awk工具
awk也是流式编辑器,针对文档中的行进行操作,一行一行地执行。awk兼具sed的所有功能,而且更加强大。
同样的,创建一个目录,将/etc/passwd拷贝到该目录下;
1. 截取文档中的某个段
打印该文件的第一行,使用命令“awk -F ':' '{print $1}' test.txt”;

-F的作用是指定分隔符,如果不加-F选项,则以空格或者TAB为分隔符,print为打印的动作,用来打印某个字段,$1表示第1个字段,$2表示第2个字段,以此类推,其中,$0表示全部内容;
打印所有行,使用命令“awk '{print $0}' test.txt”;

可以打印多段,可也自定义段与段之间的连接符;

2. 匹配字符或字符串
匹配‘oo’所在行;

匹配第1段中‘oo’的行;

匹配第3和4段‘root’或第1和3段及5段‘user’;

匹配‘root’或‘user’的行;

3. 条件操作符

awk中可以用逻辑符号进行判断,比如==就是等于,还有>、>=、<、<=、!=等。在和数字比较时,若把比较的数字用双引号引起来,那么awk不会认为是数字,而会认为是字符(sort排序),不加双引号则会认为是数字。

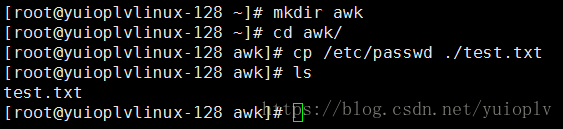
匹配第7行不是‘/sbin/nologin’的行,匹配字符串需要加上双引号;
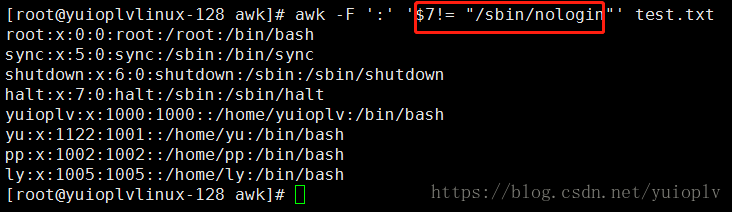
匹配第3行小于第4行;
匹配第3行等于第4行;

匹配第3行大于5且小于7(加上双引号,这个数字就会认为是普通字符,比较大小就是按ASCII码排序了);

匹配第3行大于1000或第7行等于‘/bin/bash’;

匹配第3行大于1000或第7行包含了‘/bash’;

4. awk的内置变量
awk常用的变量有OFS、NF和NR,OFS是用来定义分隔符的,它是在输出的时候定义,NF表示用分隔符分割后一共有多少段,NR表示行号。
匹配前三行中第1段、3段、6段,用*号分割;

