目录
Data-Dependent Mixture Modeling
论文地址:Learning How to Ask: Querying LMs with Mixtures of Soft Prompts - ACL Anthology https://aclanthology.org/2021.naacl-main.410/
https://aclanthology.org/2021.naacl-main.410/
Abstract
自然语言提示用于引导预训练语言模型执行其他得AI任务。本文通过梯度下降探索来学习提示得idea,从先前的工作获取提示或者随机初始化提示。我们的提示还包括软提示,即不一定是来自语言模型中的单词类型嵌入的连续向量。此外,对于每个任务,我们优化了混合的提示,学习哪些提示最有效,以及如何集成它们。在多个英语l语言模型和任务中,我们的方法大大优于以前的方法,这表明语言模型中的隐含的事实知识以前被低估了。此外,获得这些知识也很容易被引导:随机初始化几乎和有根据的初始化一样好。
Introduction
Petroni et al. (2019)人工创建提示模板,Jiang et al. (2020)使用挖掘和复述的方法自动的增强提示集。神经语言模型将提示视为一连串的连续词向量(Baroni et al., 2014)。我们在连续的空间中对提示进行调优。宽松了提示向量必须是由实际的词向量构成的约束。允许由软提示中包含软词不仅方便优化,而且更具有表现力。软提示可以强调特定的单词或者这些单词的特定维度。他们还可以调整具有误导性、模棱两可或过于具体的词语。
Related Work
通常使用NLP工具从大型语料库中抽取实体、实体链接和关系。最近的工作表明仅仅从语料库中抽取语言方面的知识是不够的,还需要事实知识,常识,推理,总结,甚至是算数运算。以前的大部分工作都是手动创建提示,从训练过的语言模型中提取答案。我们使用LAMA(Petroni et al., 2019)作为基线,LM Prompt And Query Archive(LPAQA, Jiang et al., 2020)通过挖掘和复述的方法搜索新的提示,AutoPrompt(Shin et al., 2020)使用梯度搜索新的离散提示模板。我们将我们的新软提示与所有这些系统进行比较。
Li and Liang (2021)通过预训练语言模型生成文本,他们使用了为每种不同的任务添加了不同的软token提示并且仅仅对这些token进行调优。Liu et al., (2021)采用了和我们相似的策略,他们使用了完形填空式的提示在一个连续的向量空间中,尽管没有使用深度提示调优,但是和本文一样都取得了不错的效果。
Bouraoui et al. (2020)从语料库中挖掘提示然后微调整个模型,以便可以更加精准的补全提示模板。Schick and Schütze (2020a,b)使用了相似的方法,但是针对每个提示对语言模型的微调方式不同,我们的方法通过微调提示本身实现。
Method
我们的实验将旨在从语言模型中抽取关系知识。对于给出的一个固定的预训练语言模型和一个特定的关系对(x,y)以及包含关系的数据集。我们训练系统从数据集中根据x找出y,并对(x,y)进行评估。

Soft Prompts
假设语言模型通过向量来识别词类型,我们也允许提示是一个软提示,可以是任意数目的token。我们可以根据硬提示来初始化这些向量。硬提示中的每个token可以是一个词、子词、或者是标点符号,然后就可以进行连续的向量调优了。我们不改变向量的数量和位置,从下面的模板来看,我们拥有了一个6维的搜索空间。
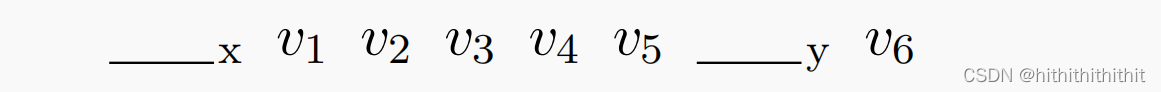
Deeply Perturbed Prompts
对于提示中的每个token i,向量i会进行到模型中参与提示以此补全模板。在Transformer架构中,依次计算深层的上下文token嵌入,,其中
,l层的向量由l-1层以及之前层的向量参与计算。
在进一步计算之前,我们可以通过对每个添加额外的扰动
这个扰动在对于给定的硬提示符下被初始化为0,然后进行调优。仅在第0层扰动相当于直接对
进行调优。如果在所有层进行扰动,那么我们可以有6d*(L+1)个参数对6个token prompt进行调整。通过提前终止和其他形式的正则化可以保持一个较小的扰动值。因为作者认为小的扰动可以产生更熟悉的激活模式。Li and Liang (2021)尝试了另一种不同的方法在防止在调优所有层时产生过拟合的现象。
Mixture Modeling
对于给定的针对关系的软提示集合
,我们可以定义集成预测分布:
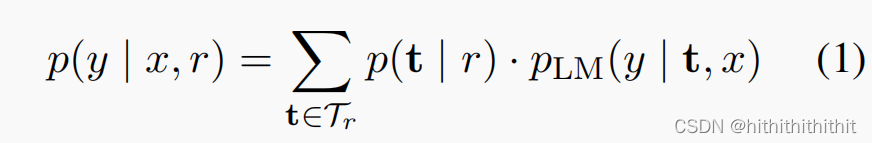
Data-Dependent Mixture Modeling
作为扩展,我们使用了去代替上式中的
,这样可以使模型在选择提示的时候把
考虑进去。例如,复数名词
可能更喜欢使用复数动词的提示
。
虽然我们可以直接的创建一个神经softmax模型用于,但是如果x位置处的x是可信的参数时,提示t可能会工作得更好。因此,我们使用使用贝叶斯理论去重写
为
,其中
用于表示上述直觉的强度。