ConvBERT 论文地址https://arxiv.org/pdf/2008.02496.pdf
1. 论文中指出的BERT以及相关变体的问题
1. Bert 以及相关变体严重依赖于全局自注意力模块,这导致了模型占用了很大内存和计算成本,但是根据现有的最新论文和观察attention map发现一些注意力的头只学习到了局部依赖,也就是用全局注意力模块学习局部依赖,造成了计算的浪费和计算的冗余[1][2][3]。
2. 自然语言中的固有特征,局部依赖性强。
3. 在对下游任务进行微调时,移除一些注意力的头没有降低性能。模型中存在大量的计算冗余。
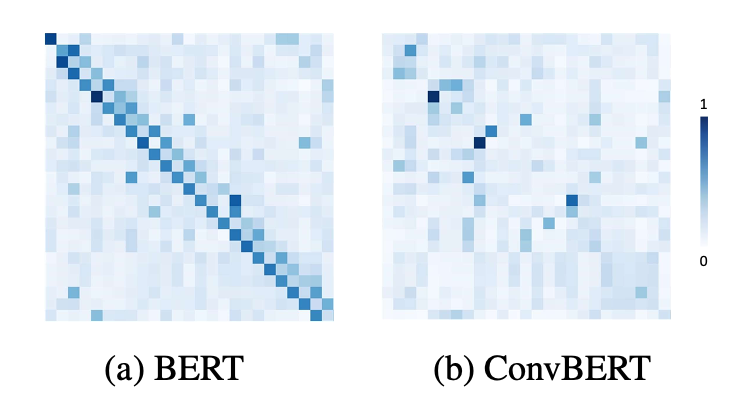
下图是从MRPC数据集中选取的一句执行的结果"[CLS] he said the foods ##er ##vic ##e pie business doesn ’ t fit the company ’ s long - term growth strategy . [SEP]".
从 BERT 和 ConvBERT 中的自注意力模块的 attention map 可视化图对比也可以看出,不同于原始的集中在对角线上的 attention map,ConvBERT 的 attention map 不再过多关注局部的关系,而这也正是卷积模块减少冗余的作用体现。
2. 论文的目标
论文的目标是解决这个固有的冗余问题,并进一步提高BERT的效率和下游任务性能。
思考的问题:我们可以通过使用自然的局部操作来替换注意力集中来减少注意力的冗余吗?
论文中提出了一种新的基于Span的动态卷积模型ConvBERT, 把基于Span的动态卷机代替局部依赖性的自注意力的头。新的卷积头与其他自我注意头一起形成了一种新的混合注意块,使得不管是全局还是局部上下文的学习都更棒。
3. 论文的方法
3.1 基于跨度的动态卷积
我们注意到卷积在提取局部特征方面非常成功,因此建议使用卷积层作为自我注意的更有效补充,以解决自然语言中的局部依赖性。
具体来说,我们建议将卷积与自我注意相结合,形成一种混合注意机制,将这两种操作的优点结合起来。自我注意使用所有输入标记生成注意权重,以捕获全局依赖关系,同时我们希望执行局部操作。
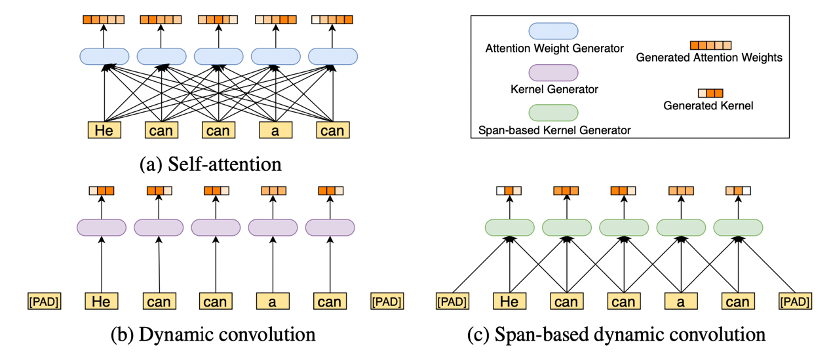
图1:产生注意力权重或卷积核的过程。(a) 自我注意力:需要所有输入标记来生成需要二次复杂性的注意权重。(b) 动态卷积:动态卷积核是通过只接收一个当前令牌来生成的,这会导致为相同的输入令牌生成相同的内核,这些令牌具有不同的含义,比如“can”令牌。(c) 基于跨度的动态卷积:卷积核是通过获取当前标记的局部上下文信息生成的,这可以更好地利用局部依赖性,并区分同一标记的不同含义(例如,如果输入句子中“a”在“can”前面,“can”显然是名词而不是动词)。

上图是自我注意、动态卷积和基于跨度的动态卷积的说明。在这里,LConv表示轻量级的深度方向卷积,该卷积沿通道维度连接所有权重,但在每个位置使用不同的卷积核。
