S2j=0∑B1ijobj[(wi
−w^i
)2+(hi
−h^i
)2]+i=0∑S2j=0∑B1ijobj(Ci−C^i)2+λnoobji=0∑S2j=0∑B1ijnoobj(Ci−C^i)2+i=0∑S1ijobj(pi(c)−p^i(c))2
边界框回归损失
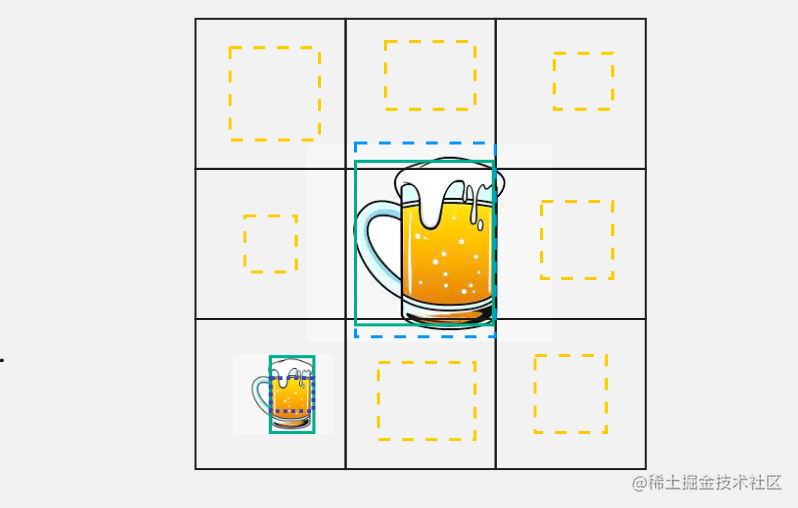
假设我们这里有一个 3x3 网络,也就是 S=3,每一个网格只给出一个预测边界框(bbox),黄色表示表示没有物体的边界框,蓝色表示有目标的边界框,绿色是是目标物体真实的边界框。
λcoordi=0∑S2j=0∑B1ijobj[(xi−x^i)2+(yi−y^i)2+(wi−w^i)2+(hi−h^i)2]
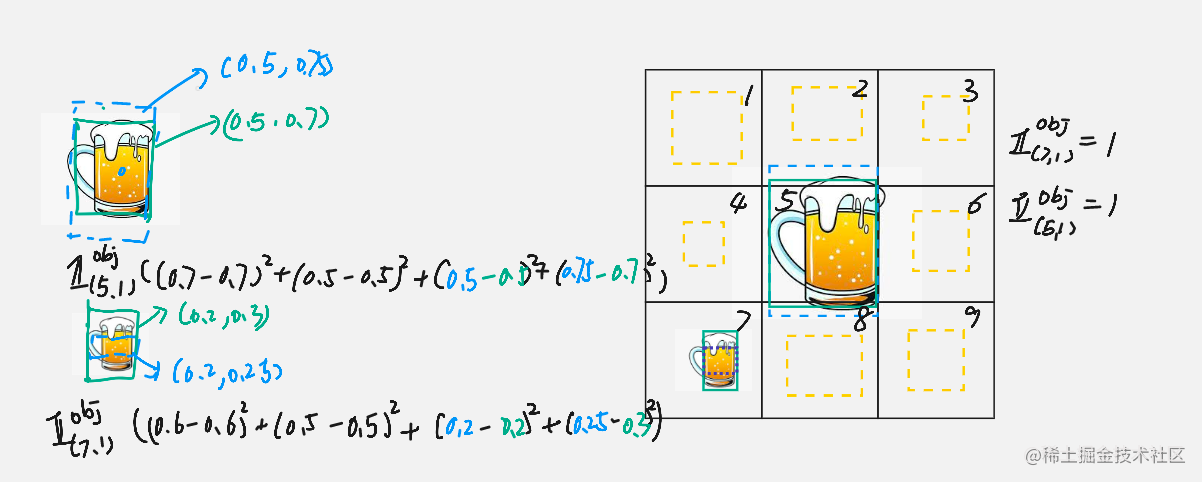
我们这里来看对于大目标和小目标,x 、y 和 h 差都是一样,最后计算下来
(0.75−0.7)2 和
(0.25−0.3)2 所以都是
(0.05)2 和
(0.05)2 不过显然是有问题对于小目标 0.05 偏差面积对于大目标的识别影响没有对小目标影响大。解决方案就是在做差之前先对宽度(w)和高度(h)进行一次开方。
λcoordi=0∑S2j=0∑B1ijobj[(xi−x^i)2+(yi−y^i)2+(wi
−w^i
)2+(hi
−h^i
)2]
目标对象损失
| i |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
Ci |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
|
C^i |
0.1 |
0.1 |
0.1 |
0.1 |
0.6 |
0.1 |
0.6 |
0.1 |
0.1 |
|
Ci−C^i |
0.1 |
0.1 |
0.1 |
0.1 |
0.4 |
0.1 |
0.4 |
0.1 |
0.1 |
上面这张表简单说一下,i 需要表示是第几个网格,也就是 3x3 网格,没有目标网格给出bbox 可能包含目标的概率是 0.1 而,有目标存在网格对应 bbox 给出概率为 0.6 这样计算预测目标损失函数为
i=0∑Sj=0∑B(Ci−C^i)2=2×(0.4)2+7×(0.1)2=0.32+0.07