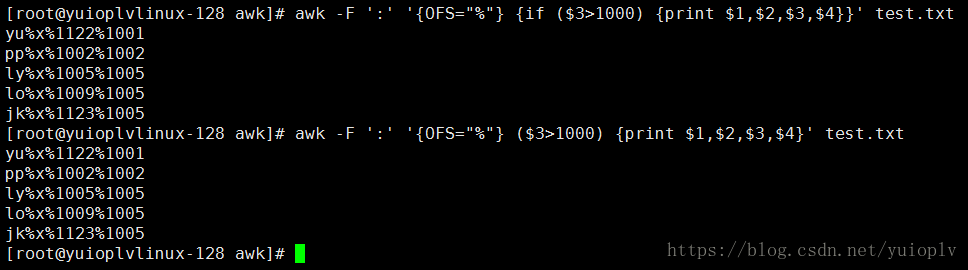
匹配第3行大于1000行的第1段、2段、3段、4段,用%号分割;
显示行号;
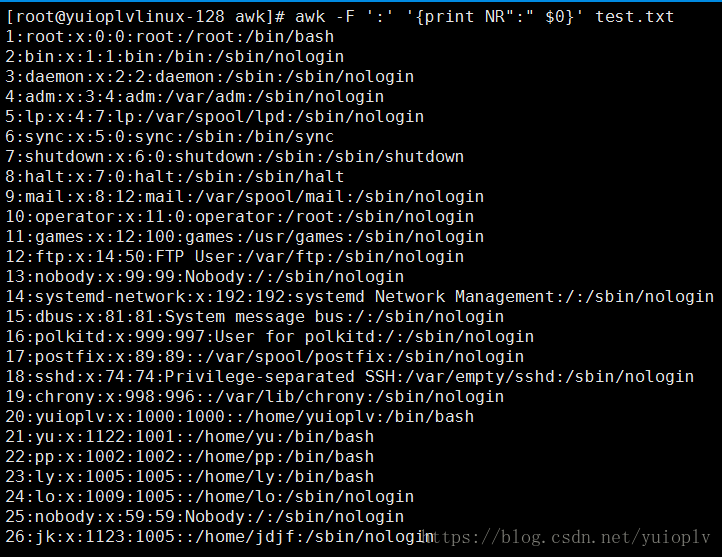
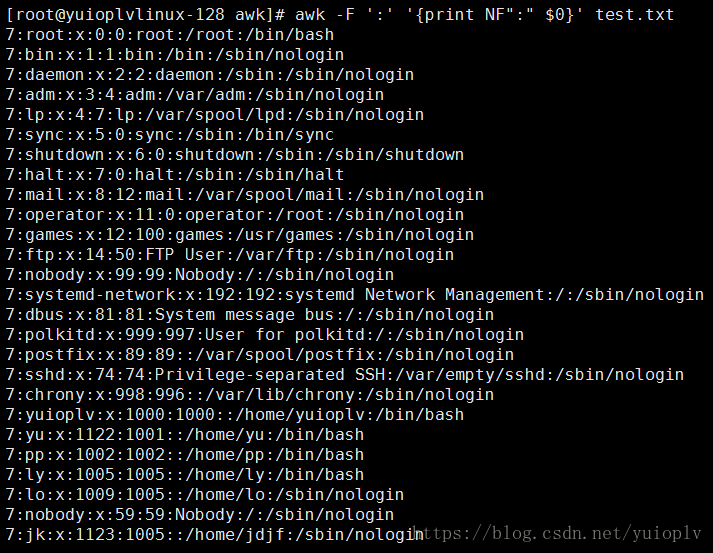
显示有几段;
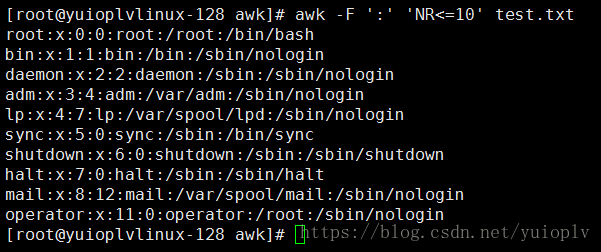
打印前10行;
前10行中且第1段包含了root或sync;

打印第$NR行(从1开始,一直到最后一行)及$NF(第7段);
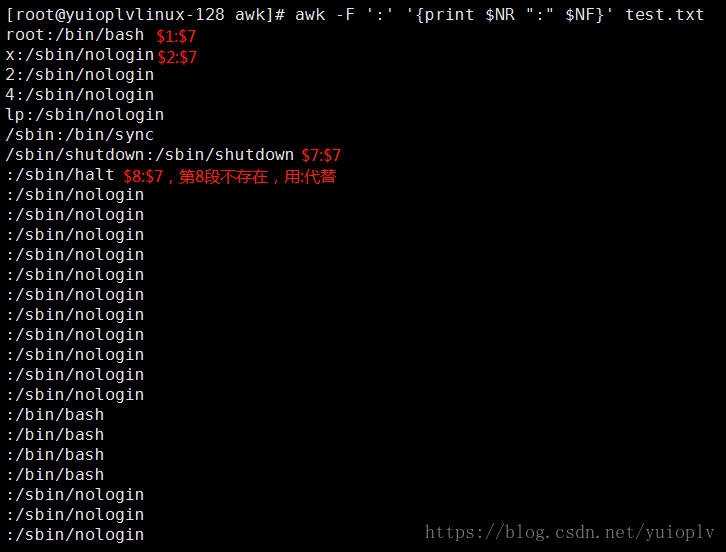
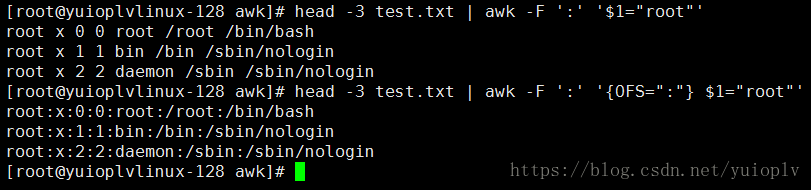
打印前三行的值,并将第一段的值赋值为root;
5. awk的数学运算
tot的值每次都与第3段相加,初始值为0,实现一个循环,并将总和打印出来。