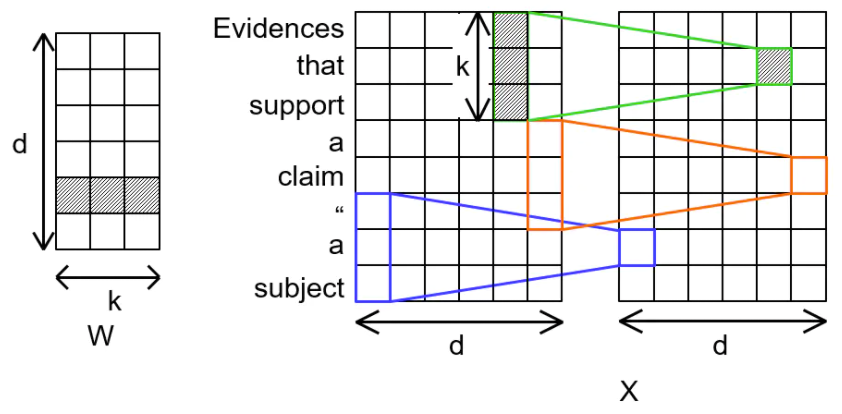
输入X以生成Q和V,以及深度可分离卷积以生成感知范围的Ks。然后,使用从输入X转换的Q和跨度感知密钥Ks对的逐点乘法结果生成动态卷积核。具体来说,使用查询和密钥对Q、Ks作为输入,轻量级卷积核由下面的公式生成的
![]()
上面公式里的⊙ 表示逐点乘法。如图3c所示,我们称之为新操作符基于跨度的动态卷积。输出可以写为
![]()
然后应用线性层进行进一步处理。如果没有另外说明,对于深度可分离卷积和基于跨度的动态卷积,我们总是保持相同的内核大小。
3.2 ConvBERT的架构
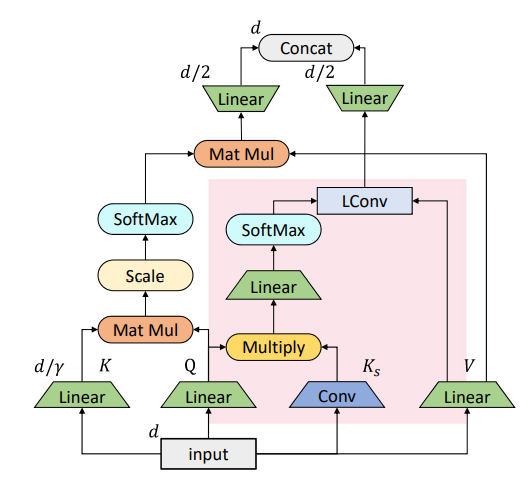
在基于跨度的卷积的基础上,依图将其与原始的自注意力机制做了一个结合,得到了如图所示的混合注意力模块。
可以看到,被标红的部分是基于跨度的卷积模块,而另一部分则是原始的自注意力模块。其中原始的自注意力机制主要负责刻画全局的词与词之间的关系,而局部的联系则由替换进来的基于跨度的卷积模块刻画。
Mixed attention集成了self-attention和span-based dynamic convolution,其中self-attention负责捕获全局信息,span-based dynamic convolution负责捕获局部信息。self-attention和span-based dynamic convolution使用相同的query和value,但是使用不同的key。Mixed attention的计算公式为:
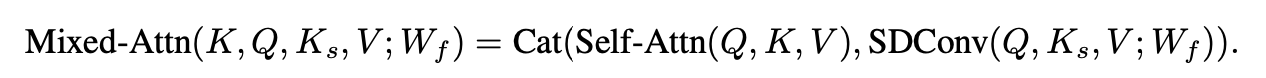
最终输出被送到前馈层进行进一步处理。
参考文献
[1] Kovaleva O , Romanov A , Rogers A , et al. Revealing the Dark Secrets of BERT[J]. 2019.
[2] Brunner G , Liu Y , Pascual D , et al. On Identifiability in Transformers[C]// ICLR 2020. 2020.
[3] Michel P, Levy O, Neubig G. Are sixteen heads really better than one?[J]. Advances in neural information processing systems, 2019, 32.
[4] Wu F , Fan A , Bae Vs Ki A , et al. Pay Less Attention with Lightweight and Dynamic Convolutions[J]. 2019.
[5] Chollet F . Xception: Deep Learning with Depthwise Separable Convolutions[J]. IEEE, 2017.
