四个部分介绍了代码生成
import torch
import torchaudio
import librosa
import numpy as np
filename = "./sample.wav"
waveform, sample_rate = torchaudio.load(filename)
a = waveform.squeeze()
n_fft = 20
win_length = 20
hop_length = 10
# -------- part 1. torch spectrogram --------------
# pytorch spectrogram
# numpy --> tensor() , b = torch.from_numpy(a)
spec = torchaudio.transforms.Spectrogram(n_fft, win_length, hop_length)
spec_pytorch = spec(torch.Tensor(a))
print(" 1. torchaudio way spectrogram: ", spec_pytorch.shape)
# ---------- part 2. librosa spectrogram --------------
# librosa spectrogram
def Spectrogram(input, n_fft, win_length, hop_length):
stft_librosa = librosa.stft(y=input,
hop_length=hop_length,
n_fft=n_fft)
spec_librosa = pow(np.abs(stft_librosa),2)
return spec_librosa
a = a.numpy()
spec_librosa = Spectrogram(a, n_fft, win_length, hop_length)
print(" 2. librosa way spectrogram: ", spec_librosa.shape)
# --------------part 3. torchaudio Mel spectrogram -----------------
n_fft = 20
win_length = 20
hop_length = 10
sample_rate = 16000
mel_len = 12
mel_spec = torchaudio.transforms.MelSpectrogram(sample_rate, n_fft, win_length, hop_length, n_mels=mel_len)
mel_out = mel_spec(torch.tensor(a).to(torch.float))
print(" 3.1 torchaudio way Mel spectrogram: ", mel_out.shape)
# 使用 torchaudio 分解实现, melspectrogram;
from torchaudio import functional as F
n_fft = 20
win_length = 20
hop_length = 10
sample_rate = 16000
mel_len = 12
stft_len = n_fft//2+1
spec = torchaudio.transforms.Spectrogram(n_fft, win_length, hop_length)
spec_out = spec(torch.Tensor(a))
# 得到melscale的转换矩阵
tmp_fb = F.create_fb_matrix(stft_len, 0, sample_rate//2, mel_len, sample_rate)
mel_out1 = torch.matmul(spec_out.transpose(0,1), tmp_fb).transpose(0,1)
print(" 3.2 torchaudio way split step to generate Mel spectrogram: ", mel_out1.shape)
# --------------part 4 librosa Mel spectrogram -----------------
from torchaudio import functional as F
n_fft = 20
win_length = 20
hop_length = 10
sample_rate = 16000
mel_len = 12
stft_len = n_fft//2+1
