零、前言
由于负责产品的性质原因,我需要大量接触 Kafka,因此对 Kafka 的使用和原理都有一定的了解,希望通过这个专栏分享给你,如果对你有帮助的话,期待你的一件三连!
上一篇讲了生产者 Producer 在发送消息时的工作流程和原理,也列举了一些生产端高频使用的参数,但这都是「纸上谈兵」,这些参数具体怎么应用呢?所以这一期就来聊聊 Kafka 生产者的常用调优手段,主要内容包含:
- 调优:提高生产者的吞吐量 ✅
- 调优:保障数据的可靠性 ✅
- 调优:保证数据的唯一性 ✅
- 调优:保证数据的有序性 ✅
一、提高生产者的吞吐量
我们先来回顾一下 Kafka 的生产流程,我们可以发现缓冲区就像数据的集散地,数据最后都在这汇总,然后等待 Sender 线程来拉走;如果把数据比作群演,Sender 线程就是剧组,有群演报名,剧组就把它拉走。
之前是有人报名,剧组就拉走,但这一来一回啊是需要时间的,大客车呢,一次就拉这么几个人,乍一看好像有点亏,那为什么不多等几个人再一趟拉走呢?这就是这个优化的核心方向了,只要让数据多等一会,到了一定批次再拉走,就能节约大量的时间。
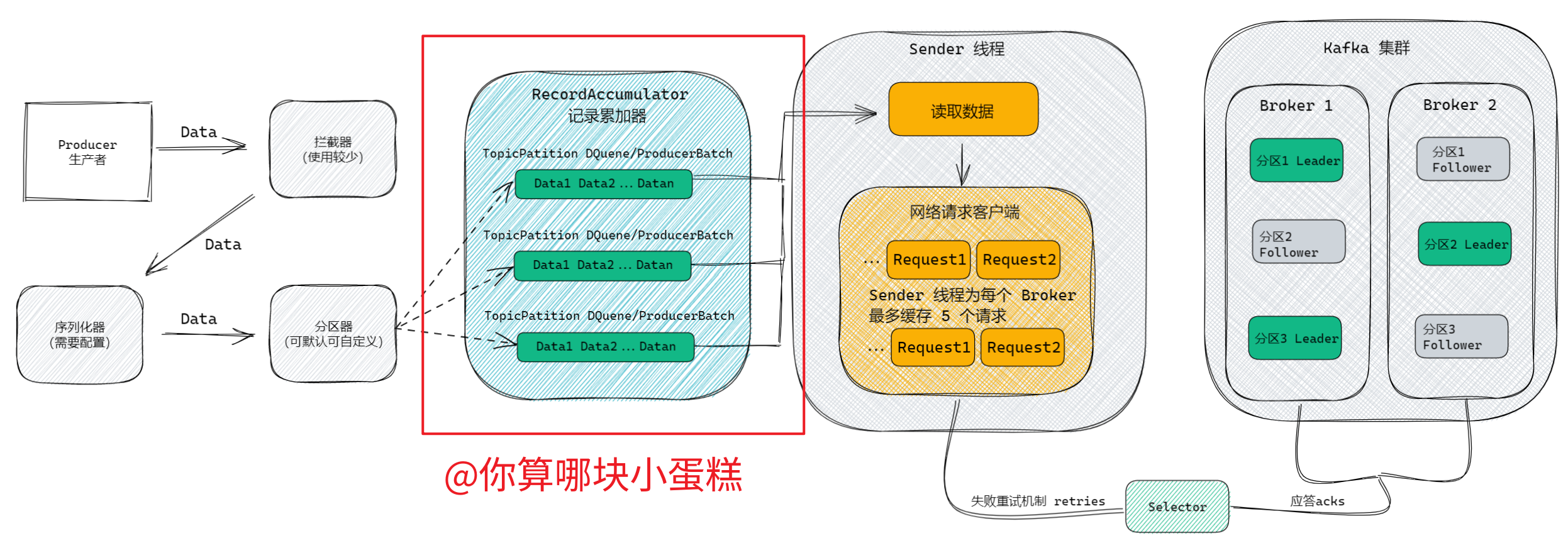
因此,我们重点优化的地方是缓冲区,控制缓冲区的参数有下面这些,我们只需要适当配置下面的参数,就能极大的提高生产者的吞吐量:
| 参数名 | 作用 |
|---|---|
buffer.memory |
缓冲区 RecordAccumulator 总大小,默认 32m |
batch.size |
缓冲区内的批次队列 ProducerBatch 大小,默认 16k |
linger.ms |
如果数据迟迟未达到 batch.size,Sender 等待 linger.time 之后就会发送数据。默认值是 0ms,表示没 有延迟。生产环境一般设置为 50ms |
compression.type |
生者者发送数据的时候是否压缩,默认是 none,支持 gzip、snappy、lz4 和 zstd,生产环境一般使用 snappy 生产者配置了压缩参数,消费者那边也要配置相应的参数 |
给出一个我在生产环境用过的配置示例,具体怎么配置还得根据你业务数据大小和量级来尝试:
buffer.memory = 128m
batch.size = 64k
linger.ms = 50ms
compression.type = snappy
二、保障数据的可靠性
保障数据的可靠性是指,我们如何能确保消息一定到达 Kafka 的 Broker,并持久化落盘。
在前面的文章中我们提到过,Kafka 为了保障数据的安全,做了「冗余」,也就是多副本机制,Leader 负责数据的交互,Follower 负责从 Leader 拉取数据备份,这就涉及到一个同步的问题——Kafka 如何认定副本是保持同步的?