其它
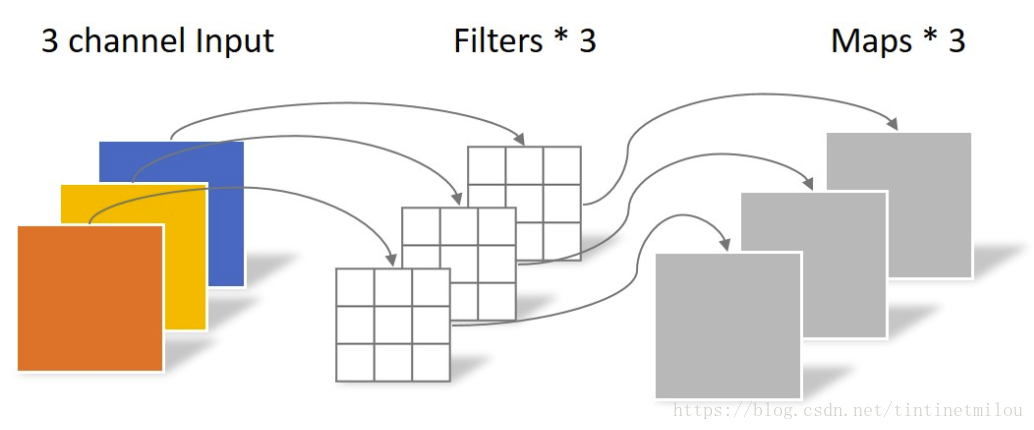
1. 常规卷积| regular convolution
图片处理中的例子
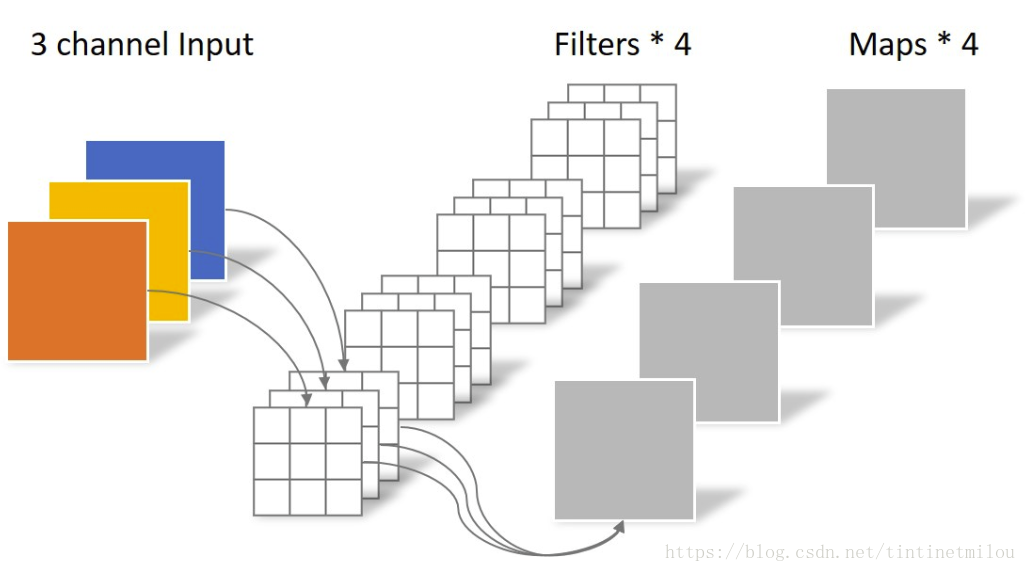
NLP中的例子
其中K为卷积核的宽度,代表输入的embedding的维度,
代表输出的embedding的维度,如果
,则需要的参数量为
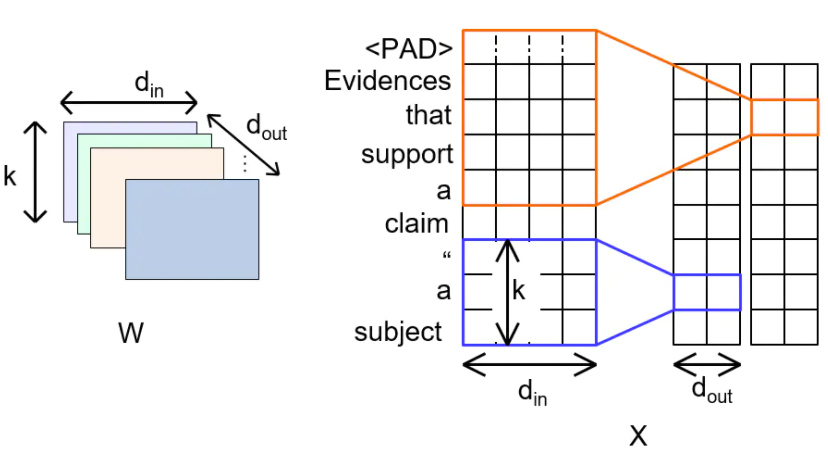
2. 深度可分卷积|Depthwise Separable Convolutions
深度可分卷积是卷积神经网络中对标准的卷积计算进行改进所得到的算法,其通过拆分空间维度和通道(深度)维度的相关性,减少了卷积计算所需要的参数个数,并在一些研究中被证实提升了卷积核参数的使用效率 。
深度可分卷积的原型可认为来自于卷积神经网络中的Inception模块,其卷积计算分为两部分,首先对通道(深度)分别进行空间卷积(depthwise convolution),并对输出进行拼接,随后使用单位卷积核进行通道卷积(pointwise convolution)以得到特征图 。
深度可分卷积分为两部分,首先使用给定的卷积核尺寸对每个通道分别卷积并将结果组合,该部分被称为depthwise convolution,随后深度可分卷积使用单位卷积核进行标准卷积并输出特征图,该部分被称为pointwise convolution 。
Depthwise Convolution
Pointwise(PW)卷积就是卷积核为1x1的,也叫点卷积,对map处理,得到新的Feature map。
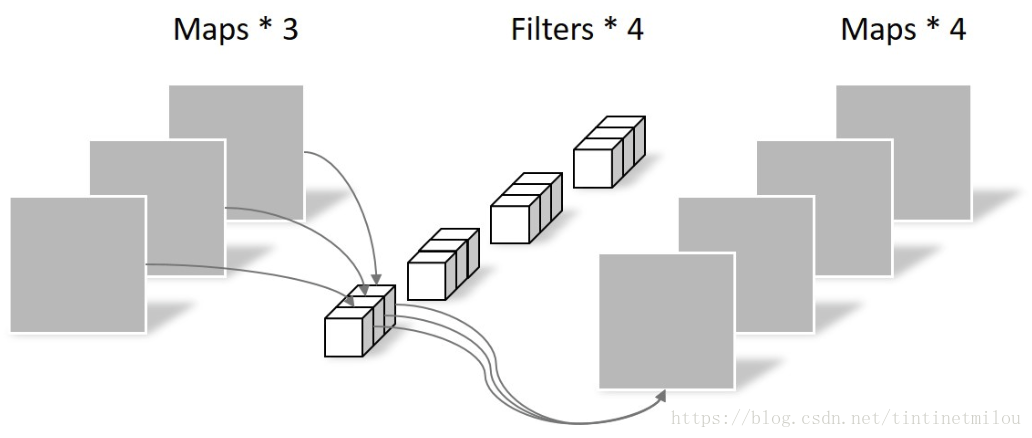
NLP中的例子
Depthwise convolution缩减了传统卷积方法的参数量:
其中K为卷积核的宽度, d代表embedding的维度。
