一、RTOS
很多STM32单片机初学者都是从裸机开始的,裸机确实也能开发出好的产品。但是,作为一个嵌入式软件工程师,况且用的并不是51那种低端单片机,如果只会用裸机开发产品,那肯定是不够的。
要从裸机的思维转变到RTOS(Real Time Operating System)的思维,其实需要一个过程,而且开始的一段时间会很痛苦。但过一段时间理解了一些内容,能写一些Demo之后,你会发现其实RTOS也不难。
现在FreeRTOS在CubeMX工具中可以直接配置并使用,相当方便
为什么需要RTOS
为什么我们需要RTOS?就像最开始学C编程时,老师告诉我们,指针很重要,那时你肯定有一个大的疑问,指针到底有什么好?
心里一直犯嘀咕着:不用指针不一样把程序编出来了? 现在想想看C语言没了指针,是不是“寸步难行”呢?
回到正题,我们到底为什么需要RTOS?。
一般的简单的嵌入式设备的编程思路是下面这样的:

这是最常见的一种思路,对于简单的系统当然是够用了,但这样的系统实时性很差。
比如“事务1”如果是一个用户输入的检测,当用户输入时,如果程序正在处理事务1下面的那些事务,那么这次用户输入将失效,用户的体验是“这个按键不灵敏,这个机器很慢”,而我们如果把事务放到中断里去处理,虽然改善了实时性但会导致另外一个问题,有可能会引发中断丢失,这个后果有时候比“慢一点”更加严重和恶劣!
又比如事务2是一个只需要1s钟处理一次的任务,那么显然事务2会白白浪费CPU的时间。
改进思路
看到上面裸机开发的局限了吗? whaosoft aiot http://143ai.com
这时,我们可能需要改进我们的编程思路,一般我们会尝试采用“时间片”的方式。这时候编程会变成下面的方式:

可以看到,这种改进后的思路,使得事务的执行时间得到控制,事务只在自己的时间片到来后,才会去执行。但这种方式仍然不能彻底解决“实时性”的问题,因为某个事务的时间片到来后,也不能立即就执行,必须等到当前事务的时间片用完,并且后面的事务时间片没到来,才有机会获得“执行时间”。
这时候我们需要继续改进思路,为了使得某个事务的时间片到来后能立即执行,我们需要在时钟中断里判断完时间片后,改变程序的返回位置,让程序不返回到刚刚被打断的位置,而从最新获得了时间片的事务处开始执行,这样就彻底解决了事务的实时问题。
我们在这个思路上,进行改进,我们需要在每次进入时钟中断前,保存CPU的当前状态和当前事务用到的一些数据,然后我们进入时钟中断进行时间片处理,若发现有新的更紧急的事务的时间片到来了,则我们改变中断的返回的地址,并在CPU中恢复这个更紧急的事务的现场,然后返回中断开始执行这个更紧急的事务。
使用RTOS的好处
上面那段话,对于初学者来说,可能有些不好理解。
事实上,这是因为要实现这个过程是有些复杂和麻烦的,这时候我们就需要找一个操作系统(OS)帮我们做这些事了,如果你能自己用代码实现这个过程,事实上你就在自己写操作系统了。
其实从这里也可也看出,操作系统的原理其实并不那么神秘,只是一些细节你很难做好。我们常见的RTOS基本都是这样的一个操作系统,它能帮你完成这些事情,而且是很优雅的帮你完成!
事实上,RTOS的用处远不止帮你完成这个“事务时间片的处理”,它还能帮你处理各种超时,进行内存管理,完成任务间的通信等。
有了RTOS,程序的层次也更加清晰,给系统添加功能也更方便,这一切在大型项目中越发的明显!
