文章目录
摘要
关键词
- 自动驾驶;
- 特征提取;
- 变分自编码器;
- 强化学习;
0 引言
2020年2月10日,中国科技部、工信部等11个部门联合印发《智能汽车创新发展战略》,提出到2025年,实现有条件自动驾驶的智能汽车达到规模化生产,实现高度自动驾驶的智能汽车在特定环境下市场化应用。
自动驾驶系统的3个模块:
| 模块 | 内容 |
|---|---|
| 感知 | 传感器 → \rightarrow → 周围环境和自身状态 |
| 决策 | 确定行驶路线和驾驶行为 |
| 控制 | 考虑车辆的物理限制,安全可靠执行决策命令 |
现有自动驾驶技术都是采用模块化方法
→ \rightarrow → 优点:可解释性强,大部分子任务基于明确规则的
→ \rightarrow → 缺点:系统复杂,开发维护成本高
基于神经网络的端到端自动驾驶系统 → \rightarrow → 将自动驾驶系统作为整体考虑 → \rightarrow → 从传感器信息到控制命令的映射
监督学习用于自动驾驶论述
- 前人研究
Bojarsky等人采用监督学习(supervised learning)的方式实现了端到端自动驾驶系统
输入:前置摄像头图像信息;
输出:最终的车辆转角控制命令;
arxiv: 1604. 07316
- 特点
- 为了训练具有鲁棒性的自动驾驶系统,训练数据需要覆盖尽量多的驾驶场景
- 学习的是给定环境中人类驾驶员的操作 → \rightarrow → 上限就是人类驾驶员的操作水平 → \rightarrow → 不会搜索更优的驾驶操作
强化学习用于自动驾驶的论述
1. 深度强化学习 + 自动驾驶 前人研究
| 学者 | 工作 | 效果 | 平台 |
|---|---|---|---|
| 刘偲 | DDPG用于自动驾驶 | 训练好的车辆可以沿给定车道线行驶 | 仿真 |
| 张斌 | 改进DDPG,重点关注过往失败的训练数据 | 训练效果提升 | Unknown |
| 王丙琛 | 预训练 + LSTM | 提升了车辆对未来状况的预判,训练时间大大缩短,系统稳定性得到提升 | 仿真 |
| 夏伟 | DQN + 实际驾驶员数据预训练 + 经验数据聚类采样 | 更少的数据,更高的训练效果 | 仿真 |
| 李志航 | Double DQN + LSTM | 比DDPG更好的效果 | 仿真 |
特点:低维传感器数据,并不包括来自前置摄像头的视觉图像信息
2. 基于视觉图像 + 深度强化学习 + 自动驾驶 前人研究
- Raffin → \rightarrow → 对高维图像数据进行特征提取 + 保留原始数据中的关键信息 + 降维后特征传入DDPG训练
- Kendall → \rightarrow → 变分自编码器提取信息 + 降维后特征传入DDPG训练 → \rightarrow → 30min训练
不足:没有考虑系统的泛化能力 → \rightarrow → 指在一种环境中训练的系统可以应用到其他明显不同的环境中
3. 本文改进
- 车道线提取环节
- 采用SAC(Soft Actor-Critic)强化学习算法
1 自动驾驶系统设计
1.1 系统整体架构
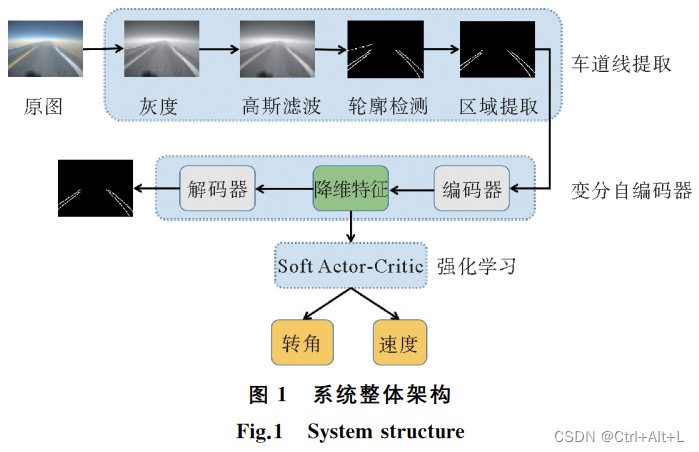
1.2 车道线提取
1. 采用Canny算法进行边缘轮廓线提取
Canny算法的基础是Sobel算子
OpenCV - 视觉分析处理
RGB转灰度图 → \rightarrow → 损失信息不妨碍图线提取,加速后续图像的处理
灰度值转换公式:
G R A Y = 0.30 R + 0.59 G + 0.11 B GRAY = 0.30R + 0.59G + 0.11B GRAY=0.30R+0.59G+0.11B
2. 采用高斯模糊降低噪声影响
用一个权重矩阵 ω \omega ω 做卷积

3. 二值化处理
本文:较小的阈值 T h 1 Th_{1} Th1=150,较大的阈值 T h 2 Th_{2} Th2=200
4. 掩膜处理
影响车辆行驶的仅仅是车辆前方的部分区域
较高的天空以及远处的事物看作是背景噪声
5. 得到结果