tmp_fb = F.create_fb_matrix(stft_len, 0, sample_rate//2, mel_len, sample_rate)
def Spectrogram(input, n_fft, win_length, hop_length):
stft_librosa = librosa.stft(y=input,
hop_length=hop_length,
n_fft=n_fft)
spec_librosa = pow(np.abs(stft_librosa),2)
return spec_librosa
spec_librosa2 = Spectrogram(a, n_fft, win_length, hop_length)
mel_out2 = np.transpose(np.matmul(np.transpose( spec_librosa2),tmp_fb.numpy()))
print("4. librosa way to generate Mel spectrogram: ", mel_out2.shape)
2. 三种库的介绍
librosa、nnAudio、torchAudio三者的差异
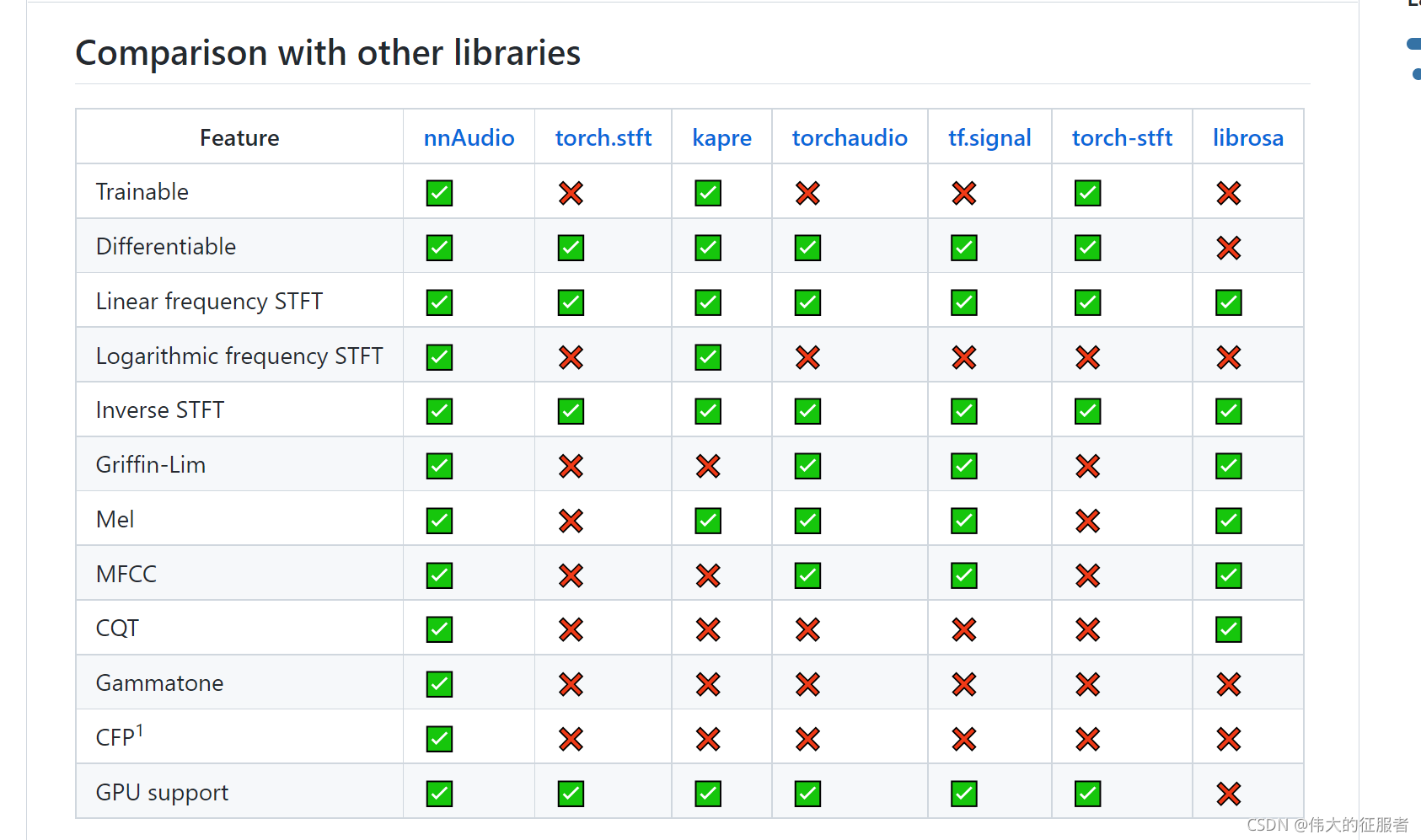
如果你只是使用pytorch, 需要关注nnAudio, torchAudio, librosa这三个模块,如上所示,nnAudio有很多优点,它是使用一维卷积实现的一个库,但是一些常用的功能,比如音频加载,谱图显示,幅度转为DB等它都没有,很多时候,还是要使用librosa配合。
from nnAudio import Spectrogram
import nnAudio
import torchaudio.functional as F
import torchaudio
import matplotlib.pyplot as plt
import torch
import librosa.display
import librosa.feature
import numpy as np
# 参数设置
N_fft = 2048
Hop_length = 128
def hz_to_mel(spectra):
'''
@描述:将谱图频率轴的刻度转为mel刻度
@算法思想:坐标替换
@输入:spectra -> 数据形式[F, T]
用到的mel公式: mel(f)=2595*log10(1+f/700)
@返回 numpy.float矩阵
'''
_spectra = np.array(spectra_from_librosa)
N_frequence = _spectra.shape[0] # 第一个维度是频率轴
F_axis = np.linspace(0,N_frequence-1, N_frequence)
F_axis = F_axis.astype('int')
mel_F_axis = 2595*np.log(1 + F_axis/700)
mel_F_axis = mel_F_axis/np.max(mel_F_axis)*N_frequence - 1 # 减 1 避免溢出
return_spectra = np.zeros_like(_spectra)
for i in range(len(F_axis)):
return_spectra[int(mel_F_axis[i])] = _spectra[i]
return return_spectra
# 语谱图实现,分别用librsoa、nnAudio、torchAudio实现
spectra_torchaudio_layer = torchaudio.transforms.Spectrogram(n_fft=N_fft, hop_length=Hop_length )
spectra_nnaudio_layer = nnAudio.Spectrogram.STFT(n_fft=N_fft, hop_length=Hop_length, fmax=32000,
output_format='Magnitude')
# mel谱图
melspectra_torchaudio_layer = torchaudio.transforms.MelSpectrogram(n_fft=N_fft, hop_length=Hop_length)
melspectra_nnaudio_layer = nnAudio.Spectrogram.MelSpectrogram(n_fft=N_fft, hop_length=Hop_length)
# 加载语音
wave_data, sr = torchaudio.load('八声杜鹃5_01.wav', channels_first=True)