下图【Kafka 的多副本机制】:
我们先复习一下 Kafka 概述篇的内容——ISR( 同步副本集合) 。
这个集合里面记录了所有与 Leader 保持同步的副本集合,也包括 Leader 自己,举个例子:ISR(leader: 0,isr: [0, 1, 2]),代表着有两个副本 1、2 和 Leader 0 保持着同步,一旦 Leader 挂掉,会在 ISR 中重新挑选 Leader。
同时,生产者会根据 ACKS 的配置来确定数据是否成功落盘,在默认配置 ACKS=1 下,只要 Leader 成功落盘并响应,生产者便视为发送成功,假如 Leader 在响应后,Follower 还没来得及同步,Leader 挂掉,在 Follower 称为新的 Leader 之后,这条消息便丢失了。
保障数据可靠性的前提,就是要设置 ACKS=all,等全部副本分区落盘应答后,再告诉生产者,我已经成功收到消息!当然,分区副本也要设置大于 2 的数量,否则 ACKS=all 和 ACKS=1 没有任何区别。
总结一下,数据完全可靠的条件需要做到以下三点:
- 设置分区副本大于等于
- 设置 ACKS=all,让所有副本确认落盘
- ISR 里最小要有 2 个副本(超过时常不同步的副本会被踢出)
这个设置适用于对消息要求非常严格的场景,普通场景不推荐,保障可靠性的同时也会影响发送消息的效率。
三、保证数据发送不重复
设想这样一个场景,如下图:
在上面的场景中,同一条消息被发送了两次,所以在 Kafka 0.11 以后,引入了重大特性——幂等性和事务,就是来解决这一问题的:
- 幂等性指 Producer 不论向 Broker 发送多少次重复的数据,Broker端都只会持久化一条,保证了不重复
- 在启用幂等性的前提下,生产者可以开启事务,在一个事务内发送的数据,要么全部成功,要么全部失败
幂等性是如何判断数据重复的? 具有<PID, Partition, SeqNumber>相同主键的消息提交时,Broker 只会持久化一 条。PID 是生产者的唯一 ID,Kafka 每次重启都会重新分配;Partition 表示分区号;Sequence Number 是单调自增的消息号。这三个参数组合形成一个主键,相同主键的消息 Kafka 只会持久化一次,这就是幂等性的原理。
根据幂等性的原理可知,它只能保证单分区单会话内数据不重复,假如跨分区了,那就不好使了,如果涉及到这种情况,就可以使用事务。
如何开启幂等性? 可以通过配置生产者的 enable.idempotence 项来开启幂等性,默认开启。
如何使用事务? 如下代码,如果中间有某条消息发送失败,所有消息会一起发送失败
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class Test {
public static void main(String[] args) {
// 配置生产者
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//设置事务ID,必须
properties.setProperty(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "transactional_id_1");
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
// 初始化事务
producer.initTransactions();
// 开启事务
producer.beginTransaction();
//发送10条消息往kafka,假如中间有异常,所有消息都会
try {
producer.send(new ProducerRecord<>("topic-test", "a message" + i));
}
// 提交事务
producer.commitTransaction();
} catch (Exception e) {
// 终止事务
producer.abortTransaction();
} finally {
producer.close();
}
}
}
四、保证数据持久化的有序性
首先要明确的是,由于 Kafka 的架构决定,跨分区是无法保持数据的有序性的,我们只能保证单分区的有序性。
在第二期生产者详解一文中,我们详细解释了生产者的工作流程:
在 Kafka 1.X 之后,Broker 能缓存最近 5 个来自生产者的请求信息,假如超过五个,前面的请求会被刷掉;而 Sender 线程默认的情况下,为每个 Broker 缓存了 5 个请求,正正好!但是 Sender 线程的缓存请求数是可以通过参数 max.in.flight.requests.per.connection 来改变的。
Kafka 1.X 以后,默认幂等性,Sender 线程和 Broker 缓存的请求数也正正好,是能保证在单分区下消息的顺序性的,怕就怕在你从网上拷贝了参数,又看不懂,来硬的,出问题了抓耳挠腮的加班就不好了,别问我为什么知道,问就是有人这么干过。因此我认为这个还是值得单独拎出来讲一讲的。
五、写在最后
Kafka 专栏已经更新了三期啦:
本系列长期更新,内容根据资料整理和个人理解重新整理输出,原创保证。我是蛋糕,致力于以体系化的方式分享知识,点个关注不迷路!