其实如果
7×7 那么就是 96 个是没有目标网格,也就是 0.96 反而要不比 0.32 大得多,产生这样原因主要是由于正负样本不均匀造成的。如果对此不做调整,模型在学习过程中会把重点放在背景学习上。解决这个问题方法也很简单就是给没有目标损失值乘以一个系数,这些为 0.5 。
i=0∑S2j=0∑B1ijobj(Ci−C^i)2+λnoobji=0∑S2j=0∑B1ijnoobj(Ci−C^i)2
类别损失
j=0∑S21ijobj(pi(c)−p^i(c))2
对于类别误差,就不需要考虑 bbox 了。
YOLOv1 vs FasterRCNN

检测率上进行对比
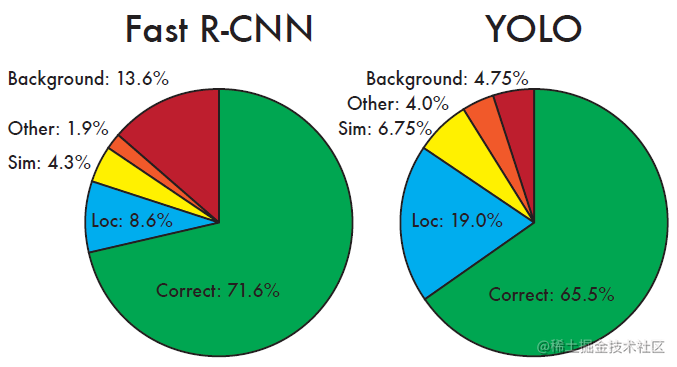
在上面这张图,给出 YOLOv1 和 Fast R-CNN 错误分析
- 先看背景错误分析,这里 Fast R-CNN 为 13.6% 而 YOLO 只有 4.75% 错误率,其实原因也很简单,这是因为在 YOLOv1 中只提出 98 候选框,而在 Fast R-CNN 中通过 selective search 提出了大概 2k 多候选框
- 从正确率来看 Fast R-CNN 还是要超过 YOLOv1 这是因为 Fast R-CNN 提出候选框要远远大于 YOLOv1 提出的候选框
- 在定位方面,从图标上来看 YOLOv1 也是不如 Fast R-CNN
实时检测上进行对比
YOLOv1 的限制
其实 YOLOv1 在输出上有些先天限制
S×S×(B×(1+4)+C),因为在 YOLOv1 中每一个网格都只能做一个类别检测,那么像下图中,girl 和 car 这两个目标的中心点都落在同一个网格中,或者很多目标中心点都落在同一个网格时,YOLOv1 就变得束手无策。现在是两个(B=2) bbox 是共享一个类别预测的,可以让两个 bbox 都有各自的类别预测,也就是
S×S(B×(1+4+C))

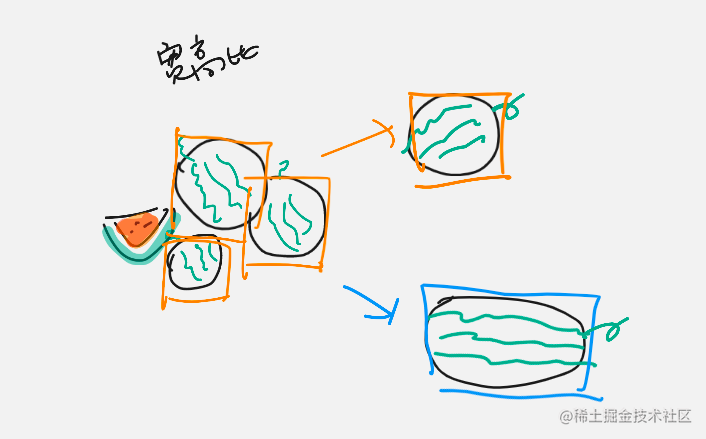
还有就是如果 YOLOv1 见过的西瓜都是圆圆的,他学到一个宽高比接近 1 宽高比,不过一旦见到一个椭圆的西瓜,这是一个和之前具有不同宽高比的西瓜,YOLOv1 可能就很容易检测不出来。
我正在参与掘金技术社区创作者签约计划招募活动,点击链接报名投稿。