

g(x) 即为最终的选择

容易理解,但缺乏强有力的数学理论保障

1.首先学如何做分支
扫描二维码关注公众号,回复:
1439579 查看本文章

2.根据分支,分成c块,
3. 各分支学习一个各自的小树
4. 各分支整合起来,生成大树。
但只有这4个步骤,可能不行,因为没有停止的条件。

1.每次一刀切两段,只建造二元树
2. 回传一个最好的常数(二元分类,回传最多的y;回归问题,回传y的平均)
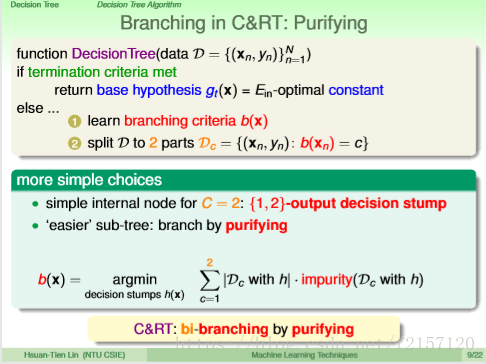
1.利用decision stump切分二元树。decision stump:在data中只看一个feature,决定完看那个feature后,就往两边切割,一边为+1,一边为-1。
CART:不断切割,到leaf时返回常数。
2.purifying:切开后,看起来比较纯的左边的dataset与右边的dataset,用最纯的切割方式作为现在的切割方法。

通过Ein 最小,来体现分类的纯度
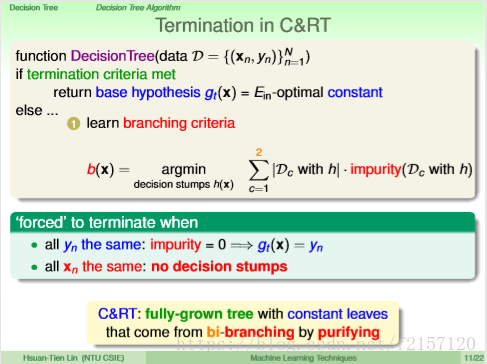



Ein=0,可能会导致模型过复杂,容易overfit
选择一个Ein不那么大,但不会overfit的树
摘掉一片叶子的树出发,逐步增加叶子,生成不同的树,选择Ein与复杂度加权后最优的树。用validation set选择一个适合的lambada


如果体重信息缺失,可以利用其它feature,如身高做切割,切出类似的效果。一般,身高越高,体重越重

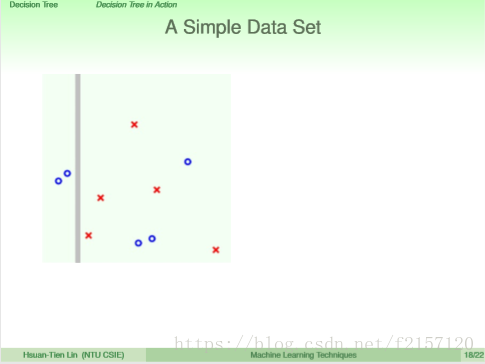
第一刀,左边非常纯净,两边各做一个子树,组成一颗大树
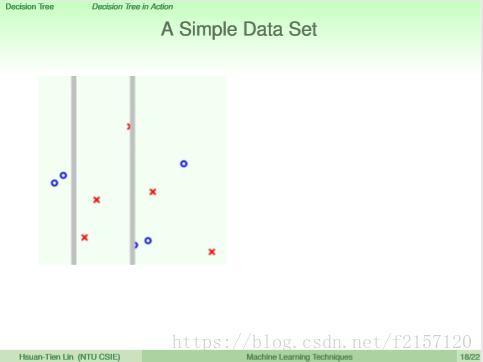
第二刀,对右边的子树切割,同样,左边最纯

第三刀,类似第二刀,将右边的子树的子树切割

同理,继续

切刀都很纯净

回传常数


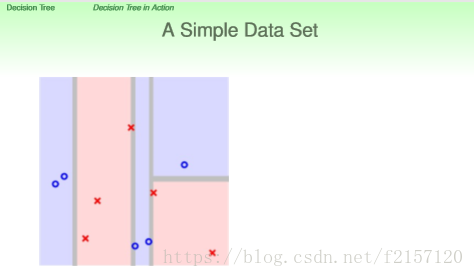
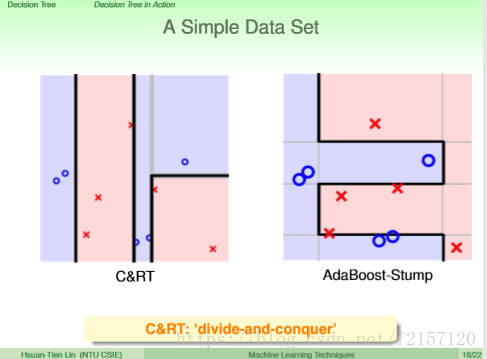
CART:每次针对不同的决策边界做切割,可以做比较细致的切割。
看起来比Adaboost,一定要切割完全的水平/垂直刀更有效率



CART如果不做pruning,会得到low Ein,但可能会导致overfit,high Eout