其输出的计算方式为:
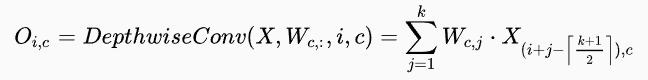
通过使用depthwise convolution,参数量降为
depthwise convolution(没有第二部分pointwse)的在在tensorflow或keras的实现方式
tf.keras.layers.DepthwiseConv1D 和tf.keras.layers.DepthwiseConv2D
depthwise separable convolution的在在tensorflow或keras的实现方式
tf.keras.layers.SeparableConv1D和tf.keras.layers.SeparableConv2D
下面是论文的地址
https://arxiv.org/pdf/1610.02357.pdf
3. Lightweight convolution
如图所示,H=3,X分割为3个区域,W与X相同颜色区域进行相乘,共享参数
通过Weight sharing,参数的数量继续下降为Hk。
其输出的计算公式为:

Softmax-normalization对卷积核channel一维进行softmax处理,相当于归一化每个词的每一维的重要性。实验表明,如果不进行softmax就不会收敛。
https://arxiv.org/pdf/1901.10430.pdf
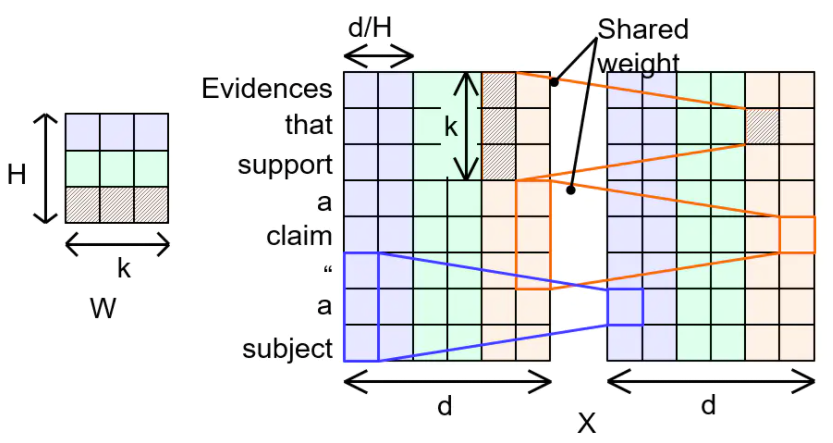
4.Dynamic convolution
Dynamic convolution会动态地生成卷积核:
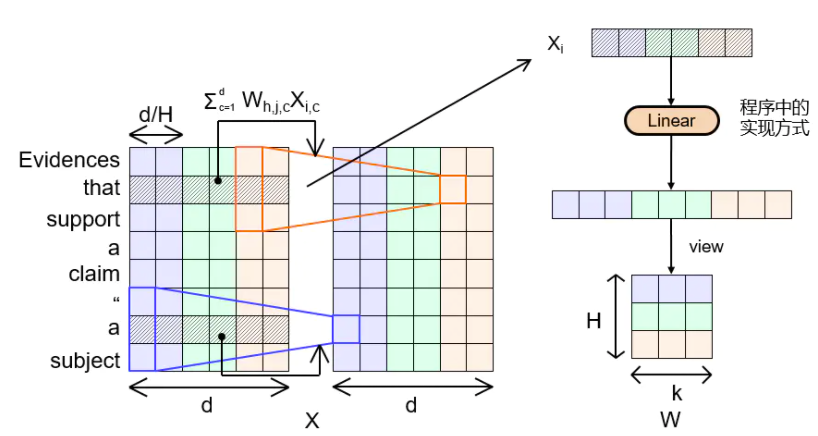
Dynamic convolution会为每一个词的embedding动态地生成卷积核,生成卷积核时使用一个kernel generator,这个kernel generator是一个函数,是一个线性映射,其中权重,动态生成位置词的卷积核公式为:
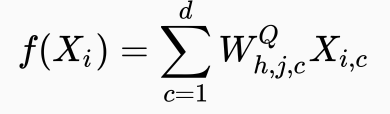
Dynamic convolution计算输出的公式为:
![]()
上图中,右侧部分为帮助理解,实际计算中并未进行view步骤。
5. 动态滤波器卷积|DynamicConv
作者认为普通的CNN是轻量级的卷积,而且这种轻量级的卷积由于其较低的计算预算限制了CNN的深度(卷积层数)和宽度(通道数),导致其表征能力有限,因此性能下降. 为了解决这个问题提出了动态卷积。下图是动态卷积模块的图。原来是用一个卷积核提取信息,太简单,为了提取更复杂的表征,用一组大小相同卷积核来,然后利用squeeze-and-excitation计算其卷积核的注意力(就是每个卷机核的权重大小,起到提升好的卷机核和抑制差的作用)。然后相加这组卷积核的提取的表征,后面就是BN和激活函数了。
和squeeze-and-excitation思路是一样的,只是用到的地方不一样,SENET是通道注意力,计算通道注意力大小的函数是sigmoid,而DynamicConv是卷积核注意力,对一组卷机核提取的结果进行注意力动态聚合。
论文的主要思想
动态态卷积的创新在于将多个卷积核与注意力机制相结合。注意力机制采用avg pool和两层全连接层,模型复杂度低且高效;使用Softmax将权重限制在0与1之间,使模型能够深层次学习特征。动态卷积也不再是一个线型函数,而是通过注意力以非线性方式叠加特征表达能力更强。
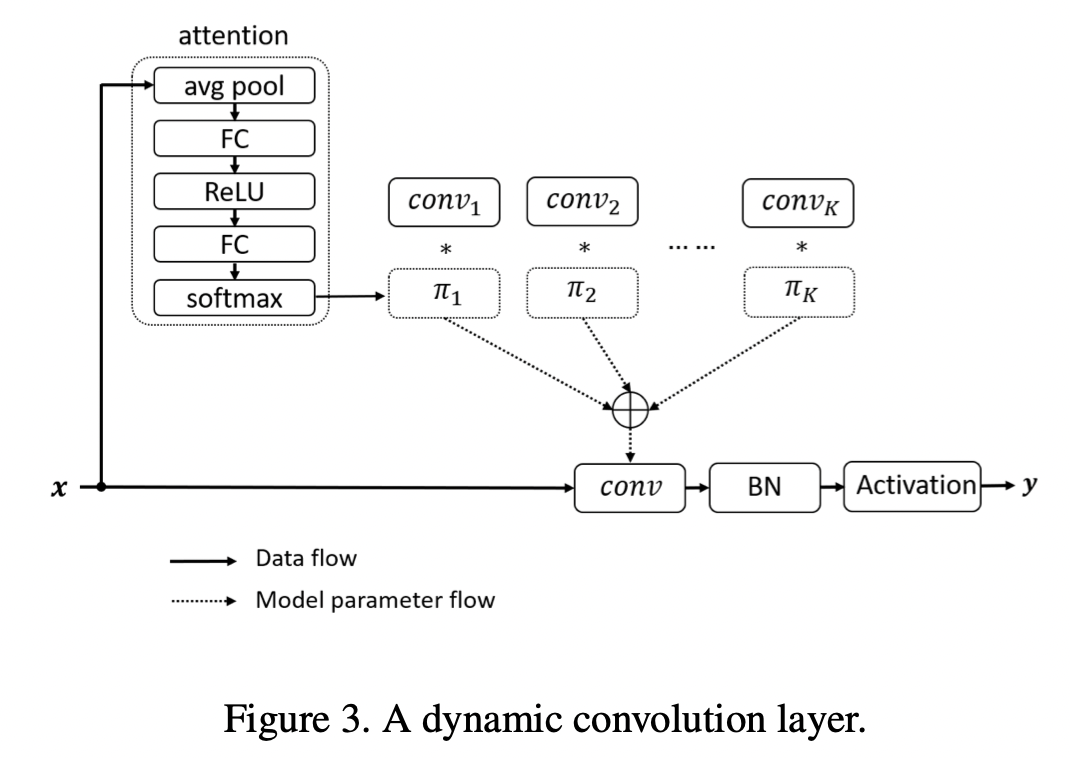
首先对k个卷积核的结果->全局平均池化(avg pool)->线性转换(FC)->激活函数->线性转换(FC)->softmax得到卷机核结果的注意力权重->注意力权重*不同卷积核的结果,然后相加->BN->Activation.