# 提取梅尔谱图
melspectra_from_torchaudio = melspectra_torchaudio_layer(wave_data)
melspectra_from_nnaudio = melspectra_nnaudio_layer(wave_data)
melspectra_from_librosa = librosa.feature.melspectrogram(wave_data.numpy()[0,], sr=sr,
n_fft=N_fft, hop_length=Hop_length) # librosa不接受tensor类型数据
# 提取语谱图
spectra_from_nnaudio = spectra_nnaudio_layer(wave_data)
spectra_from_torchaudio = spectra_torchaudio_layer(wave_data)
spectra_from_librosa = librosa.stft(wave_data.numpy()[0,:], n_fft=N_fft, hop_length=Hop_length)
# 作图
plt.figure()
plt.subplot(3, 2,1)
plt.imshow(librosa.amplitude_to_db(melspectra_from_torchaudio.squeeze(0)), origin='lower')
plt.subplot(3,2,3)
plt.imshow(librosa.amplitude_to_db(melspectra_from_nnaudio.squeeze(0)), origin='lower')
plt.subplot(3,2,5)
plt.imshow(librosa.amplitude_to_db(melspectra_from_librosa), origin='lower')
plt.subplot(3, 2,2)
plt.imshow(librosa.amplitude_to_db(spectra_from_torchaudio.squeeze(0)), origin='lower')
plt.subplot(3,2,4)
plt.imshow(librosa.amplitude_to_db(spectra_from_nnaudio.squeeze(0)), origin='lower')
plt.subplot(3,2,6)
plt.imshow(librosa.amplitude_to_db(spectra_from_librosa), origin='lower')
# 坐标变为mel坐标
plt.figure()
mel_axis_spectra = hz_to_mel(spectra_from_librosa)
plt.imshow(librosa.amplitude_to_db(mel_axis_spectra), origin='lower')
# 利用librosa.displapy.specshow()作图
mel_inner_specta = librosa.hz_to_mel(spectra_from_librosa)
plt.figure()
plt.subplot(2,1,1)
librosa.display.specshow(librosa.amplitude_to_db(spectra_from_librosa), sr=sr,
hop_length=Hop_length, y_axis='mel')
plt.subplot(2,1,2)
librosa.display.specshow(librosa.amplitude_to_db(mel_inner_specta), sr=sr,
hop_length=Hop_length, y_axis='hz')

三个库分别实现梅尔谱图,谱图
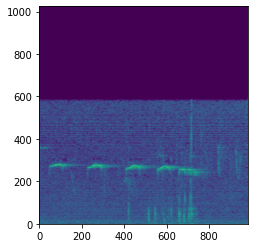
自定义函数将频率轴转为梅尔刻度

librosa.display.specshow()使用‘HZ’, 'mel’的对比
得出总结如下
1、三种方式实现的梅尔谱图使用的梅尔滤波器组数都是128, 所以它们最后的结果基本没有差异(图像上异值点会极大影响图像的显示)
2、短时傅里傅里叶变换后的谱图是线性,可以通过坐标替换的方式将它们的坐标替换为mel坐标
3、使用librosa.display.specshow()显示的谱图可以选择’mel’刻度显示,但是原始图像却是线性的
4、如果使用谱图训练神经网络,要用plt.imshow()显示图像,这样才是模型看到的图像
5、使用librosa.display.specshow()只是让人观察得容易一点而已。
https://github.com/KinWaiCheuk/nnAudio