二、PID算法
了解了很浅的原理后,结果公式看不懂,不懂含义,所以最终没有透彻。我这里先对公式进行剖析,公式理解明白了,结合网上的一些PID讲述的例子,就明白了。
先对PID这三个系数的含义进行简单扫盲。同时也防止自己遗忘。P是比例系数,I是积分系数、D是微分系数。
下面对PID这三个系数进行详细说明。
比例系数P
比例系数P是干什么用,其实如果现在你是初中生的话,你一下子就懂了,比例系数就是用在穿过(0,0)这个坐标点直线的放大倍数k,k越大,直线的斜率越大,所以是用在y = k * x中的,其中的k就是比例系数p,大家都简称为kp,所以就变成了y = Kp * x。
x就是当前值currentValue和目标值totalValue的差值,简称误差err,则err = currentValue - totalValue。y就是执行器对应的输出值U,所以执行器对应的输出值U = Kp * ( currentValue - totalValue ) 。
所以,如果说是使用比例进行调节。
则当前第1次调节时执行器对应的输出值为:
U1 = Kp * ( curentValue1 - totalValue1 )
第2次调节时执行器对应的输出值为:
U2 = Kp * ( currentValue2 - totalValue2 )
这就是比例系数P的应用,也就是大家说的比例调节。比例调节就是根据当前的值与目标值的差值,乘以了一个Kp的系数,来得到一个输出值,这输出值直接影响了下次当前值的变化。如果只有比例调节的话,系统会震荡的比较厉害。比如你的汽车现在运行的速度是60km/h,现在你想通过你的执行器去控制这个汽车达到恒定的50km/h,如果你只用kp进行比例调节话。U = Kp * ( 60 - 50 ),假设Kp取值为1,此时得到U执行器的输出值是10,结果当你执行器输出后,发现汽车一下变成了35Km/h,此时U2 = Kp * (35 - 50),此时得到U执行器的输出值是-15,结果当你执行器输出后,发现汽车变成了55Km/h,由于惯性和不可预知的误差因素,你的汽车始终无法达到恒定的50km/h。始终在晃动,相信如果你在车上,你一定吐的很厉害。所以光有比例系数进行调节,在有些场合是没有办法将系统调稳定的。所以可以为了减缓震荡的厉害,则会结合使用比例P和微分D。
微分系数D
微分,实际上是对误差进行微分。加入误差1是err(1)。误差2是err(2)。则误差err的微分是 (err2 - err1)。乘上微分系数D,大家叫做KD,则当执行器第1次调节后有了第1次的误差,第2次调节后有了第2次的误差,则结合P系数。就有了PD结合,根据每次调节时,误差的值的经验推算,你就能选取出D的系数。假如误差是越来越小的,那么微分后肯定是一个负值。负值在乘以了一个D系数 加上了比例调节的值后肯定值要比单纯使用比例调节的值要小,所以就启到了阻尼的作用。有了阻尼的作用就会使得系统区域稳定。
PD结合的公式经过上面的分析后为:
U(t) = Kp * err(t) + Kd * derr(t)/dt
积分系数I
积分,实际上是对误差的积分,也就是误差的无限和。如何理解积分系数I,这里引用网上的例子
以热水为例。假如有个人把我们的加热装置带到了非常冷的地方,开始烧水了。需要烧到50℃。
在P的作用下,水温慢慢升高。直到升高到45℃时,他发现了一个不好的事情:天气太冷,水散热的速度,和P控制的加热的速度相等了。
这可怎么办?
P兄这样想:我和目标已经很近了,只需要轻轻加热就可以了。
D兄这样想:加热和散热相等,温度没有波动,我好像不用调整什么。
于是,水温永远地停留在45℃,永远到不了50℃。
根据常识,我们知道,应该进一步增加加热的功率。可是增加多少该如何计算呢?
前辈科学家们想到的方法是真的巧妙。
设置一个积分量。只要偏差存在,就不断地对偏差进行积分(累加),并反应在调节力度上。
这样一来,即使45℃和50℃相差不太大,但是随着时间的推移,只要没达到目标温度,这个积分量就不断增加。系统就会慢慢意识到:还没有到达目标温度,该增加功率啦!