Dynamic Convolution: Attention over Convolution Kernels
论文地址
https://arxiv.org/pdf/1912.03458.pdf
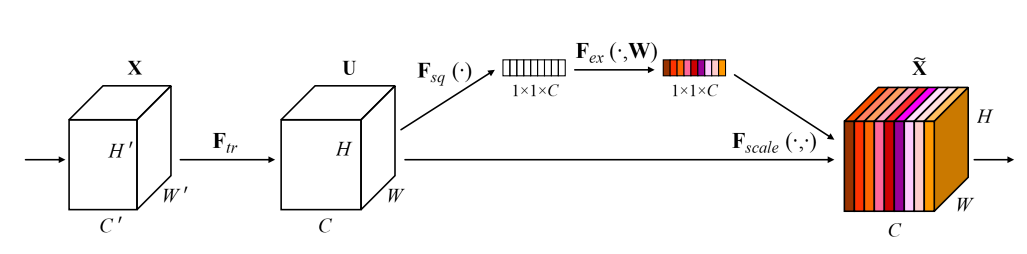
6. SENet(Squeeze-and-Excitation Networks)
首先是 Squeeze 操作,我们顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
其次是 Excitation 操作,它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。
最后是一个 Reweight 的操作,我们将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
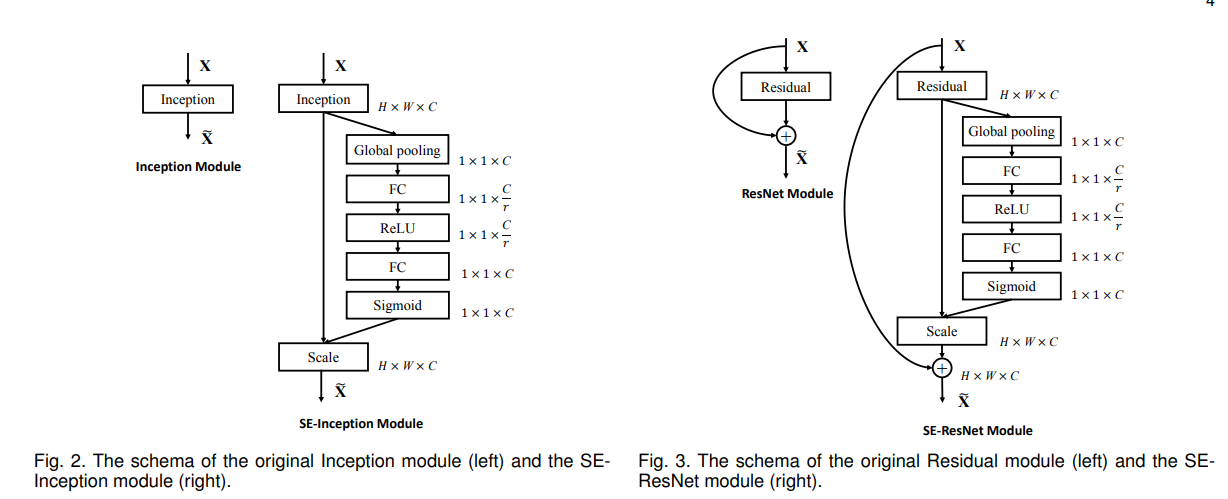
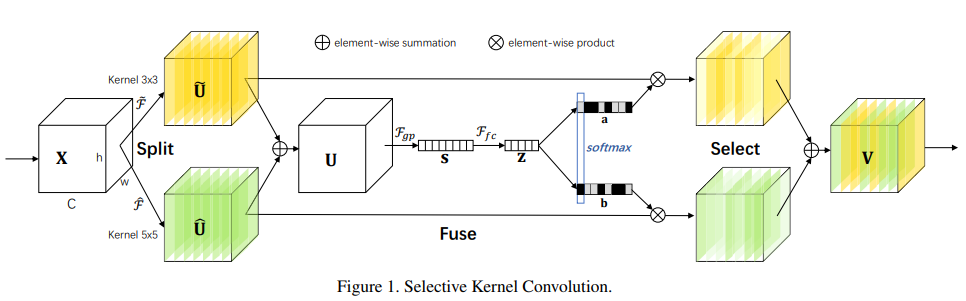
7. SKnet (Selective Kernel Networks)
在标准卷积神经网络(CNN)中,每层人工神经元的感受野被设计为共享相同的大小。神经科学界众所周知,视觉感受野的大小皮层神经元受到刺激的调节,这在构建CNN时很少被考虑。我们在CNN中提出了一种动态选择机制,允许每个神经元根据输入信息的多个尺度自适应调整其感受野大小。设计了一个称为选择性内核(SK)单元的构造块,其中,多个具有不同内核大小的分支使用softmax注意力进行融合,该注意力由这些分支中的信息引导。对这些分支的不同关注产生了融合层神经元有效感受野的不同大小。多个SK单元堆叠在一个称为选择性内核网络(SKNET)的深层网络中。在ImageNet和CIFAR基准上,我们的经验表明,SKNet的性能优于现有的最先进的体系结构,模型复杂度更低。详细分析表明,SKNet中的神经元能够捕获不同尺度的目标对象,验证了神经元根据输入自适应调整接收野大小的能力。
