文章目录
前言
今天继续分享一个c语言的小知识点,如何判断当前机器栈增长的方向。
test dmeo1
测试环境:
Intel x86_64
vmware + ubuntu20.04
gcc version 9.4.0
我们都知道局部变量是存在栈中的,我们可以定义两个局部变量,先定义变量的先入栈,然后比较他们的地址就可以知道栈增长的结果了。代码如下:
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
if(&a > &b){
printf("a_address = %p > b_address = %p : stack grow down \n", &a, &b);
}else{
printf("a_address = %p < b_address = %p : stack grow up \n", &a, &b);
}
return 0;
}
这样判断可以吗?让我们看看结果:

由结果可知,显然不能这样判断,因为x86_64栈是向低地址增长的,显然有误。
分析一下原因,我们先来看看一个函数中定义两个局部变量的反汇编代码:
int main()
{
int a = 1;
int b = 2;
return 0;
}
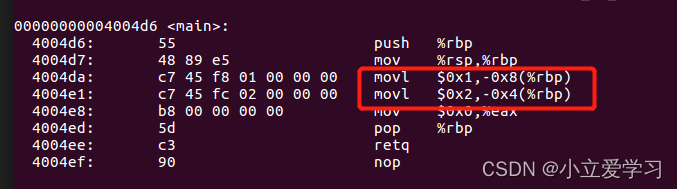
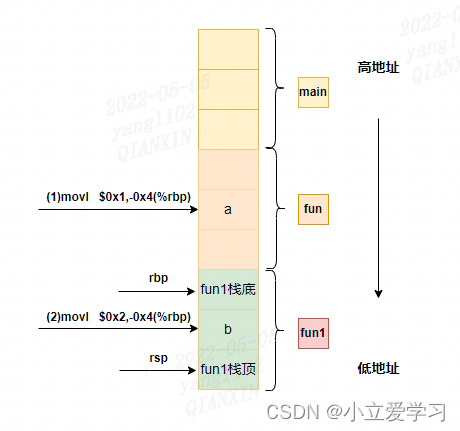
从汇编代码中我们可以看出 0x1(a)是在低地址中, 0x2(b)是在高地址中,如图所示:
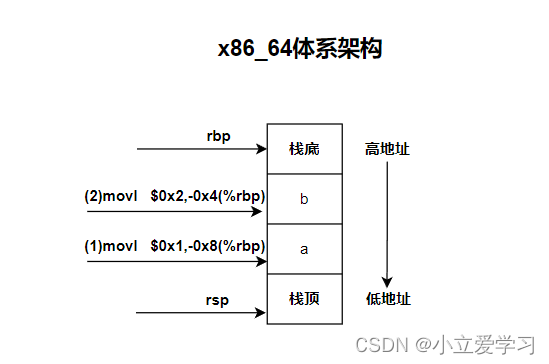
通过两条mov指令将立即数1,2写入栈内存中,而不是按照入栈先进后出的顺序将a(1),b(2)写入到栈中。所以很明显不能用这种方法判断。
所以我们得出一个结论:我们千万不能假设一个函数内的局部变量先定义的先入栈,这与编译器的实现有关,为了让我们判断栈增长的方向具有可移植性,肯定不能用上述方法判断。
有的同学可能就想到另一个方法,一个函数的输入参数肯定比局部变量先入栈,我么可以通过判断一个函数内参数的地址和局部变量的地址来判断栈增长的方向。其实这种方法也不具有可移植性,这个也依赖于编译器。
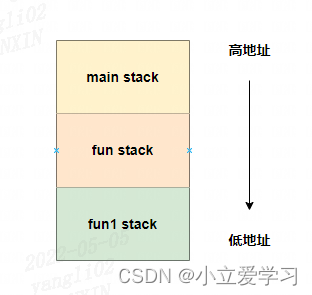
那我们又换一个方法:函数之间调用,先调用的函数信息肯定先入栈,后调用的函数其信息后入栈。
简略代码如下:
fun1()
{
}
fun()
{
fun1();
}
main()
{
fun();
}
调用栈示意图:
test dmeo2
现在我们给出一个测试栈增长方向正确的示意代码:
注意编译时不要加优化等级 O2 或 O3之类的,不然会优化成内联函数,这样有可能又变成一个函数内局部变量之间的比较了,会影响结果。
#include <stdio.h>
void fun1(int *a)
{
int b = 2;
if(a > &b){
printf("a_address = %p > b_address = %p : stack grow down \n", a, &b);
}else{
printf("a_address = %p < b_address = %p : stack grow up \n", a, &b);
}
}
void fun()
{
int a = 1;
fun1(&a);
}
int main()
{
fun();
return 0;
}

从结果可知当前栈的方向是向低地址增长的。
我们继续看其反汇编代码:
#include <stdio.h>
void fun1()
{
int b = 2;
}
void fun()
{
int a = 1;
fun1();
}
int main()
{
fun();
return 0;
}
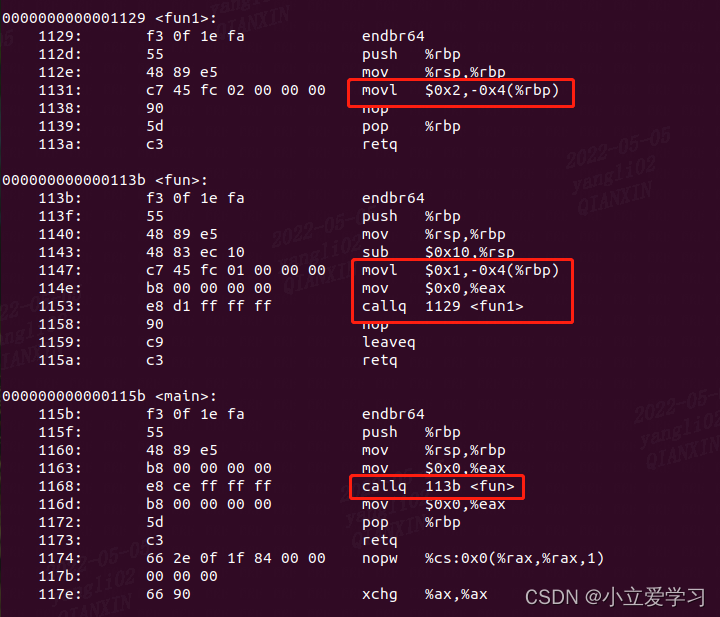
如下图所示:
总结
一个函数内的局部变量,参数在当前函数的栈帧中的顺序由编译器决定的,这些信息都位于一个栈帧中,我们无法确定所有机器其入栈的先后顺序都是一样的,这样不具有可移植性。
但是多个函数之间调用,每个函数都有自己的栈帧,总是先调用函数的栈帧先入栈,后调用函数的栈帧后入栈。
参考资料
深入理解计算机系统
https://blog.csdn.net/changyourmind/article/details/51839395
https://mp.weixin.qq.com/s/33__rGbvEHUB7nXWPSvz8Q