到了目标温度后,假设温度没有波动,积分值就不会再变动。这时,加热功率仍然等于散热功率。但是,温度是稳稳的50℃。
kI的值越大,积分时乘的系数就越大,积分效果越明显。
所以,I的作用就是,减小静态情况下的误差,让受控物理量尽可能接近目标值。
I在使用时还有个问题:需要设定积分限制。防止在刚开始加热时,就把积分量积得太大,难以控制。
三、理解C语言指针
计算机中所有的数据都必须放在内存中,不同类型的数据占用的字节数不一样,例如 int 占用4个字节,char 占用1个字节。为了正确地访问这些数据,必须为每个字节都编上号码,就像门牌号、身份证号一样,每个字节的编号是唯一的,根据编号可以准确地找到某个字节。
下图是 4G 内存中每个字节的编号(以十六进制表示):

我们将内存中字节的编号称为地址(Address)或指针(Pointer)。地址从 0 开始依次增加,对于 32 位环境,程序能够使用的内存为 4GB,最小的地址为 0,最大的地址为 0XFFFFFFFF。
下面的代码演示了如何输出一个地址:
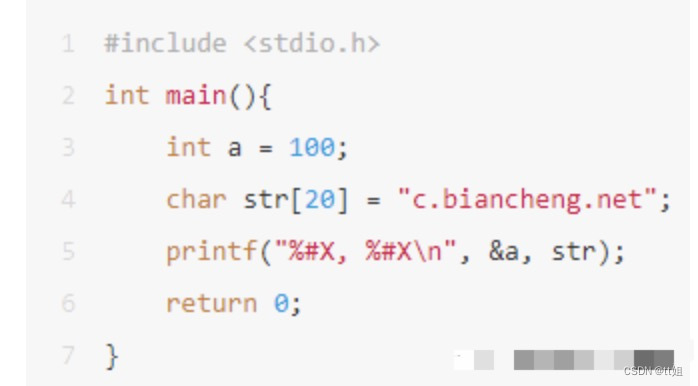
运行结果:
0X28FF3C, 0X28FF10%#X表示以十六进制形式输出,并附带前缀0X。a 是一个变量,用来存放整数,需要在前面加&来获得它的地址;str 本身就表示字符串的首地址,不需要加&。
一切都是地址
C语言用变量来存储数据,用函数来定义一段可以重复使用的代码,它们最终都要放到内存中才能供 CPU 使用。
数据和代码都以二进制的形式存储在内存中,计算机无法从格式上区分某块内存到底存储的是数据还是代码。当程序被加载到内存后,操作系统会给不同的内存块指定不同的权限,拥有读取和执行权限的内存块就是代码,而拥有读取和写入权限(也可能只有读取权限)的内存块就是数据。
CPU 只能通过地址来取得内存中的代码和数据,程序在执行过程中会告知 CPU 要执行的代码以及要读写的数据的地址。如果程序不小心出错,或者开发者有意为之,在 CPU 要写入数据时给它一个代码区域的地址,就会发生内存访问错误。这种内存访问错误会被硬件和操作系统拦截,强制程序崩溃,程序员没有挽救的机会。
CPU 访问内存时需要的是地址,而不是变量名和函数名!变量名和函数名只是地址的一种助记符,当源文件被编译和链接成可执行程序后,它们都会被替换成地址。编译和链接过程的一项重要任务就是找到这些名称所对应的地址。
假设变量 a、b、c 在内存中的地址分别是 0X1000、0X2000、0X3000,那么加法运算c = a + b;将会被转换成类似下面的形式:
0X3000 = (0X1000) + (0X2000);( )表示取值操作,整个表达式的意思是,取出地址 0X1000 和 0X2000 上的值,将它们相加,把相加的结果赋值给地址为 0X3000 的内存。
变量名和函数名为我们提供了方便,让我们在编写代码的过程中可以使用易于阅读和理解的英文字符串,不用直接面对二进制地址,那场景简直让人崩溃。
需要注意的是,虽然变量名、函数名、字符串名和数组名在本质上是一样的,它们都是地址的助记符,但在编写代码的过程中,我们认为变量名表示的是数据本身,而函数名、字符串名和数组名表示的是代码块或数据块的首地址。
四、go和c语言通信
golang并没有类似ntohl()、htonl()等函数, 但是提供了binary.BigEndian binary.LittleEndian等模式
网络二进制数据转换: 总所周知,数据在tcp网络传输协议中传输的字节序是大端模式的,换句话说如果你要传输一个int32型的整数,那么假设其二进制小端模式表示为11111111111111110000000000000000那么其大端模式表示为00000000000000001111111111111111,利用c语言的htonl函数会将数据字节序转换成大端模式,在网络上面传输,接收端想解出原始数据只需要认为发送来的数据是大端模式,按照大端模式表示的数据解析便可 举个例子: 在C语言端发送一个int32_t数据过程如下: 发送端(c语言)
char buf[100]; int32_t x = 100; ((int*)buf)[0] = htonl(x); send(clientfd, buf, 100, 0);
接收端(golang)
var num int32
buffer := make([]byte, 4)
length, err := conn.Read(buffer)
if err != nil {
return
}
buf := bytes.NewReader(buffer)
err = binary.Read(buf, binary.BigEndian, &num)