8. Revealing the Dark Secrets of BERT
基于 BERT 的架构目前在许多 NLP 任务上都提供了最先进的性能,但对于促成其成功的确切机制知之甚少。在目前的工作中,我们专注于解释 self-attention,这是 BERT 的基本组成部分之一。使用 GLUE 任务的一个子集和一组手工制作的感兴趣特征,我们提出了该方法并对由单个 BERT 的Head编码的信息进行了定性和定量分析。我们的研究结果表明,有一组有限的注意力模式在不同的Head重复,表明整个模型过度参数化。虽然不同的Head始终使用相同的注意力模式,但它们对不同任务的性能有不同的影响。我们表明,手动禁用某些Head的注意力会导致比常规微调 BERT 模型的性能提高
9. ON IDENTIFIABILITY IN TRANSFORMERS
在本文中,我们通过研究 Transformer 架构的两个核心组件:self-attention 和 contextual embeddings,深入研究了 Transformer 架构。特别是,我们研究了注意力权重和令牌嵌入的可识别性,以及将上下文聚合到隐藏令牌中。我们表明,对于比注意力头维度更长的序列,注意力权重是不可识别的。我们建议将有效的注意力作为一种补充工具,以改进基于注意力的解释性解释。此外,我们表明输入标记在很大程度上保留了它们在模型中的身份。我们还发现有证据表明身份信息主要以嵌入的角度编码,并随着深度而逐渐减少。最后,我们通过一种基于梯度归因的新量化方法证明了在生成上下文嵌入时输入信息的强混合。总体而言,我们表明自注意力分布不能直接解释,并提供了更好地理解和进一步研究 Transformer 模型的工具。