1.3 基于变分自编码器的图像特征降维
本文采用变分自编码器完成降维
变分自编码器是一种非线性的编码器,借助神经网络强大的函数映射能力
特点:
(1)输入的图像数据转换成低维数据,并且保留关键特征信息;
(2)从低维数据几乎可以重建原始数据;
(3)变分自编码器包括编码器和解码器两部分,如果用于数据降维,则只需要编码器部分
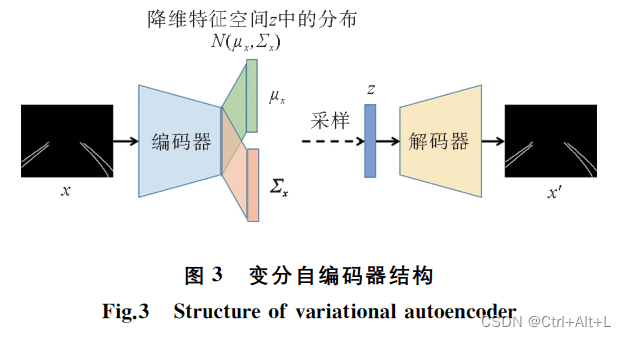
操作步骤
- 输入车道线提取图像,记作 x x x;
- 编码器部分通过卷积层将图像映射到低维特征空间 Z Z Z中,一般为低维向量空间;不直接映射到低维向量空间,而是先生成一个分布在采样。 N ( μ x , Σ x ) N(\mu_{x},\Sigma_{x}) N(μx,Σx)。 μ x \mu_{x} μx是均值, Σ x \Sigma_{x} Σx是协方差矩阵。生成的分布信息是低维向量维度的两倍。
- 对分布采样得到一个向量 z z z;
- 采样向量 z z z通过解码器(转置卷积上采样网络)生成图像 x ′ x^{\prime} x′;
- 调节编码器和解码器网络参数,最小化图像重构误差,同时要求分布 N ( μ x , Σ x ) N(\mu_{x},\Sigma_{x}) N(μx,Σx)尽量接近正态分布。
寻找一个满足优化指标的概率分布函数
编码之后的低维特征空间具有很好的编码分布结构:当输入图像外观稍微变化时,对应的低维特征分布也会有微小改变,即编码具有连续性
1.4 SAC强化学习算法
- 智能体 → \rightarrow → 自动驾驶策略
- 动作 → \rightarrow → 车辆速度和转向角
- 环境 → \rightarrow → 车辆所处的道路交通环境
- 状态 → \rightarrow → 当前时刻车道线图像 x x x对应的降维特征 N ( μ x , Σ x ) N(\mu_{x},\Sigma_{x}) N(μx,Σx)
SAC:off-policy 算法,旧策略下产生的数据进行训练,提高了采样数据的利用效率。
SAC搜索的是策略分布,而不是唯一的最优策略,搜索范围更广,不易过早陷入局部最优。

2 实验分析
2.1 实验平台
Donkey Car仿真平台
编程环境python 2.7,深度学习框架Tensorflow,深度强化学习框架Stable Baselines
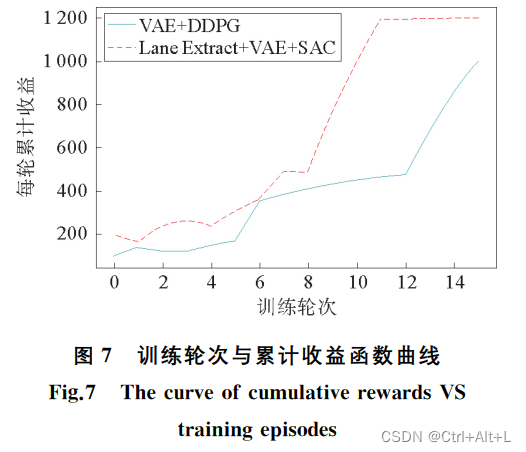
仿真实验的目的是:证明本文设计的基于特征提取的自动驾驶系统训练时间更短,在不同测试环境中的泛化能力更强。
沙漠场景用于训练,草地场景用于测试
2.2 训练步骤
(1)数据采集
为了训练变分自编码器
(2)车道线提取
直接调用Opencv中的相关函数即可
(3)训练变分自编码器
输入变分自编码器模型中进行无监督训练
4个卷积层和1个全连接层
得到32维的均值向量和32维的协方差矩阵向量
(4)SAC强化学习
基于这些框架,研究人员不必“重复造轮子”,只需要调用框架内的函数即可实现特定的强化学习算法。
奖励函数设置
| 条件 | 数值 |
|---|---|
| 车辆保持在车道线内 | 1 |
| 与当前速度成正比的奖励项 | β t = 0.1 × v t v m a x \beta_{t}=0.1\times \frac{v_{t}}{v_{max}} βt=0.1×vmaxvt |
| 驶出车道线 | -10 |
| 车道线时的与当前速度成正比的奖励项 | δ t = − 5 × v t − v m i n v m a x − v m i n \delta_{t}=-5\times \frac{v_{t}-v_{min}}{v_{max}-v_{min}} δt=−5×vmax−vminvt−vmin |
| 在车道线内的奖励 | r t = α t + β t r_{t}=\alpha_{t}+\beta_{t} rt=αt+βt |
| 在车道线外的奖励 | r t = γ t + δ t r_{t}=\gamma_{t}+\delta_{t} rt=γt+δt |
单步奖励基础上的累计奖励: R t = ∑ τ = 0 t r t R_{t} = \sum_{\tau=0}^{t}r_{t} Rt=∑τ=0trt
2.3 训练效果分析