10. Are Sixteen Heads Really Better than One?
多头注意力是最近最先进的 NLP 模型背后的驱动力。 通过并行应用多种注意力机制,它可以表达超越简单加权平均的复杂功能。 然而,我们观察到,在实践中,大部分注意力头可以在测试时被移除而不会显着影响性能,并且某些层甚至可以减少到单个头。 对机器翻译模型的进一步分析表明,自注意力层可以被显着修剪,而编码器-解码器层更依赖于多头性。

作者在模型WMT和BERT上做实验。
WMT 这是来自 Vaswani 等人的原始“Large”Transformer架构。 2017 6层每层 16 个头,在 WMT2014 英语到法语语料库上进行训练。

为了更详细地了解这些结果,作者放大了Table 1 中 WMT 模型的编码器自注意力层。值得注意的是,96个头中只有 8 个头从模型中移除时会导致模型性能发生大的变化,其中一半实际上会导致更高的 BLEU 分数。 这让作者认为:在测试时,考虑到模型的其余部分,大多数头部都是多余的。
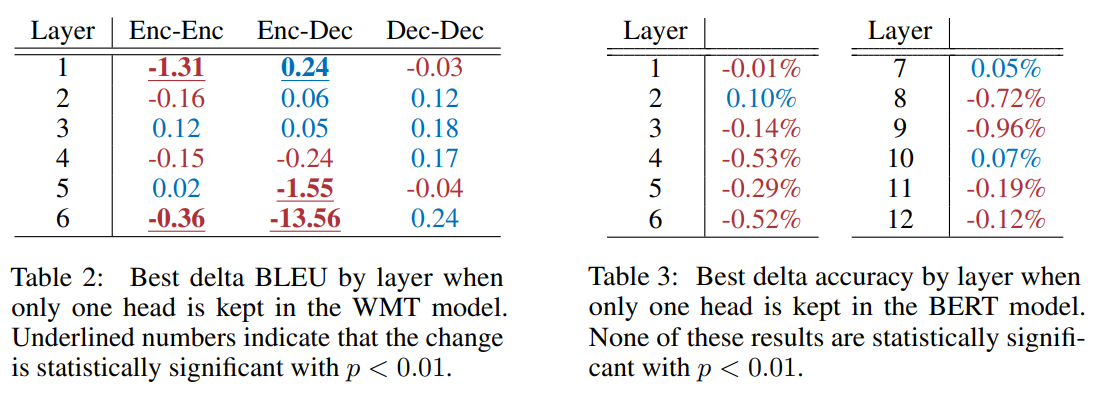
这一观察引出了一个问题:甚至需要不止一个头吗? 因此,我们计算在单层内移除除一个之外的所有头时的性能差异。 在Table 2 在Table 3 中,我们报告了模型中每一层的最佳分数,即将整个层减少到单个最重要的头部时的分数。
作者发现,对于大多数层,在测试时一个头确实足够了,即使网络是用 12 或 16 个注意力头训练的。 这很了不起,因为这些层可以减少到单头注意力,只有普通注意力层参数数量的 1/16(分别为 1/12)。 然而,有些层确实需要多个注意力头; 例如,用单个头替换 WMT 的编码器-解码器注意力中的最后一层会使性能降低至少 13.5 BLEU 点。 我们进一步分析不同的建模组件何时依赖于更多§5中的标题。
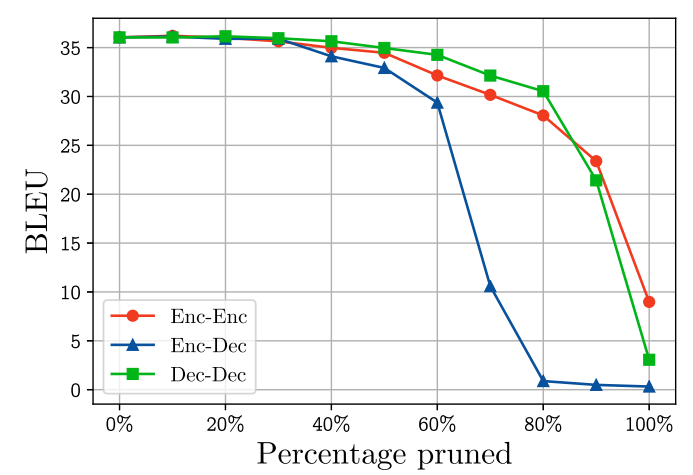
上图显示,当从 Enc-Dec 注意力层中修剪头部时,性能下降得更快。 特别是,修剪 60% 以上的 Enc-Dec 注意力头将导致 灾难性的性能下降,而编码器和解码器的自注意力层仍然可以产生合理的翻译(BLEU 分数在 30 左右),只有原始注意力的 20%头。
结论:
我们观察到,这种方法允许我们(分别)从 WMT 和 BERT 中修剪多达 20% 和 40% 的头部,而不会产生任何明显的负面影响。 进一步修剪时性能急剧下降,这意味着在不重新训练或对性能造成重大损失的情况下,这两个模型都不能简化为纯粹的单头注意力模型。
Encoder-Decoder注意力比Self-Attention更多地依赖于多头注意力.
https://proceedings.neurips.cc/paper/2019/file/2c601ad9d2ff9bc8b282670cdd54f69f-Paper.pdf
参考资料